

4.4. Оценка методом kn ближайших соседей
Одна
из проблем, с которой сталкиваются при
использовании метода парзеновского
окна, заключается в выборе последовательности
объемов ячеек V1,
V2,
. . . . Например,
если мы берем
Vn,=V1/![]() ,
то результаты
для любого конечного п
будут очень чувствительны к выбору
начального объема
V1.
Если V1
слишком
мал, большинство объемов будут пустыми
и оценка рn(х)
будет довольно ошибочной. С другой
стороны, если V1
слишком велик, то из-за усреднения по
объему ячейки могут быть потеряны
важные пространственные отклонения
от р(x).
Кроме того, вполне может случиться, что
объем ячейки, уместный для одного
значения х,
может совершенно не годиться для других
случаев.
,
то результаты
для любого конечного п
будут очень чувствительны к выбору
начального объема
V1.
Если V1
слишком
мал, большинство объемов будут пустыми
и оценка рn(х)
будет довольно ошибочной. С другой
стороны, если V1
слишком велик, то из-за усреднения по
объему ячейки могут быть потеряны
важные пространственные отклонения
от р(x).
Кроме того, вполне может случиться, что
объем ячейки, уместный для одного
значения х,
может совершенно не годиться для других
случаев.
Один
из возможных способов решения этой
проблемы
- сделать
объем ячейки функцией данных, а не
количества выборок. Например, чтобы
оценить р
(х) на основании
n
выборок, можно центрировать ячейку
вокруг х и позволить ей расти до тех
пор, пока она не вместит
![]() выборок,
где
выборок,
где
![]() есть некая определенная функция от п.
Эти выборки
будут
есть некая определенная функция от п.
Эти выборки
будут
![]() ближайшими соседями х. Если плотность
распределения вблизи х высокая, то
ячейка будет относительно небольшой,
что приводит к хорошему разрешению.
Если плотность распределения
невысокая, то ячейка возрастает, но
рост приостанавливается вскоре
после ее вступления в области более
высокой
ближайшими соседями х. Если плотность
распределения вблизи х высокая, то
ячейка будет относительно небольшой,
что приводит к хорошему разрешению.
Если плотность распределения
невысокая, то ячейка возрастает, но
рост приостанавливается вскоре
после ее вступления в области более
высокой
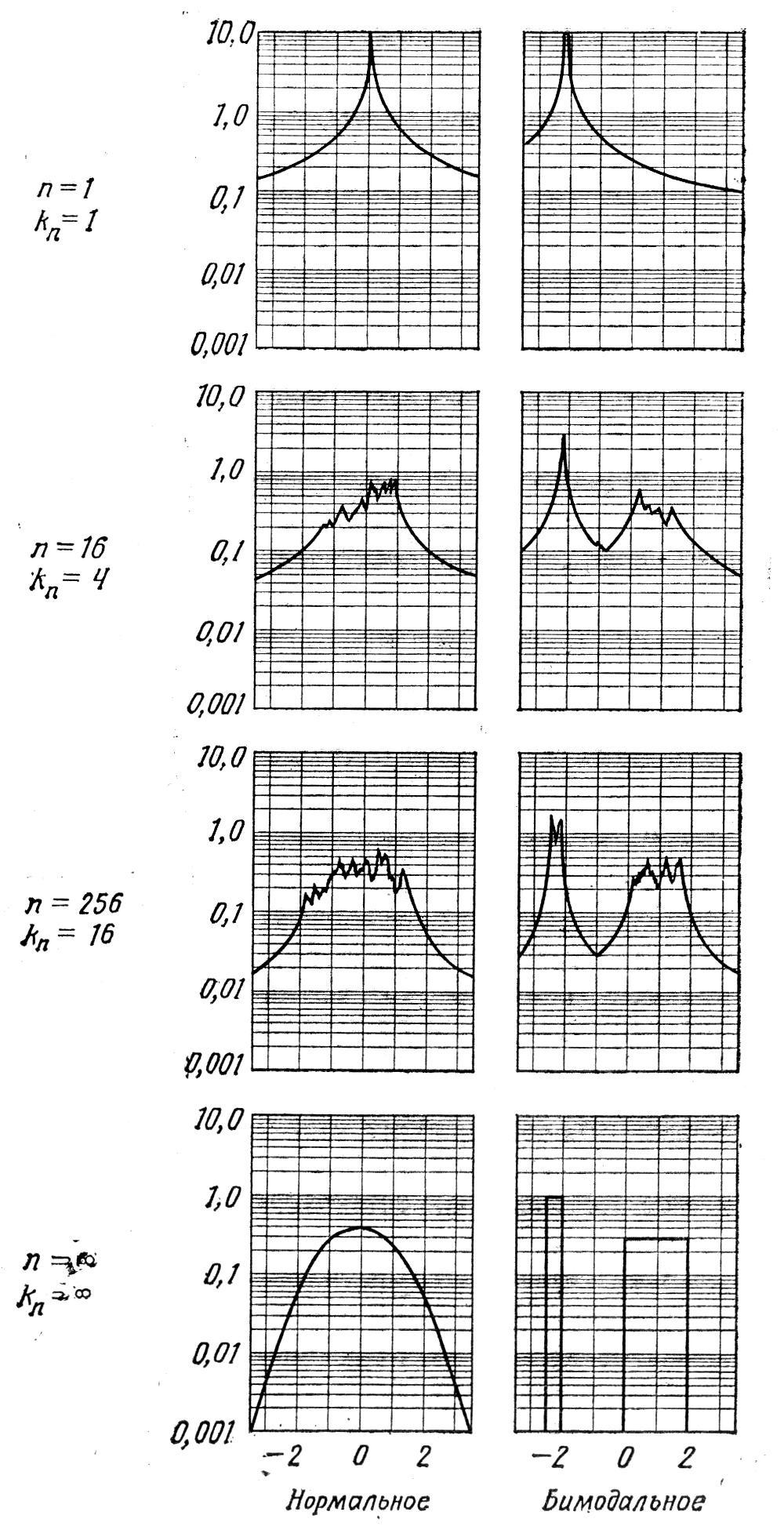
Рис. 4. 3. Оценки двух плотностей распределения, полученные методом kn ближайших соседей.
плотности распределения. В любом случае, если мы берем
![]() (5)
(5)
мы
хотим, чтобы
![]() стремилось к бесконечности при стремлении
п к
бесконечности, так как это гарантирует,
что
стремилось к бесконечности при стремлении
п к
бесконечности, так как это гарантирует,
что
![]() /n
будет хорошей оценкой вероятности
попадания точки в ячейку объема
/n
будет хорошей оценкой вероятности
попадания точки в ячейку объема
![]() Однако мы хотим также, чтобы
Однако мы хотим также, чтобы
![]() росло достаточно медленно для того,
чтобы размер ячейки, необходимый для
вмещения
росло достаточно медленно для того,
чтобы размер ячейки, необходимый для
вмещения
![]() выборок, сжался до нуля. Таким образом,
из формулы
(5) видно,
что отношение
выборок, сжался до нуля. Таким образом,
из формулы
(5) видно,
что отношение
![]() /n
должно стремиться к нулю. Хотя мы не
приводим доказательств, можно показать,
что условия
/n
должно стремиться к нулю. Хотя мы не
приводим доказательств, можно показать,
что условия
![]() и
и
![]() являются необходимыми и достаточными
для сходимости рn
(х) и р
(х) по вероятности во всех точках,
где плотность р
непрерывна. Если взять kn=
являются необходимыми и достаточными
для сходимости рn
(х) и р
(х) по вероятности во всех точках,
где плотность р
непрерывна. Если взять kn=![]() и допустить, что рn(х)
является хорошей аппроксимацией р(x),
то из соотношения
(5) следует,
что
и допустить, что рn(х)
является хорошей аппроксимацией р(x),
то из соотношения
(5) следует,
что
![]()
![]() .
Таким образом,
.
Таким образом,
![]() опять имеет вид
опять имеет вид
![]() ,
но начальный объем
,
но начальный объем
![]() определяется характером данных, а
не каким-либо нашим произвольным
выбором.
определяется характером данных, а
не каким-либо нашим произвольным
выбором.
Полезно
сравнить этот метод с методом парзеновского
окна на тех же данных, что были использованы
в предыдущих примерах. С n=l
и
![]() =
=![]() =
1
оценка становится
=
1
оценка становится
![]()
Ясно, что это плохая оценка для р (х), поскольку ее интеграл расходится. Как показано на рис. 4.3, оценка становится значительна лучше по мере увеличения n несмотря на то, что интеграл оценки всегда остается бесконечным. Этот неприятный факт компенсируется тем, что рn(х) никогда не сведется к нулю просто потому, что в некоторую произвольную ячейку или окно не попадают никакие выборки. Хотя эта компенсация может показаться скудной, в пространствах более высокой размерности она приобретает большую ценность.
Как
и в методе парзеновского окна, мы можем
получить семейство оценок, принимая
![]() =
=![]()
![]() и выбирая различные значения для
и выбирая различные значения для
![]() .
Однако при отсутствии какой-либо
дополнительной информации любой
выбор одинаково хорош, и мы можем быть
уверены лишь в том, что результаты будут
асимптотически правильными.
.
Однако при отсутствии какой-либо
дополнительной информации любой
выбор одинаково хорош, и мы можем быть
уверены лишь в том, что результаты будут
асимптотически правильными.