

4.10. Линейный дискриминант Фишера
Одной из непреходящих проблем, с которой сталкиваются при применении статистических методов для распознавания образов, является то, что Беллманом было названо проклятием размерности. Процедуры, выполнимые аналитически или непосредственным вычислением в пространствах небольшой размерности, могут стать совершенно неприменимыми в пространстве с 50 или 100 измерениями. Были разработаны различные методы уменьшения размерности пространства признаков в надежде получить задачу, поддающуюся решению.
Можно уменьшить размерность с d измерений до одного, просто проецируя d-мерные данные на прямую. Конечно, особенно если выборки образуют хорошо разделенные компактные группы в d-пространстве, проекция на произвольную прямую обычно смешивает выборки из всех классов. Однако, вращая эту прямую, мы можем найти такую ориентацию, для которой спроецированные выборки будут хорошо разделены. Именно это является целью классического дискриминантного анализа.
Предположим,
что мы имеем множество п
d-мерных
выборок x1,
. .
., хn,
n1
в подмножестве
![]() ,
помеченном
,
помеченном
![]() и n2
в подмножестве
и n2
в подмножестве
![]() ,
помеченном
,
помеченном
![]() .
Если мы образуем линейную комбинацию
компонент вектора
х, получим
скалярную величину
.
Если мы образуем линейную комбинацию
компонент вектора
х, получим
скалярную величину
![]() (66)
(66)
и
соответствующее множество
п
выборок y1,
. .
., yn
разделенное на подмножества
![]() и
и
![]() .
Геометрически, если ||w||=l,
каждая компонента
.
Геометрически, если ||w||=l,
каждая компонента
![]() ,
есть проекция соответствующего
,
есть проекция соответствующего
![]() на прямую в направленииw.
В действительности величина w
не имеет реального значения, поскольку
она просто определяет масштаб у.
Однако направление
w
имеет значение. Если мы вообразим, что
выборки, помеченные
на прямую в направленииw.
В действительности величина w
не имеет реального значения, поскольку
она просто определяет масштаб у.
Однако направление
w
имеет значение. Если мы вообразим, что
выборки, помеченные
![]() ,
попадают более или менее в одну группу,
а выборки, помеченные
,
попадают более или менее в одну группу,
а выборки, помеченные
![]() ,
попадают в другую, то мы хотим, чтобы
проекции на прямой были хорошо разделены
и не очень перемешаны. На рис.
4.6 показан
выбор двух различных значений w
для двумерного случая.
,
попадают в другую, то мы хотим, чтобы
проекции на прямой были хорошо разделены
и не очень перемешаны. На рис.
4.6 показан
выбор двух различных значений w
для двумерного случая.
Мерой
разделения спроецированных точек
служит разность средних значений
выборки. Если
![]() есть
есть
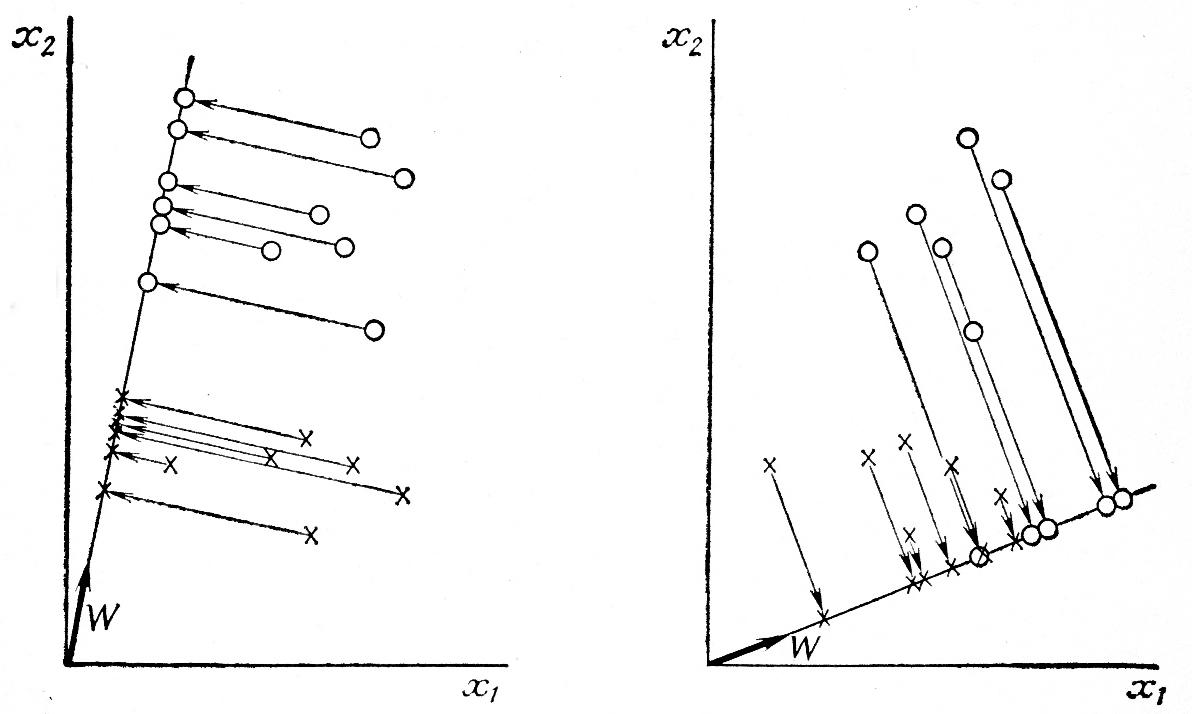
Рис. 4.6. Проекция выборок на прямую.
среднее значение d-мерной выборки, заданное как
![]() (67)
(67)
то среднее значение выборки для спроецированных точек задается посредством
![]() (68)
(68)
Отсюда
следует, что |![]() -
-![]() |=|wt(
|=|wt(![]() —
—![]() )|
и что мы можем сделать эту разность
сколь угодно большой, просто масштабируя
w. Конечно,
чтобы получить хорошее разделение
спроецированных данных, мы хотим, чтобы
разность между средними значениями
была велика относительно некоторого
показателя стандартных отклонений
для каждого класса. Вместо получения
дисперсий выборок определим разброс
для спроецированных выборок, помеченных
)|
и что мы можем сделать эту разность
сколь угодно большой, просто масштабируя
w. Конечно,
чтобы получить хорошее разделение
спроецированных данных, мы хотим, чтобы
разность между средними значениями
была велика относительно некоторого
показателя стандартных отклонений
для каждого класса. Вместо получения
дисперсий выборок определим разброс
для спроецированных выборок, помеченных
![]() ,
посредством
,
посредством
![]() . (69)
. (69)
Таким
образом, (l/n)(![]() +
+
![]() )
является оценкой дисперсии совокупности
данных, a
)
является оценкой дисперсии совокупности
данных, a
![]() +
+
![]() называется полным разбросом
внутри класса
спроецированных выборок. Линейный
дискриминант Фишера тогда
определяется как такая линейная
разделяющая функция 7
wtx,
для которой функция
критерия
называется полным разбросом
внутри класса
спроецированных выборок. Линейный
дискриминант Фишера тогда
определяется как такая линейная
разделяющая функция 7
wtx,
для которой функция
критерия
![]() (70)
(70)
максимальна.
Чтобы получить J как явную функцию от w, определим матрицы разброса Si и Sw посредством
![]() (71)
(71)
и
SW =S1+S2 (72)
Тогда
![]() (73)
(73)
так что
![]() +
+
![]() =
=![]() (74)
(74)
Аналогично
(![]() -
-![]() )=
)=![]() (75)
(75)
где
![]() =
=![]() . (76)
. (76)
Матрица
![]() называется матрицей
разброса внутри класса. Она
пропорциональна ковариационной
выборочной матрице для совокупности
d-мерных
данных. Она будет симметричной,
положительно полуопределенной и,
как правило, невырожденной, если n>d.
называется матрицей
разброса внутри класса. Она
пропорциональна ковариационной
выборочной матрице для совокупности
d-мерных
данных. Она будет симметричной,
положительно полуопределенной и,
как правило, невырожденной, если n>d.
![]() называется
матрицей
разброса между классами.
Она также симметричная и положительно
полуопределенная, но из-за того, что
она является внешним произведением
двух векторов, ее ранг будет самое
большее единица. В частности, для любого
w
направление
называется
матрицей
разброса между классами.
Она также симметричная и положительно
полуопределенная, но из-за того, что
она является внешним произведением
двух векторов, ее ранг будет самое
большее единица. В частности, для любого
w
направление
![]() w
совпадает с направлением
w
совпадает с направлением
![]() —
—![]() и
и
![]() —
вполне вырожденная матрица.
—
вполне вырожденная матрица.
При
помощи
![]() и
и
![]() функцию критерия J
можно представить в виде
функцию критерия J
можно представить в виде
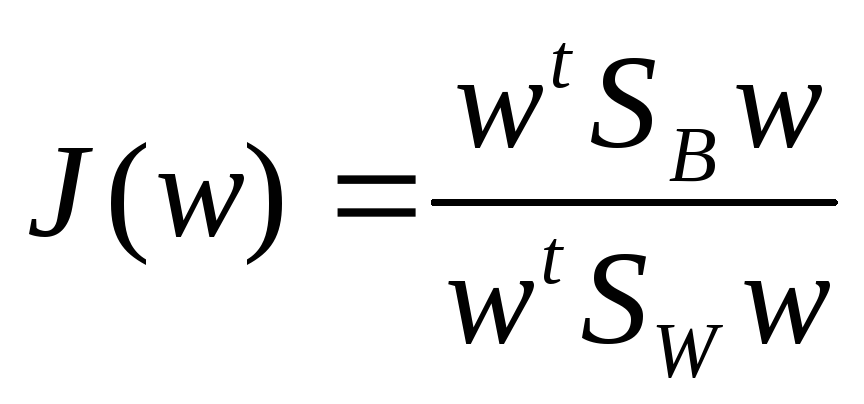 (77)
(77)
Это выражение хорошо известно в математической физике как обобщенное частное Релея. Легко показать, что вектор w, который максимизирует J, должен удовлетворять соотношению
![]() (78)
(78)
что
является обобщенной задачей определения
собственного значения. Если
![]() является невырожденной, мы можем
получить обычную задачу определения
собственного значения, написав
является невырожденной, мы можем
получить обычную задачу определения
собственного значения, написав
![]() (79)
(79)
В
нашем частном случае не нужно находить
собственные значения и собственные
векторы
![]() из-за того,
что направление
из-за того,
что направление
![]() w
всегда совпадает с направлением
w
всегда совпадает с направлением
![]() —
—![]() .
Поскольку масштабный множитель для
w
несуществен, мы можем сразу написать
решение
.
Поскольку масштабный множитель для
w
несуществен, мы можем сразу написать
решение
![]() (80)
(80)
Таким
образом, мы получили линейный дискриминант
Фишера
— линейную
функцию с максимальным отношением
разброса между классами к разбросу
внутри класса. Задача была преобразована
из d-мерной
в более приемлемую одномерную. Это
отображение п-мерного
множества на одномерное, и теоретически
оно не может уменьшить минимально
достижимый уровень ошибки. В общем мы
охотно жертвуем некоторыми теоретически
достижимыми результатами ради
преимущества работы в одномерном
пространстве. Когда же условные плотности
распределения p(x|![]() )
являются многомерными нормальными
с равными ковариационными матрицами
)
являются многомерными нормальными
с равными ковариационными матрицами
![]() ,
то даже
не нужно ничем жертвовать. В этом случае
мы вспоминаем, что граница оптимальных
решений удовлетворяет уравнению
,
то даже
не нужно ничем жертвовать. В этом случае
мы вспоминаем, что граница оптимальных
решений удовлетворяет уравнению
wtx+=0
где
![]()
и
есть константа, включающая в себя
w и априорные
вероятности. Если мы используем средние
значения и ковариационную матрицу
выборок для оценки
![]() и
и
![]() ,
то получаем вектор в том же направлении,
что и
w,
удовлетворяющий
(80), который
максимизирует
J.
,
то получаем вектор в том же направлении,
что и
w,
удовлетворяющий
(80), который
максимизирует
J.
Таким
образом, для нормального случая с
равными ковариациями оптимальным
решающим правилом будет просто решение
![]() ,
если линейный дискриминант Фишера
превышает некоторое пороговое значение,
и решение
,
если линейный дискриминант Фишера
превышает некоторое пороговое значение,
и решение
![]() — в
противном случае.
— в
противном случае.