

InnoDb в MySql 5.1
полностью поддерживает построковую репликацию003B
исправлено множество недочётов, влияющих на производительность.
2.6.10. Итог
На этом мы заканчиваем рассмотрение готовых решений и переходим к рассмотрению «того, как сделать что-то подобное своими руками» – к описанию механизмов шэширования, ориентированных на базы данных, а также к описанию того, как хранить в бинарных файлах сложные структуры данных.
2.7. Физическое представление древовидных и сетевых структур
2.7.1. Введение
В этой теме мы рассмотрим конкретные алгоритмы хранения сложных (древовидных и сетевых) структур данных в файлах.
2.7.2. Древовидные структуры
Усложнённый двумерный файл
Одним из самых простых способов представления древовидных структур является т.н. «усложнённый двумерный файл».
В простом двумерном файле каждая запись содержит один и тот же набор элементов данных. Такой файл физически может быть представлен последовательно. Однако атрибуты, связанные с одним описываемым объектом, в реальности могут иметь несколько значений.
Рассмотрим рисунок…
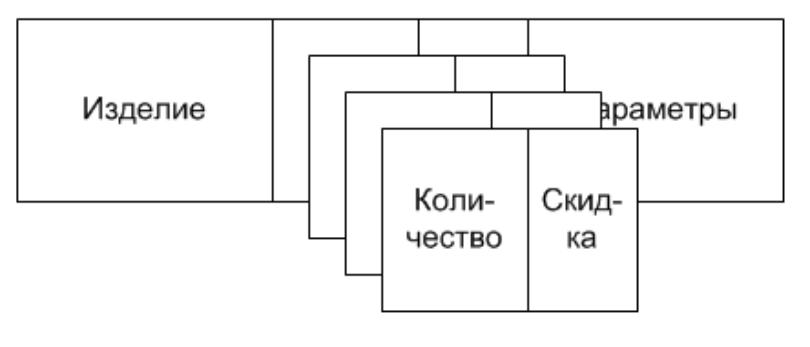
Рисунок 2.7.2.1 – Усложнённый двумерный файл
На рисунке представлен файл, в котором хранятся расценки на изделия, а также информация о скидках в зависимости от количества приобретаемых изделий.
Если используются записи переменной длины, то включение в запись нескольких наборов пар «количество-скидка» не представляет трудностей. Однако в случае с записями постоянной длины такое решение не годится.
У разработчика алгоритма хранения имеются три возможности.
Он может зарезервировать в записи место для некоторого количества пар «количество-скидка». В этом случае память будет использоваться неэффективно, поскольку в большинстве записей число значений этого поля будет меньше зарезервированного.
Он может ввести отдельную запись для каждой скидки (фактически – создать дополнительную таблицу, пусть и неявно), а в исходной записи поместить указатель на последовательный набор записей «количество-скидка» в другом файле. В этом случае при обращении к основной записи всегда производится дополнительный поиск на внешнем запоминающем устройстве.
Разработчик может зарезервировать в основной записи место для нескольких значений пар «количество-скидка» и дополнительно ввести запись переполнения для случаев, когда зарезервированного места будет недостаточно.
В современных базах данных для хранения подобных структур используют две отдельных таблицы. Если при работе с БД часто возникает ситуация, когда необходимо «показать все товары со всеми скидками», возможно кэширование всего набора «количества-скидки» в одном поле в сериализованном виде.
Главный и детальный файлы
В системах обработки данных двухуровневые файлы используются часто; например, для банковской системы используются записи счетов клиентов и записи о сделках клиентов.
Эти записи обычно рассматриваются соответственно как главные и детальные записи и изображаются в виде двухуровневого дерева.
Для любого такого файла или для любой пары уровней дерева разработчик имеет возможность выбора степени включения некоторых сегментов нижнего уровня в сегменты верхнего уровня (по первому способу организации усложнённого двумерного файла).

Рисунок 2.7.2.2 – Главный и детальный файлы
Левосписковые структуры
Такие структуры удобно применять для хранения многоуровневых деревьев. В файле хранится, фактически, результат «левого обхода дерева».
Рассмотрим на рисунке…
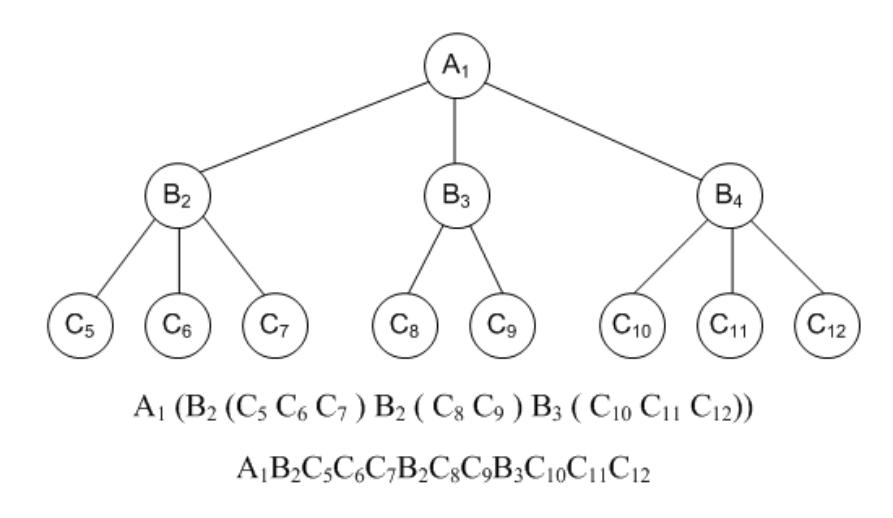
Рисунок 2.7.2.3 – Левосписковые структуры
Указатели на исходные, порождённые и подобные записи
Ещё одним способом хранения многоуровневых деревьев в последовательных файлах является использование указателей на исходные или порождённые и подобные записи.
Использование указателей только на порождённые записи привело бы к необходимости формировать набор указателей переменной длины.
Рассмотрим на рисунке…
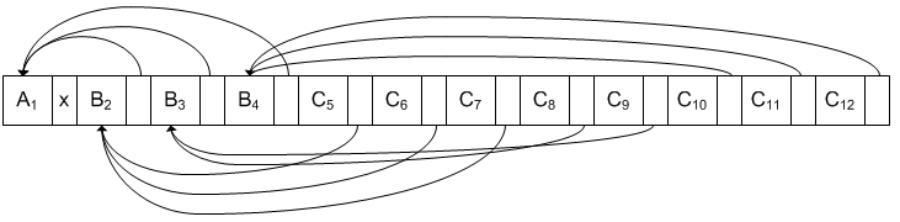
Рисунок 2.7.2.4 – Указатели на исходные записи

Рисунок 2.7.2.5 – Указатели на порождённые и подобные записи
Оптимизация включения и удаления записей
Если древовидная логическая структура данных отображается на последовательно организованные файлы на физических носителях, то необходимы специальные методы для управления включением и удалением записей.
Более оптимальным способом работы с такими данными является отдельное хранение элементов и связей между ними.
Рассмотрим два таких решения.
Справочники деревьев
Справочник – это файл, в котором хранится информация о связях между записями в других файлах.
Справочник обычно имеет небольшой размер и может быть считан в основную память, что позволяет вести поиск с высокой скоростью.
Время и затраты на включение и удаление записей при использовании справочника указателей также меньше, чем при использовании встроенных указателей.
Фактически, справочники представляют собой плотный индекс, позволяющий работать с файлами, записи в которых размещены в произвольном порядке.
Битовые отображения
Битовые отображения позволяют хранить информацию о структуре дерева в предельно компактной форме, а также позволяют ОЧЕНЬ быстро производить поиск с использованием обычных логических операций над бинарными данными.
Рассмотрим пример битового отображения на рисунке…

Рисунок 2.7.2.6 – Битовое отображение