

3.1.7. Пример логической и физической схемы в ErWin
Сейчас мы рассмотрим пример простенькой БД, логическая и физическая схема которой построена с использованием CASE-средства разработки БД – AllFusion ErWin Data Modeler.

Рисунок 3.1.7.1 – Логическая схема БД
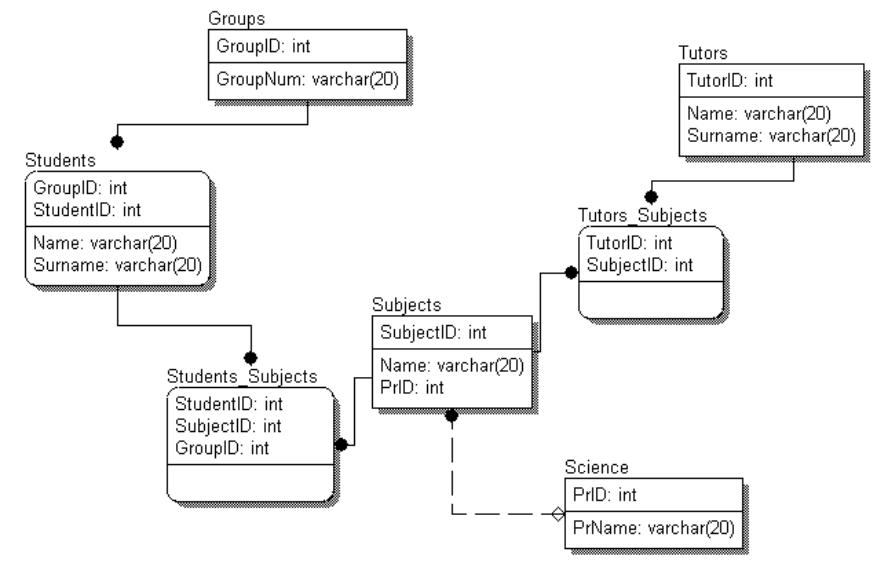
Рисунок 3.1.7.2 – Физическая схема БД
3.1.8. Минимальный набор стандартных таблиц
В большинстве SQL-серверов есть т.н. «системный каталог» – набор стандартных таблиц, содержащих информацию обо всех объектах сервера и базы данных.
Проблема в том, что эти таблицы предназначены вовсе не для разработчика, а для внутреннего использования самим сервером, поэтому найти там что-либо человекополезное весьма проблематично.
При этом, структура их может меняться даже в разных версиях одного сервера, не говоря уже о совместимости с серверами других производителей. Кроме того, в системные таблицы обычно нельзя вносить никакие изменения.
Поэтому, желательно создать в БД собственный системный каталог, полностью описывающий структуру базы и взаимосвязи её объектов.
Такой каталог можно переносить на другой сервер вместе с БД, не заботясь о совместимости, а информацию из него можно легко использовать в приложении для каких-либо действий (вплоть до автоматической генерации самого приложения).
Необходимо только определить, какие таблицы должны входить в такой каталог.
Структура данных
Следует отметить, что в SQL-серверах очень много зарезервированных слов, которые нельзя использовать в качестве имён таблиц и полей. Поэтому, желательно добавлять какие-нибудь префиксы к названиям, либо всегда пользоваться специальным синтаксисом.
Для описания структуры данных, потребуется три основных таблицы: DataTypes, Tables и Columns.
Примерное строение этих таблиц (здесь и далее - синтаксис MS SQL Server):
create table [DataTypes]
(
[Id] int not null identity primary key,
[Parent] int references [DataTypes]([Id]),
[Name] varchar(120) not null unique,
[Note] varchar(250),
[SQLType] varchar(250) not null
)
create table [Tables]
(
[Id] int not null identity primary key,
[Name] varchar(120) not null unique,
[Note] varchar(250),
[Key] int references [Columns]([Id])
)
create table [Columns]
(
[Id] int not null identity primary key,
[Table] int not null references [Tables]([Id]),
[Name] varchar(120) not null,
[Note] varchar(250),
[DataType] int not null references [DataTypes]([Id]),
[Size] int not null,
[LinkTable] int references [Tables]([Id]),
[Default] varchar(250),
[Obligatory] bit not null defaul(0),
[Unique] bit not null defaul(0)
)
Таблица DataTypes хранит названия и описания всех типов данных, используемых в базе. Она должна содержать не только основные типы, но и дополнительные: автонумеруемое поле (identity), ссылка (поле, содержащее значение ПК другой таблицы) и т.п. Поле Parent позволяет показать наследование одного типа от другого.
Таблица Tables содержит имена и описания всех таблиц базы. Key определяет поле, являющееся первичным ключом каждой таблицы.
Таблица Columns определяет названия полей в таблицах, их типы данных и размер, связанные таблицы (для полей ссылочного типа), значения полей по умолчанию, флаги обязательности, уникальности и т.п.
Даже такие, далеко не полные метаданные, можно использовать для частичной автоматизации приложения, добавив проекту гибкости и избавив программистов от ненужной рутины.
Пользователи
Если с базой данных работает несколько пользователей, то возникает потребность их различать и, соответственно, давать им разные права. Когда количество пользователей превышает десяток, желательно разделять их по группам.
Пользователи, входящие в одну группу, как правило, выполняют сходные действия и обладают одинаковыми правами. Для описания пользователей понадобится две таблицы: People и Users.
create table [People]
(
[Id] int not null identity primary key,
[LastName] varchar(120) not null,
[FirstName] varchar(120) not null,
[MiddleName] varchar(120) not null,
[Note] varchar(250)
)
create table [Users]
(
[Id] int not null identity primary key,
[Name] varchar(120) not null unique,
[Note] varchar(250),
[Person] int references [People]([Id])
)
Одному человеку может соответствовать как несколько пользователей, так и ни одного. Но пользователь может быть и виртуальным.
Пользователь может включаться в несколько групп (в общем случае), поэтому понадобится ещё две таблицы: Groups и UsersInGroups.
create table [Groups]
(
[Id] int not null identity primary key,
[Name] varchar(120) not null unique,
[Note] varchar(250)
)
create table [UsersInGroups]
(
[Group] int not null references [Groups]([Id]),
[User] int not null references [Users]([Id])
constraint [UserInGroup] primary key ([Group], [User])
)
Механизм проверки прав пользователей может зависеть от многих условий, в том числе и от того, для каких объектов необходимо осуществлять проверку. Поскольку правовая модель достаточно специфична, её имеет смысл разрабатывать в каждом конкретном случае отдельно.
Журнал изменений
Часто бывает нужно организовать хранение истории изменений записей с возможностью просмотра и отката этих изменений.
Таблицы истории обычно достигают большого размера, а используются достаточно редко, поэтому их можно держать в другой базе. Так как изменения происходят в транзакциях, то для их хранения потребуется две таблицы: Transactions и Changes.
create table [Transactions]
(
[Id] int not null identity primary key,
[Date] datetime not null default(getdate()),
[User] int not null references [User]([Id])
)
create table [Changes]
(
[Id] int not null identity primary key,
[Transaction] int not null references [Transactions]([Id]),
[Entity] int not null,
[Column] int not null references [Columns]([Id]),
[OldValue] varchar(4000)
)
Таблица Transactions хранит дату транзакции и Id пользователя, совершившего её. Таблица Changes, кроме транзакции, содержит значение ПК изменяемой записи, ссылку на изменяемое поле и прежнее значение поля, преобразованное в строку.
При необходимости, можно добавить возможность записи в журнал историю добавления и удаления записей.
Запись в журнал можно делать либо триггерами, либо из приложения. Откат изменений следует производить специальной процедурой, которая должна восстановить значения полей для заданной транзакции и удалить соответствующие записи из журнала.
Перечисления
Многие поля в различных таблицах принимают значения только из определённого набора. Это могут быть разнообразные состояния, категории, типы и т.п.
Не всегда существует необходимость заводить отдельную таблицу для хранения каждого набора значений. В таких случаях можно обойтись одной иерархической таблицей перечислений, каждая ветка которой, содержит отдельный набор значений для разных случаев.
create table [Enumerations]
(
[Id] int not null identity primary key,
[Parent] int references [Enumerations]([Id]),
[Code] varchar(120) not null unique,
[Name] varchar(120) not null
)
Поле Code может являться как кодом целого набора, так и кодом значения в наборе.
Параметры
Довольно часто возникает необходимость держать в базе значения каких-либо глобальных параметров, постоянных или не очень.
Например, пути к другим базам/серверам, имена административных файлов, величины процентов налогов и т.п. Для хранения значений параметров, разбитых по категориям, потребуется таблица Parameters:
create table [Parameters]
(
[Id] int not null identity primary key,
[Category] int not null references [Enumerations]([Id]),
[Name] varchar(120) not null unique,
[DataType] int not null references [DataTypes]([Id]),
[Value] varchar(4000)
)
Сообщения
При сбое программы, либо при неверных действиях пользователя, необходимо вывести ему внятное сообщение о причинах произошедшего, и инструкцию, что делать в этом случае.
Чтобы не писать сообщения в коде в каждом месте, где может возникнуть проблема, рекомендуется хранить тексты сообщений в специальной таблице Messages:
create table [Messages]
(
[Id] int not null identity primary key,
[Category] int not null references [Enumerations]([Id]),
[Name] varchar(120) not null unique,
[Text] varchar(4000)
)
Сообщения разделены по видам, и каждому сообщению присвоено определенное имя, по которому его и следует вызывать в случае необходимости.