

10.13. Применение алгоритмов типа аво (вычисления оценок) для построения итерационных алгоритмов поиска
В практике поиска необходимо учитывать, что число записей, просмотренных пользователем, и суждение о релевантности которых известно, составляет незначительную часть от общего числа записей базы данных. Снятие этой проблемы связано с отысканием критериев устойчивости статистической выборки по функционалу ошибки. В рассмотренных выше статистических моделях дескрипторы считались либо независимыми, либо попарно зависимыми. Однако часто поиск пользователем ведется не по отдельным дескрипторам, а по различным их сочетаниям.
Класс АВО исходит из того, что неизвестно, какие сочетания атрибутов наиболее информативны. Поэтому критерию в классе АВО сопоставляются всевозможные комбинации атрибутов и их сочетаний. Пусть даны стандартные описания объектов. Пусть дано множество D объектов d, на этом множестве существует разбиение на конечное число подмножеств (классов)
![]() Разбиение
D
определено не полностью, задана лишь
некоторая информация Iо
о классах Di.
Объекты d
задаются значениями некоторых
атрибутов xj,
j-l,...,n.
Совокупность значений признаков хj
определяет описание
I(d)
объекта d.
Описание объекта
Разбиение
D
определено не полностью, задана лишь
некоторая информация Iо
о классах Di.
Объекты d
задаются значениями некоторых
атрибутов xj,
j-l,...,n.
Совокупность значений признаков хj
определяет описание
I(d)
объекта d.
Описание объекта![]() называют
стандартным,
если xi(d}
приобретает значение из множества
допустимых значений.
называют
стандартным,
если xi(d}
приобретает значение из множества
допустимых значений.
Таблица 10.4
Таблица обучения
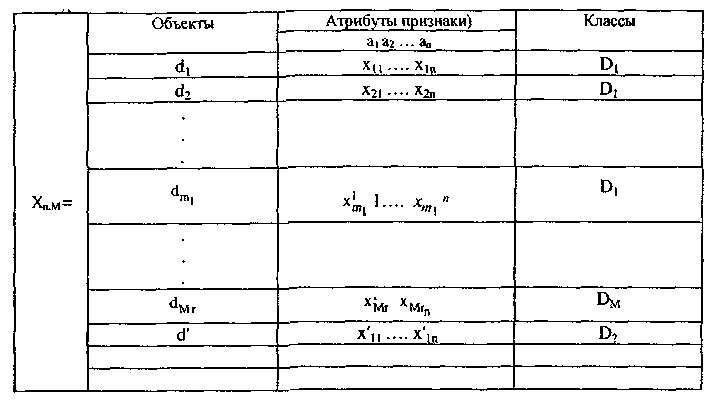
Задача классификации состоит в том, чтобы для данного объекта d и классов D1...,Dm по описанию I(d) вычислить значения предикатов Pi(d),
![]() .
Информация о вхождении объекта d
класс D;
кодируется символами
.
Информация о вхождении объекта d
класс D;
кодируется символами![]() —
не определено и записывается в
виде:
—
не определено и записывается в
виде:
![]()
Априорная информация в задаче классификации с непересекающимися классами задается в виде таблицы обучения.
Информация о принадлежности объекта классу записывается в виде:
![]()
Пусть
определена некоторая мера близости
объекта d
к тому или иному классу,
называемая обобщенной оценки![]() объектаd'
по классу Di
объектаd'
по классу Di
Описания объектов классификации переводятся в матрицу оценок
![]()
В основе тестовых алгоритмов лежит понятие теста. Тестом таблицы Хn,м называется совокупность столбцов аt1...,аtq, таких, что после удаления из Хn,м всех столбцов, за исключением имеющих номера ti,...,t<, в полученной таблице Xn-q,M все пары строк, принадлежащих разным классам, различны. Тест {xt1,...,xtq} называется тупиковым, если никакая его часть не является тестом.
Пусть
{Т} — множество всех тупиковых тестов
Тпт
и
Т{ xt1,...,xtй
}
{T}.
Выделим в описании классифицируемого
объекта I
(d'}
часть { x't1
...,x't
} соответствующую атрибутам xt1,...,xt
и сопоставим ее со всеми частными
описаниями
(хrt1
,...,хrtq
)
объектов I(dr)
таблицы![]()
Подсчитаем
число совпадений![]() частичных
описаний (x't1
,...,x't
) со
частичных
описаний (x't1
,...,x't
) со
всеми
частичными описаниями![]() объектов
i-ro
класса. Величина
объектов
i-ro
класса. Величина
FT{d, Di) представляет число строк этого класса, близких классифицируемой строке d' по тесту Т. Аналогичным образом вычисляется оценка для d' по остальным тестам (для всех классов).
Величина
F(d',
![]() представляет
собой оценку объекта
представляет
собой оценку объекта
d' по классу Di. При вычислении оценок могут быть учтены веса или важность атрибутов. Одной из естественных мер важности признаков является
информационный
вес
![]() где
г (n,m)
— число тупиковых тестов
где
г (n,m)
— число тупиковых тестов
таблицы Хn,m, raj.(n,m)- число тупиковых тестов таблицы Tn,m содержащих
атрибут aj, чем больше его информационный вес p(aj), тем значительнее роли в описании объектов.
Переход от тестовых алгоритмов к АВО связан с расширением видов подмножества атрибутов, по которым производится сопоставление классифицируемого объекта с объединениями из Xn,m и построением оценок опорных множеств.
Системы опорных множеств составляются из всех подмножеств множества атрибутов фиксированной длины q, q=2,..., m-1, либо из всех непустых подмножеств множества атрибутов.
Рассмотрим полный набор атрибутов <а1 . . ., аn> и выделим систему
опорных множеств S1 . . ., SL. Удалим произвольный поднабор признаков из строк d1, d2,..., drm, d' и обозначим полученные строки xd1 ,xd2 ,...xdrm xd
Правило сходства, позволяющее оценить похожесть строк xd1 и xd2 состоит в
следующем.
Пусть усечение строки содержит q
первых признаков, т.е. xdr
= (x1,...,xq)
и xd,
= (х1...,хq)
и заданы пороги Е1,...,Еq,![]() .
Строкиxd.
и хdr
считаются
похожими, если выполняется не
менее б неравенств вида
.
Строкиxd.
и хdr
считаются
похожими, если выполняется не
менее б неравенств вида
![]() Величины
Е1,...,Еq
,
Величины
Е1,...,Еq
,
![]() входят в качестве параметров в
модель
класса алгоритмов типа АВО. Рассмотрим
процедуру выполнения оценок по
подмножеству S1.
Для остальных подмножеств она полностью
аналогична.
В матрице Xn,m
выделяются столбцы, соответствующие
атрибутам,
входящим в S1,
остальные столбцы вычеркиваются.
Проверяется близость
строки xld.
со строками xld
,...,xld
, принадлежащему классу Ω1.
Число
строк этого класса, близких по выбранному
классифицируемой строке х1d,
обозначается Fs1
(d1,
D1),
эта величина представляет собой оценку
строки
d'
для класса D1
по опорному множеству S1.
Аналогичным образом вычисляются
оценки для остальных классов: Fs1
(d',D2),...,Fs1
(d',Dm)
. Применение
подобной
процедуры ко всем остальным опорным
множествам алгоритма позволяет получить
систему оценок
входят в качестве параметров в
модель
класса алгоритмов типа АВО. Рассмотрим
процедуру выполнения оценок по
подмножеству S1.
Для остальных подмножеств она полностью
аналогична.
В матрице Xn,m
выделяются столбцы, соответствующие
атрибутам,
входящим в S1,
остальные столбцы вычеркиваются.
Проверяется близость
строки xld.
со строками xld
,...,xld
, принадлежащему классу Ω1.
Число
строк этого класса, близких по выбранному
классифицируемой строке х1d,
обозначается Fs1
(d1,
D1),
эта величина представляет собой оценку
строки
d'
для класса D1
по опорному множеству S1.
Аналогичным образом вычисляются
оценки для остальных классов: Fs1
(d',D2),...,Fs1
(d',Dm)
. Применение
подобной
процедуры ко всем остальным опорным
множествам алгоритма позволяет получить
систему оценок

Величины

представляют собой оценки строки d' для соответствующих классов по системе опорных множеств алгоритма SA. На основании анализа этих величин принимается решение либо об отнесении объекта d' к одному из классов Di, i=l,...m, либо об отказе от классификации.
Пример
10.1. Задана
таблица обученных и классифицированных
запросов.
Пусть![]()
Таблица 10.5

Поскольку заносятся в класс 2.
Сложность![]() формулы
вычисления оценок АВО при произвольнойSA
пропорциональные
сложности ДНФ, представляющей
характеристическую
функцию систем опорных множеств
алгоритма. Это означает, что построение
простой формулы вычисления оценок
F(d'',
Di)
связано с заданием минимизации
булевых функций в классе ДНФ, а точнее
с заданием
построения кратчайшей ортогональной
ДНФ или ДПФ, в которой каждая
элементарная конъюнкция имеет небольшое
число общих переменных с соседними.
формулы
вычисления оценок АВО при произвольнойSA
пропорциональные
сложности ДНФ, представляющей
характеристическую
функцию систем опорных множеств
алгоритма. Это означает, что построение
простой формулы вычисления оценок
F(d'',
Di)
связано с заданием минимизации
булевых функций в классе ДНФ, а точнее
с заданием
построения кратчайшей ортогональной
ДНФ или ДПФ, в которой каждая
элементарная конъюнкция имеет небольшое
число общих переменных с соседними.