

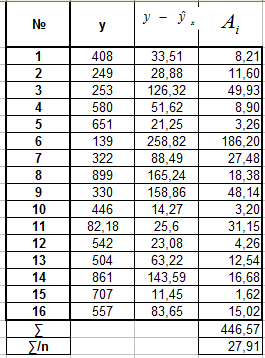
Оценим качество уравнений с помощью средней ошибки аппроксимации
![]()
Средняя ошибка аппроксимации - среднее
отклонение расчетных (теоретических)
значений зависимой переменной y
от фактических (эмпирических) значений
![]()
Допустимый предел значений
![]() не
более 10-12 %.
не
более 10-12 %.
А. Для линейной регрессии Б. Для степенной регрессии
![]()
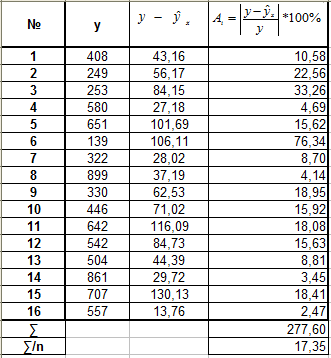
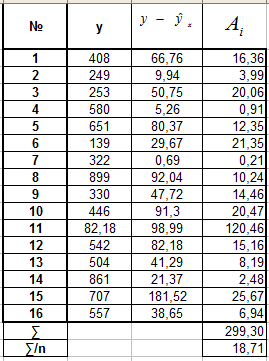
![]()
![]()
В. Для экспоненциальной регрессии Г. Для полулогарифмической регрессии
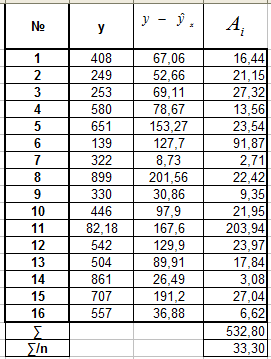
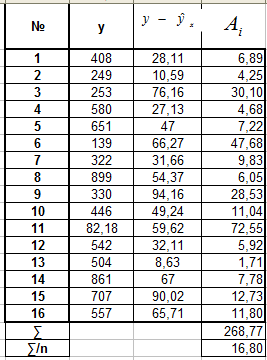
![]()
![]()
Е. Для гиперболической регрессии
![]()
Вывод: для каждой из построенных моделей ошибка аппроксимации превышает допустимые пределы, что говорит о плохом качестве моделей регрессии.
Наименьшей (хотя и недопустимой) она является для уравнения полулогарифмической регрессии .
Оценим статистическую надежность результатов регрессионного моделирования с помощью f-критерия Фишера.
Н0 - гипотеза о статистической незначимости показателя детерминации R² (Fфакт = 0) и уравнения регрессии.
n – общее число наблюдений (n=16); m – число параметров при переменной x (m=1)/
По таблице значений F-критерия Фишера при условии значимости = 0,05 и число степеней свободы k1 = m = 1, k2 = n – m – 1 = 16-1-1= 14 находим Fкр - максимально возможное значение критерия под влиянием случайных факторов при данных степенях свободы и уровне значимости : Fкр = 4,60.
А. Для линейной регрессии
(![]() )
)

Так как
![]() то гипотеза Н0 отвергается,
т.е. R²
статистически значим, как и уравнение
линейной регрессии.
то гипотеза Н0 отвергается,
т.е. R²
статистически значим, как и уравнение
линейной регрессии.
Б. Для степенной регрессии
(![]() )
)
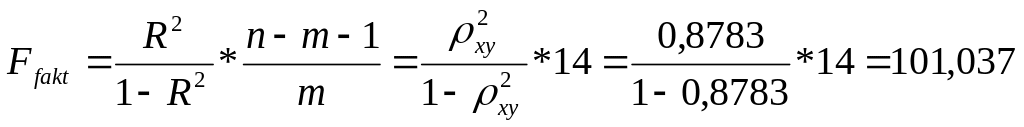
Так как
![]() то гипотеза Н0 отвергается,
т.е. R²
статистически значим, как и уравнение
степенной регрессии.
то гипотеза Н0 отвергается,
т.е. R²
статистически значим, как и уравнение
степенной регрессии.
В. Для экспоненциальной регрессии
(![]() )
)
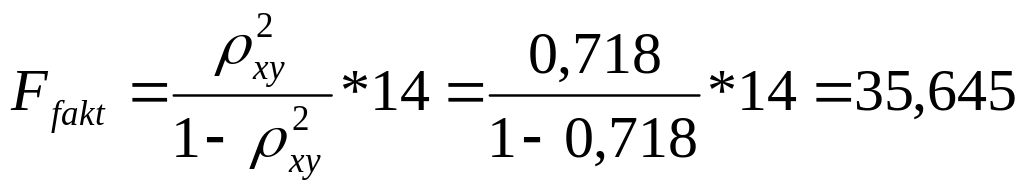
Так как
![]() то гипотеза Н0 отвергается,
т.е. R²
статистически значим, как и уравнение
полулогарифмической регрессии.
то гипотеза Н0 отвергается,
т.е. R²
статистически значим, как и уравнение
полулогарифмической регрессии.
Д. Для гиперболической регрессии
(![]() )
)
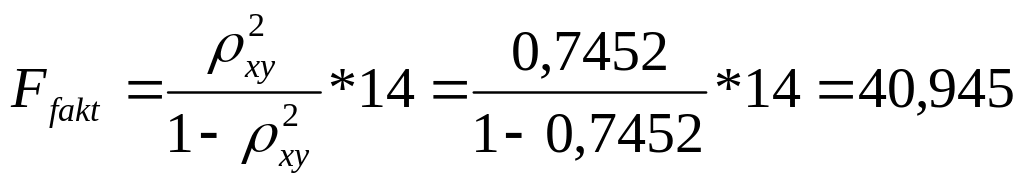
Так как
![]() то гипотеза Н0 отвергается,
т.е. R²
статистически значим, как и уравнение
гиперболической регрессии.
то гипотеза Н0 отвергается,
т.е. R²
статистически значим, как и уравнение
гиперболической регрессии.
Вывод: F-критерия
Фишера показывает, во сколько раз
уравнение регрессии предсказывает
результаты наблюдений лучше, чем прямая
![]() .
.
Статистически значимыми являются
уравнения линейной, степенной,
экспоненциальной, гиперболической
регрессии, из них всех лучше предсказывает
результаты наблюдений уравнение
степенной регрессии (![]() )
)
По значениям характеристик, рассчитанных в пп. 4,6,7 выберем лучшее уравнение регрессии и дадим его обоснование.
П.4. Наибольшее значение коэффициента эластичности имеет уравнение степенной регрессии ( .
П.6. Наименьшую ошибку аппроксимации (хотя и не допустимую) имеет уравнение полулогарифмической регрессии . Уравнение степенной регрессии отличается на небольшую величину:
П.7. Согласно F-критерию Фишера лучше всех предсказывает результаты наблюдений уравнение степенной регрессии ( )
Вывод: Лучше всех описывает данные наблюдений (зависимость между средней заработанной платой и выплатами социального характера x и потребительскими расходами на душу населения y) уравнение степенной регрессии
Качество модели плохое, так как >10%, возможно из-за небольшого числа наблюдений (n=16).
По линейному уравнению регрессии рассчитаем прогнозное значение результата (y), если прогнозное значение фактора (x) увеличивается на 7% от его среднего уровня:
Уравнение линейной регрессии y=a + b*x ( ).
n – общее число наблюдений (n=16); m – число параметров при переменной x (m=1);
![]()
![]() tкр
= 2,1448
tкр
= 2,1448
![]()
Прогнозное значение фактора (x):
xпр =
![]() тыс.
руб.;
тыс.
руб.;
xпр -
![]() = 44,25 – 885 = -840,75; (xпр -
= 44,25 – 885 = -840,75; (xпр -
![]() = (-840,75)² = 706860,5625.
= (-840,75)² = 706860,5625.
Прогнозное значение фактора (y):
yпр = a + b* xпр = 160,48 + 0,39*44,25 = 177,74 тыс. руб.
Стандартная ошибка прогноза:
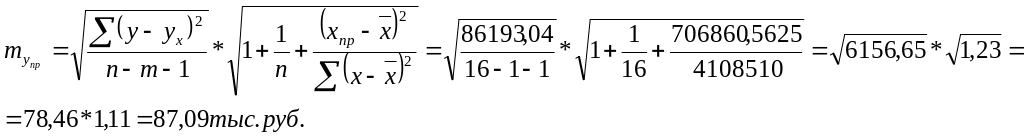
Предельная ошибка прогноза, которая в 95% случаев не будет превышена, составит:
![]()
Доверительный интервал прогноза для уровня значимости =0,05:
(min
![]() max
max
![]() или
или
(![]()
![]() =
(177,74 – 186,79; 177,74 + 186,79) = (-9,05; 364,53)
=
(177,74 – 186,79; 177,74 + 186,79) = (-9,05; 364,53)