

43
Применение нейросетей в распознавании изображений
Про нейронные сети, как один из инструментов решения трудноформализуемых задач уже было сказано достаточно много. И здесь, на хабре, было показано, как эти сети применять для распознавания изображений, применительно к задаче взлома капчи. Однако, типов нейросетей существует довольно много. И так ли хороша классическая полносвязная нейронная сеть (ПНС) для задачи распознавания (классификации) изображений?
1. Задача
Итак, мы собрались решать задачу распознавания изображений. Это может быть распознавание лиц, объектов, символов и т.д. Я предлагаю для начала рассмотреть задачу распознавания рукописных цифр. Задача эта хороша по ряду причин:
Для распознавания рукописного символа довольно трудно составить формализованный (не интеллектуальный) алгоритм и это становится понятно, стоит только взглянуть на одну и туже цифру написанную разными людьми
Задача довольно актуальна и имеет отношение к OCR (optical character recognition)
Существует свободно распространяемая база рукописных символов, доступная для скачивания и экспериментов
Существует довольно много статей на эту тему и можно очень легко и удобно сравнить различные подходы
В
качестве входных данных предлагается
использовать базу данных MNIST.
Эта база содержит 60 000 обучающих пар
(изображение — метка) и 10 000 тестовых
(изображения без меток). Изображения
нормализованы по размеру и отцентрованы.
Размер каждой цифры не более 20х20, но
вписаны они в квадрат размером 28х28.
Пример первых 12 цифр из обучающего
набора базы MNIST приведен на рисунке:
 Таким
образом задача формулируется следующим
образом: создать и обучить нейросеть
распознаванию рукописных символов,
принимая их изображения на входе и
активируя один из 10 выходов. Под
активацией будем понимать значение 1
на выходе. Значения остальных выходов
при этом должны (в идеале) быть равны
-1. Почему при этом не используется шкала
[0,1] я объясню позже.
Таким
образом задача формулируется следующим
образом: создать и обучить нейросеть
распознаванию рукописных символов,
принимая их изображения на входе и
активируя один из 10 выходов. Под
активацией будем понимать значение 1
на выходе. Значения остальных выходов
при этом должны (в идеале) быть равны
-1. Почему при этом не используется шкала
[0,1] я объясню позже.
2. «Обычные» нейросети.
Большинство
людей под «обычными» или «классическими»
нейросетями понимает полносвязные
нейронные сети прямого распространения
с обратным распространением ошибки:
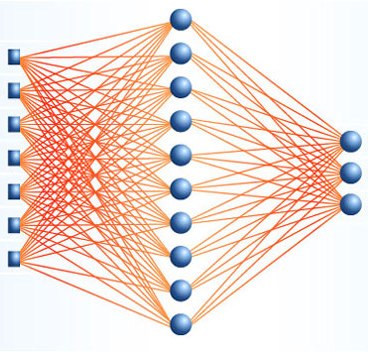 Как
следует из названия в такой сети каждый
нейрон связан с каждым, сигнал идет
только в направлении от входного слоя
к выходному, нет никаких рекурсий. Будем
называть такую сеть сокращенно ПНС.
Сперва
необходимо решить как подавать данные
на вход. Самое простое и почти
безальтернативное решение для ПНС —
это выразить двумерную матрицу изображения
в виде одномерного вектора. Т.е. для
изображения рукописной цифры размером
28х28 у нас будет 784 входа, что уже не мало.
Дальше происходит то, за что нейросетевиков
и их методы многие консервативные ученые
не любят — выбор архитектуры. А не любят,
поскольку выбор архитектуры это чистое
шаманство. До сих пор не существует
методов, позволяющих однозначно
определить структуру и состав нейросети
исходя из описания задачи. В защиту
скажу, что для трудноформализуемых
задач вряд ли когда-либо такой метод
будет создан. Кроме того существует
множество различных методик редукции
сети (например OBD [1]), а также разные
эвристики и эмпирические правила. Одно
из таких правил гласит, что количество
нейронов в скрытом слое должно быть
хотя бы на порядок больше количества
входов. Если принять во внимание что
само по себе преобразование из изображения
в индикатор класса довольно сложное и
существенно нелинейное, одним слоем
тут не обойтись. Исходя из всего
вышесказанного грубо прикидываем, что
количество нейронов в скрытых слоях у
нас будет порядка 15000 (10 000 во 2-м слое
и 5000 в третьем). При этом для конфигурации
с двумя скрытыми слоями количество
настраиваемых и обучаемых связей
будет 10 млн. между входами и первым
скрытым слоем + 50 млн. между первым и
вторым + 50 тыс. между вторым и выходным,
если считать что у нас 10 выходов, каждый
из которых обозначает цифру от 0 до 9.
Итого грубо 60 000 000 связей. Я не зря
упомянул, что они настраиваемые — это
значит, что при обучении для каждой из
них нужно будет вычислять градиент
ошибки.
Ну это ладно, что уж тут
поделаешь,
Как
следует из названия в такой сети каждый
нейрон связан с каждым, сигнал идет
только в направлении от входного слоя
к выходному, нет никаких рекурсий. Будем
называть такую сеть сокращенно ПНС.
Сперва
необходимо решить как подавать данные
на вход. Самое простое и почти
безальтернативное решение для ПНС —
это выразить двумерную матрицу изображения
в виде одномерного вектора. Т.е. для
изображения рукописной цифры размером
28х28 у нас будет 784 входа, что уже не мало.
Дальше происходит то, за что нейросетевиков
и их методы многие консервативные ученые
не любят — выбор архитектуры. А не любят,
поскольку выбор архитектуры это чистое
шаманство. До сих пор не существует
методов, позволяющих однозначно
определить структуру и состав нейросети
исходя из описания задачи. В защиту
скажу, что для трудноформализуемых
задач вряд ли когда-либо такой метод
будет создан. Кроме того существует
множество различных методик редукции
сети (например OBD [1]), а также разные
эвристики и эмпирические правила. Одно
из таких правил гласит, что количество
нейронов в скрытом слое должно быть
хотя бы на порядок больше количества
входов. Если принять во внимание что
само по себе преобразование из изображения
в индикатор класса довольно сложное и
существенно нелинейное, одним слоем
тут не обойтись. Исходя из всего
вышесказанного грубо прикидываем, что
количество нейронов в скрытых слоях у
нас будет порядка 15000 (10 000 во 2-м слое
и 5000 в третьем). При этом для конфигурации
с двумя скрытыми слоями количество
настраиваемых и обучаемых связей
будет 10 млн. между входами и первым
скрытым слоем + 50 млн. между первым и
вторым + 50 тыс. между вторым и выходным,
если считать что у нас 10 выходов, каждый
из которых обозначает цифру от 0 до 9.
Итого грубо 60 000 000 связей. Я не зря
упомянул, что они настраиваемые — это
значит, что при обучении для каждой из
них нужно будет вычислять градиент
ошибки.
Ну это ладно, что уж тут
поделаешь, красота искусственный
интеллект требует жертв. Но вот если
задуматься, на ум приходит, что когда
мы преобразуем изображение в линейную
цепочку байт, мы что-то безвозвратно
теряем. Причем с каждым слоем эта потеря
только усугубляется. Так и есть — мы
теряем топологию изображения, т.е.
взаимосвязь между отдельными его
частями. Кроме того задача распозравания
подразумевает умение нейросети быть
устойчивой к небольшим сдвигам, поворотам
и изменению масштаба изображения, т.е.
она должна извлекать из данных некие
инварианты, не зависящие от почерка
того или иного человека. Так какой же
должна быть нейросеть, чтобы быть не
очень вычислительно сложной и, в тоже
время, более инвариантной к различным
искажениям изображений?