

Лекция 13.
Методы классификации и идентификации. Распознавание образов.
В аналитической химии часто приходится решать задачи качественного анализа, т.е. по сути задачи отождествления исследуемого объекта с каким-либо заранее определенным классом.
Необходимо ввести ряд определений:
Класс - множество объектов, сходных по природе и признакам.
Классификация - процедура отнесения к тому или иному классу.
Идентификация - предельный случай классификации, когда класс состоит из одного объекта.
Аналитический признак - измеряемая величина, зависящая от природы объекта и по возможности не зависящая от количества объекта. Например, оптическая плотность раствора красителя - это аналитический сигнал (зависит от концентрации), а коэффициент поглощения на определенной длине волны - это аналитический признак (не зависит от концентрации).
Образ - совокупность признаков объекта.
Распознавание образов - синоним классификации.
Для наглядности объект можно представлять точкой в пространстве образов. Например, если в качестве аналитических признаков выбрать плотность и температуру кипения, то пространство образов будет являться плоскостью:

В данном случае видно, что одного признака (плотности или температуры кипения) не хватит, чтобы различить воду, никотин и бутанол-2.
Выбор признаков (и определение минимально необходимого для классификации количества признаков) является непростой задачей. Общие критерии такие: не использовать малоинформативные для данной задачи признаки и не использовать коррелирующие между собой признаки (например, содержание углерода и содержание водорода - для классификации углеводородов целесообразно использовать только один из этих признаков).
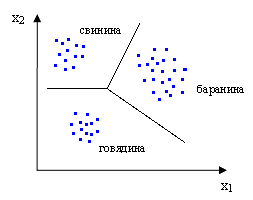
Обучающая выборка - множество образов объектов, охватывающее все классы. Например, поставлена задача классификации образца мяса. В качестве признаков выбраны содержания двух аминокислот x1 и x2. Для решения задачи классификации необходим набор образцов мяса известных сортов - обучающая выборка:

Это пример хорошего выбора признаков - в пространстве образов четко обозначены 3 кластера
Кластер - множество образов объектов одного класса.
В общем случае алгоритм распознавания образов включает два этапа: кластерный анализ и дискриминантый анализ.
Кластерный анализ - метод группировки образов в кластеры. В качестве примера можно привести метод дендрограмм. Этот метод заключается в том, что последовательно пара наиболее близких точек в пространстве образов заменяется одной точкой (центром тяжести). Процедура повторяется необходимое число раз, пока не остается несколько точек - центров кластеров.
Дискриминантный анализ - метод разделения кластеров.
Одна из разновидностей - линейный дискриминантый анализ, аппроксимирует границы между кластерами линейными функциями (которые довольно сложно вычисляются статистическими методами):
Однако, линейный дискриминантый анализ не работает, например, в таких случаях:

Другой метод - метод К ближайших соседей. Этот метод не дает границ в явном виде, но решает задачу отнесения. Задается число K (обычно от 3 до 10), затем для образа, который нужно распознать, находится K ближайших точек в пространстве образов, и класс неизвестного образа определяется "большинством голосов" - этот тот класс, которому принадлежит большинство ближайших точек. Существует модификация метода, в которой учитывается расстояния между точками.
Вообще, существует очень большое число алгоритмов классификации - начиная от К ближайших соседей до использования искусственных нейронных сетей. Как правило, методы сначала "тренируют" на обучающей выборке, а затем выбирают оптимальный вариант - дающий наибольший процент правильной классификации.
(назад)