

10.3. Система id3
Одним из первых индуктивных алгоритмов является алгоритм ID3. Программа работает следующим образом:
Выбрать наугад некоторое подмножество (окно) W из множества всех обучающих примеров.
Для текущего окна построить правило классификации.
Просмотреть полностью всю базу данных, а не только это окно, чтобы найти исключения для последнего из выработанных правил.
Если исключения обнаружены, то включить некоторые из таких примеров в окно и повторить шаги, начиная со второго; в противном случае прекратить работу и выдать полученное правило.
Хотя система ID3 не является слишком устойчивой, если допустить использование зашумленных данных, но в принципе это ограничение перестает быть существенным, если отказаться в ней от обязательного поиска «совершенного» правила. IDЗ генерирует правила следующим образом. Вначале он выбирает экземпляры карт (т.е. случаи, события, или исторические примеры), которые составляют множество, называемое окно. Окно совместно с алгоритмом обучения понятиям используется для генерирования правил.
Алгоритм классификации CLS циклически просматривает и разбивает обучающиеся примеры на классы в соответствии с переменной, имеющей наибольшую классифицирующую силу. Для этой цели используется теоретико-информационная мера — энтропия.
Каждое подмножество, выделяемое такой переменной с наибольшей классифицирующей силой, вновь разбивается на классы (пока в нем не будут содержаться данные лишь одного класса) с использованием следующей переменной с наибольшей классифицирующей способностью, и т. д. Разбиения заканчиваются, когда в подмножестве оказываются лишь однотипные данные. В ходе этого процесса образуется дерево решений.
Если правило может покрыть все множества примеров, оно является совершенным, в противном случае примеры, представляющие исключения, поочередно включаются в окно, чтобы улучшить текущее множество правил. Процедура повторяется до тех пор, пока не будет сформировано совершенное множество правил или, по крайней мере, правило не будет удовлетворять некоторому миниму критерия качества.
10.4. Система induce
INDUCE представляет собою структурно обучающуюся программу, в которой используется метод, известный как лучевой поиск. Метод заключается в следующем.
Пусть множество Н содержит наугад выбранное подмножество размером W множества обучающих примеров.
Обобщить каждый пример из Н в минимально возможной степени (т. е. проделать минимальные обобщения).
Отбросить неоправдавшиеся гипотезы в соответствии с их размером и аботоспособностью, т. е. сохранить те гипотезы, которые просты и хватывают много примеров, отбросив сложные и охватывающие ишь несколько случаев. В результате остаются только лучшие правила для W.
Если какое-то описание в Н охватывает все (или достаточное число) примеров, то выдать его на печать.
(Шаги со второго по четвертый повторяются до тех пор, пока либо Н не станет пустым, либо достаточное число понятий не поступит на печать.)
Этот метод оказывается достаточно помехоустойчивым и может быть использован в целом ряде задач.
Эффективность системы INDUCE целиком определяется адекватностью языка описания (аннотированное исчисление предикатов») и критерия качества работы, на основании которого принимается решение, какое правило следует сохранить, а какое отбросить. В общем случае этот критерий нельзя указать заранее. Пользователь должен его подбирать, поскольку в различных ситуациях по-разному складывается соотношение между сложностью и эффективностью правил.
Другим существенным для метода фактором является процедура обобщения. Вопрос этот непростой. Обозначим для некоторого признака (атрибута) ИAi значение соответствующего признака ИЗi, запись ИАi = ИЗi означает « значение атрибута с именем ИАi равно ИЗi.
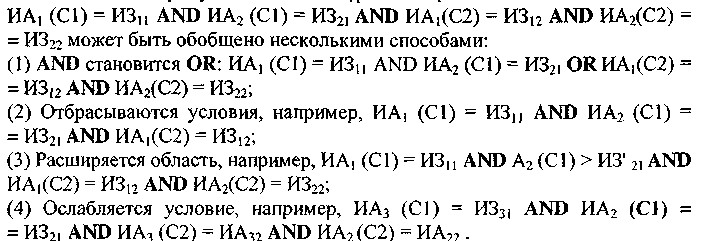
Каждый метод обобщения может быть применен несколькими способами. Например, AND может быть заменено на OR семью способами (каждое условие, каждая пара и все три). Это число вариантов можно уменьшить, если принять, что за один раз можно делать лишь одно изменение. И даже при этом число возможных одиночных изменений, которые нужно рассмотреть на каждом шаге в реальных задачах, очень велико, а если отбрасывается слишком много вариантов, то может случиться так, что оптимальное правило так никогда и не будет найдено.
Чтобы оставаться в рамках разумного, на практике необходимо привлекать и другие ограничения, например рассматривать только правила определенной синтаксической формы.
Алгоритм обучения понятием конструирует дерево решений, используя подход «сверху вниз», «разделяй и властвуй». Деревья решений, полученные в алгоритме ID3, хорошо себя проявили в условиях лишь небольшого шума. При сильно зашумленных данных деревья решений начинают сильно ветвиться, чтобы хорошо описать обучающие последовательности, но при этом затрудняется их модификация при поступлении новых примеров. Другое ограничение, присущее системе ID3, состоит в том, что в ней используются векторы признаков для описания данных (хотя и не для описания правил).
Более серьезный недостаток системы обусловлен бедностью используемого языка описаний. Правила в ней представляют собой деревья решений конкретного вида, в которых каждая вершина является тестом, дающим, как правило, две ветви, в зависимости от результата. А чтобы общий объем поиска оставался в разумных пределах, необходимо, чтобы каждый тест представлял собой просто сравнение переменной с константой, например «прибыль >10%». Столь простые тесты, однако, исключают применение составных проверок любого типа, в которых использовались бы логические или арифметические операции. Невозможно даже производить сравнение одной переменной с другой, что является очень серьезным ограничением. Перечисленные ограничения системы взваливают на плечи пользователя задачу выработки очень эффективного множества переменных, описывающих рассматриваемую ситуацию, в которые уже включены все необходимые предварительные вычислений.
Главной проблемой логических методов обнаружения закономерностей является проблема перебора вариантов за приемлемое время. Известные методы либо искусственно ограничивают такой перебор (алгоритмы КОРА, WizWhy), либо строят деревья решений (алгоритмы CART, CHAID, ID3, See5, Sipina и др.), дающие полезные результаты только в случае независимых признаков.
Другие проблемы связаны с тем, что известные методы поиска логических правил не поддерживают функцию обобщения найденных правил и функцию поиска оптимальной композиции таких правил. Вместе с тем, указанные функции являются весьма существенными для построения баз знаний, требующих умения вводить понятия, метапонятия и семантические отношения на основе множества фрагментов знаний о предметной области.
Вышесказанное подтверждает актуальность разработки новых подходов и алгоритмов Data Mining в классе IF ... THEN правил. Основными требованиями к новым подходам являются:
способность находить логические правила неограниченной сложности в данных высокой размерности;
умение обобщать найденные логические правила и осуществлять поиск их оптимальной композиции.
Опыт решения задач обучения машин свидетельствует о том, что основная «различающая» информация заключена не в отдельных атрибутах, а в их различных сочетаниях. Однако вычислительная сложность известных алгоритмов этого класса, таких как «КОРА» заставила ограничиваться конъюнкциями сложности три.
Рассмотрим пример применения алгоритма ID3 и прогнозирования курса ценных бумаг с использованием примитивных образов. Предположим, что поведение графика, представляющего данные о рынке ценных бумаг, может быть охарактеризовано с помощью двух графов, называемых чарт 1 и чарт 2, каждому из которых можно присвоить значение двух видов атрибутов и скалярную меру. Эти графы можно комбинировать со столбцом заключения об изменении цены. Атрибутами чарта 1 и 2 являются графические образы, а их численные значения представлены в столбце «Курс» таблицы экземпляра базы данных (таблица 10.1).
Наблюдаемые изменения курса для каждого экземпляра делятся на три класса (рис. 10.4):
up (рост), down (спад) или sustained (стабильность). Из этих экземпляров алгоритм обучения понятиям вначале выбирает атрибуты, которые имеют наивысшую различительную силу, По отношению к изменению цен. В данном примере чарт 1 имеет наивысшую различительную силу, так что он помещается в вершину классифицирующего дерева. Реализация паттерна 1В в чарте 1 обеспечивает достаточные свидетельства для того, чтобы сделать заключение, что значение атрибута курс принадлежит к классу «стабильно», паттерн 1 А, однако, требует дополнительной информации от чарта 2, чтобы сделать определенное заключение, а паттерн 1С требует для заключения информацию от атрибута «курс». Этот процесс продолжится до тех пор, пока не будет никаких неоднозначных заключений. Чтобы измерить различительную силу в ID3 используется следующая мера энтропии: Entropy =

Например,
предположим, что число образов в чарте
1 для трех классов будет![]() .
Тогда энтропия для чарта1 становится
равной нулю, поскольку чарт 1 может
классифицировать эти экземпляры без
неопределенности. Другой краткий случай
будет иметь место, когда
.
Тогда энтропия для чарта1 становится
равной нулю, поскольку чарт 1 может
классифицировать эти экземпляры без
неопределенности. Другой краткий случай
будет иметь место, когда
![]() Теперь
чарт 1 не имеет дискриминирующей
силы, поэтому его энтропия равна 1.
Когда
Теперь
чарт 1 не имеет дискриминирующей
силы, поэтому его энтропия равна 1.
Когда![]() и
Nsustained
=
0 значение энтропии равно 0,579. Таким
образом, степень однородности
экземпляров в классе может служить
основой для определения меры
пригодности правил. Дерево решений,
генерируемое алгоритмом обучения
понятиям, может быть преобразовано в
правила решений. Извлеченные ID3
правила
могут иметь следующий вид:
и
Nsustained
=
0 значение энтропии равно 0,579. Таким
образом, степень однородности
экземпляров в классе может служить
основой для определения меры
пригодности правил. Дерево решений,
генерируемое алгоритмом обучения
понятиям, может быть преобразовано в
правила решений. Извлеченные ID3
правила
могут иметь следующий вид:

В целом ряде исследований был использован метод ID3 для того, чтобы попытаться предсказать движение акций рынка товарной биржи, при этом могут использоваться индикаторы, примеры которых представлены ниже.
Put-call ratio, Chicago Board of Options Exchange (PCCBOE)
Put-call ratio, American Options Exchange (PCAMEX)
Granville Cumulative climax Indicator (GCCI), non confirmation Cumulative climax
GCCI, refrogress (GRANET)
GCCI trend GRANTREN)
Weinstein Last Hour activity, volume NYSE index nonconfirmation:
Dow Jones moving average 10-day cycle (DJ10)
Wycoff Wave, nonconfirmation (WWREV).
Множество правил, сформированных на основании данных, собираемых в конце недели в пятницу при закрытии рынка, дают правильное предсказание на протяжении 64,4% времени. Тремя классами, которые используются при этом, являются предсказания тренда роста, предсказание тренда падения и неизменного курса.
Результаты такой классификации могут быть использованы, чтобы обеспечить инвесторов с умеренным риском и агрессивных инвесторов еженедельными рекомендациями. Контроль осуществляется путем сравнения с рекомендациями аналитика, который интерпретировал те же самые данные. При практической проверке описываемого метода использовались восемь атрибутов: 25-, 75-, и 150-дневные подвижные средние цен на акции, 6- и 25-дневные подвижные средние объемов торгов, кривые корреляции цена/объем, относительный объем и психологическая линия. Правила, используемые для оценки характеристик были сгенерированы алгоритмом обучения понятиям. В данном случае использовались 18 атрибутов, чтобы классифицировать акции на указанные классы. Индуктивно сформированные правила дали результаты, превосходящие, т.е. которые были получены экспертом-аналитиком по техническому анализу, использовавшему NYSE и S&P500 индексы при оценке ожидаемого годового дохода.
Чтобы выделить те ценные бумаги, которые согласно NYSE могут, вполне вероятно, возрасти в цене в два раза в течение года, были выбраны восемь переменных.
Техника индуктивного обучения может быть использована для того, чтобы генерировать правила, которые классифицируют акции и боны на ранги (категории). При использовании этой техники для фундаментального анализа атрибуты нужно выбирать из финансовых данных с максимальным значением оценки временного лага. В то же время, при использовании индуктивного обучения для анализа акций, основанного на данных трейдинга, образы могут быть автоматически извлечены из чартов, и в этом случае может быть использован очень короткий временной лаг.