

3.4.6. Зависимости
Функциональная зависимость
Если даны два атрибута X и Y некоторого отношения, то Y функционально зависит от X, если в любой момент времени каждому значению X соответствует ровно одно значение Y.
Функциональная зависимость обозначается X à Y.
Отметим, что X и Y могут представлять собой не только единичные атрибуты, но и группы, составленные из нескольких атрибутов одного отношения.
Пример:
Номер паспорта à Фамилия
ID_сотрудника à СтажРаботыВФирме
Избыточная функциональная зависимость
Избыточная функциональная зависимость – зависимость, заключающая в себе такую информацию, которая может быть получена на основе других зависимостей, имеющихся в базе данных.
Пример:
ID_сотрудника à ПаспортныеДанные à ФИО
Полная функциональная зависимость
Функциональная зависимость X à Y является ПОЛНОЙ, если Y не зависит функционально от любого подмножества X.
Пример:
{МестоОтправки, МестоНазначения, ВидГруза, ВесГруза} à СтоимостьДоставки
Частичная функциональная зависимость
Функциональная зависимость X à Y является ЧАСТИЧНОЙ, если Y зависит функционально от некоторого подмножества X.
Пример:
{НомерКузова, НомерГосрегистрации} à Владелец
Транзитивная функциональная зависимость
Функциональная зависимость X à Y является транзитивной, если существуют зависимости X à Z и Z à Y, но отсутствует прямая зависимость X à Y.
Пример:
ID_сотрудника à ID_Офиса à ТелефонОфиса
Многозначная зависимость
Многозначная зависимость X àà Y существует в том и только в том случае, если множество значений Y, соответствующее паре значений X и Z, зависит только от X и не зависит от Z (то есть если для каждого значения атрибута X существует множество соответствующих значения атрибута Y).
В общем случае в отношении R (A,B,C) существует многозначная зависимость R.A àà R.B в том и только в том случае, когда существует многозначная зависимость R.A àR.C.
Пример:
Отношение: R(Проект, Сотрудник, Задание)
Многозначные зависимости:
Проект àà Сотрудник
Проект àà Задание
3.4.6. Первая нормальная форма
Отношение находится в первой нормальной форме (1НФ), если все атрибуты отношения являются атомарными, т.е. не имеют компонентов.
Иными словами, домен атрибута должен состоять из неделимых значений и не может включать в себя множество значений из более элементарных доменов.
В большинстве случаев выполнить это требование достаточно просто. Каждый простой атрибут должен иметь свою колонку в таблице. Однако это часто приводит к дублированию данных в отношении.
На рисунке слева представлено ненормализованное (до 1НФ) отношение, справа – нормализованное.
|
|
Рисунок 3.4.6.1 – Ненормализованное (до 1НФ) и нормализованное отношения |
|
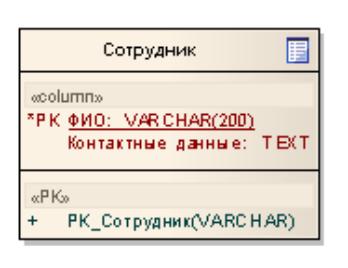
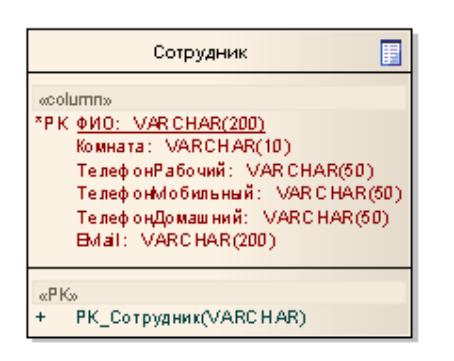
Вопрос об атомарности атрибутов решается на основе семантики данных, то есть их смыслового значения.
Атрибут атомарен, если его значение теряет смысл при любом разбиении на части или переупорядочивании.
И наоборот, если какой-либо способ разбиения на части не лишает атрибут смысла, то атрибут неатомарен.
Одно и то же значение может быть атомарным или неатомарным в зависимости от смысла этого значения.
Например, значение «4286» является
атомарным, если его смысл — «пин-код кредитной карты» (при разбиении на части или переупорядочивании смысл теряется);
неатомарным, если его смысл — «чётные цифры» (при разбиении на части или переупорядочивании смысл не теряется).
Хорошим способом принятия решения о необходимости разбиения атрибута на части является вопрос: «будут ли части атрибута использоваться по отдельности?» Если да, то атрибут следует разделить (но так, чтобы сохранились осмысленные части атрибута).