

Работа № 2. Методы поиска
Одним из начальных этапов развития систем искусственного интеллекта было решение с помощью компьютера различных игровых задач и головоломок. Фундаментальная идея которая была выработана в результате получила название поиска в пространстве состояний. Она заключается в том, что множество задач можно сформулировать следующим образом:
-
начальное состояние проблемы;
-
тест завершения – проверка, найдено ли решение проблемы;
-
множество операций, которые можно использовать для перехода из текущего состояния в следующее.
Базовый алгоритм порождения новых состояний называется generate-and-test (алгоритм порождения и проверки). Его шаги:
-
создать новое состояние, изменив существующее применением операции из допустимого множества операций;
-
проверить не является ли вновь созданное состояние решением, если не является вернуться к шагу 1 и породить новое состояние.
Этот алгоритм имеет две основных модификации: поиск в глубину, и поиск в ширину. Алгоритм поиска в ширину отыскивает на графе пространства состояний решение, путь к которому – кратчайший (если такое решение существует). Алгоритм поиска в глубину ищет более специфичные решения, и помогает быстрее найти решение в конечном пространстве состояний, но если пространство состояний не является конечным алгоритм, выполняясь бесконечно, может не найти решения вообще.
Цель данной лабораторной работы применить методы поиска в глубину и в ширину, метод эвристического поиска.
Задачи работы:
-
Сформулировать поставленную задачу в терминах пространства состояний: выделить исходное состояние, целевое состояние, определить дозволенные ходы и ограничения.
-
Построить граф пространства состояний для указанного в варианте метода поиска.
-
Определить на CLIPS структуру (структуры) для фреймового представления текущего состояния.
-
Определить на CLIPS структуру и правила перехода (в зависимости от задачи – структура может не понадобиться) для допустимых шагов и ограничений в соответствие с указанным в варианте методом поиска.
-
Определить правило, которое опознает конечное состояние.
-
В результате 1-5 должна получиться система, которая почему-то не работает. Выяснить почему не работает, воспользовавшись отладчиком CLIPS.
-
Предложить варианты эвристической оценки состояний. Для выбранного варианта, реализовать функцию и правило, которое позволило бы осуществлять направленный эвристический поиск.
Пример. Рассмотрим решение поставленных задач на примере головоломки пятнашки (поле 3*3). Метод поиска – поиск в глубину.
-
Сформулировать поставленную задачу в терминах пространства состояний: выделить исходное состояние, целевое состояние, определить дозволенные ходы и ограничения.
Задача: «Пятнашки (поле 3 х 3)»
Метод: поиск в глубину
|
И |
состояние: |
 сходное
состояние:
сходное
состояние:
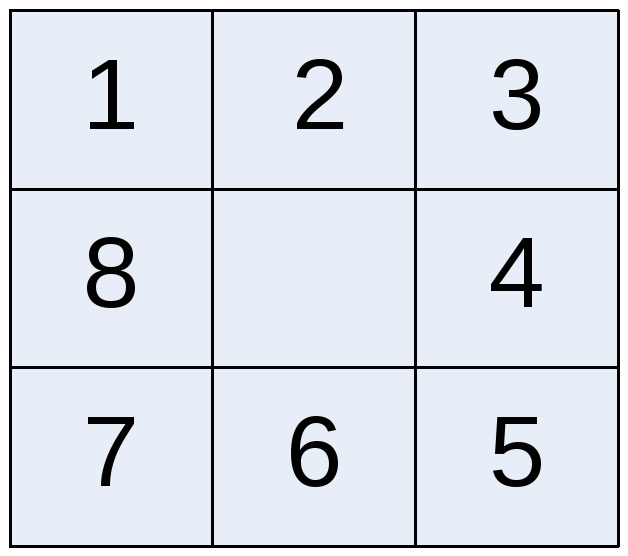 Целевое
Целевое
Дозволенные ходы: освободить поле выше, ниже, слева, справа
Ограничения: нельзя освободить поле по диагонали.
-
Построить граф пространства состояний для указанного в варианте метода поиска.

Рисунок 5. Фрагмент графа пространства состояний для игры "Пятнашки"
-
Определить на CLIPS структуру (структуры) для фреймового представления текущего состояния.
Представить пространство состояний разбираемого примера можно различными способами. В любом случае необходим фрейм игрового поля. Но он может быть организован по-разному. Во-первых, можно создать фрейм, соответствующий постановке задачи, то есть полю для пятнашек 3*3, в котором каждая ячейка на поле характеризуется номером (вроде бы номер и не нужен, поскольку присутствует в имени следующего слота-идентификатора, но извлекать его оттуда – не очень просто, хотя и можно; поэтому лучше ввести в виде значения слота идентификатора), числом, которое в настоящее время располагается в нумерованной ячейке, и индикатором, занята ячейка или нет. Выглядеть это будет примерно так:
(deftemplate puzzle
(slot ID (type INTEGER) (range 1 9))
(slot Used (type SYMBOL) (allowed-values yes no))
(slot Number (type INTEGER) (range 1 9))
)
После того, как структура создана, необходимо создать её экземпляр. Воспользуемся для этого конструкцией deffacts. Конструкция deffacts позволяет определить набор фактов которые будут автоматически размещены в базе фактов при выполнении команды reset. Помещаемые посредством этой конструкции факты – те же самые, что помещаются с помощью функции assert, оперировать с ними можно посредством любой из функций для работы с фактами, предоставляемых CLIPS. Синтаксис конструкции таков:
(deffacts <Наименование конструкции> [<Комментарий>]
<Факт>*)
Примем для себя, что ячейки пронумерованы (то есть их поле ID заполнено) в порядке, в котором они расположены в собираемой цепочке.
|
1 |
2 |
3 |
|
8 |
9 |
4 |
|
7 |
6 |
5 |
Соответственно конструкция, создающая ячейки игрового поля-экземпляры puzzle будет выглядеть так:
(deffacts Puzzle-facts
(puzzle (ID 1) (Used yes) (Number 2))
(puzzle (ID 2) (Used yes) (Number 8))
(puzzle (ID 3) (Used yes) (Number 3))
(puzzle (ID 4) (Used yes) (Number 4))
(puzzle (ID 5) (Used yes) (Number 5))
(puzzle (ID 6) (Used no))
(puzzle (ID 7) (Used yes) (Number 7))
(puzzle (ID 8) (Used yes) (Number 1))
)
-
Определить на CLIPS структуру и правила перехода (в зависимости от задачи – структура может не понадобиться) для допустимых шагов и ограничений в соответствие с указанным в варианте методом поиска.
Допустимыми ходами для разбираемой головоломки являются освобождение поля выше, ниже, слева или справа. Можно составить следующую таблицу переходов из ячейки в ячейку (см. табл. 3).
Таблица 3. Правила перехода по ячейкам игрового поля для "Восьмерки".
|
Из ячейки |
Можно перейти в ячейки |
|
1 |
2, 8 |
|
2 |
1, 3, 9 |
|
3 |
2, 4 |
|
4 |
3, 5, 9 |
|
5 |
4, 6 |
|
6 |
5, 7, 9 |
|
7 |
6, 8 |
|
8 |
1, 7, 9 |
|
9 |
2, 4, 6, 8 |
Строго говоря, усложнив исходную структуру путём ввода классификации ячеек на угловые, краевые и центральную можно добиться того, что допустимые ходы можно полностью определить в правилах перехода без использования дополнительной структур данных, в которой эти ходы жёстко заданы. Но, здравый смысл подсказывает, что этого делать не стоит, так как более сложными, и, стало быть, более трудоёмкими в отладке станут и правила перехода. Поэтому мы создадим дополнительную структуру (это не аксиома, для других задач, где правила перехода просто формализуются – полностью возложить формализацию переходов вполне приемлемый вариант).
А мы вводим структуру следующего вида:
(deftemplate Step
(slot from (type INTEGER) (range 1 9))
(multislot to (type INTEGER) (range 1 9)))
и добавляем в конструкцию deffacts Puzzle-facts факты, представляющие собой экземпляры возможных ходов:
(deffacts Puzzle-facts
(puzzle … )
(step (from 1) (to 2 8))
(step (from 2) (to 1 3 9))
(step (from 3) (to 2 4))
(step (from 4) (to 3 5 9))
(step (from 5) (to 4 6))
(step (from 6) (to 5 7 9))
(step (from 7) (to 6 8))
(step (from 8) (to 1 7 9))
(step (from 9) (to 2 4 6 8)))
Ни один экземпляр структуры step не определяет диагональных переходов, поэтому ограничение на невозможность освободить поле по диагонали – выполняется. Теперь переходим к правилам выполнения ходов. Формулировка хода в «Восьмёрке» выглядит следующим образом: «Можно передвигать любую цифру на соседнее сверху, снизу, слева или справа пустое поле». На CLIPS это записывается несколько сложнее
(defrule move
?from<-(puzzle (ID ?from_id) (Used yes) (Number ?num))
?to<-(puzzle (ID ?to_id) (Used no) (Number ~?num))
(step (from ?from_id) (to $?to_items&:(member$ ?to_id ?to_items)))
=>
(modify ?from (Used no))
(modify ?to (Used yes) (Number ?num))
)
Теперь то же самое, только с пояснениями.
(defrule move
;находим факт, соответствующий любой занятой ячейке
;в переменную ?from_id сохраняем идентификатор ячейки
;в переменную ?num – число, хранящееся в ячейке
;в переменную ?to – адрес найденного факта
;(кстати, оператор <- означает чтение адреса факта)
?from<-(puzzle (ID ?from_id) (Used yes) (Number ?num))
;находим факт соответствующий любой незанятой ячейке,
;которая не была освобождена на предыдущем ходе
;если ячейка освобождена на предыдущем ходе от того же самого числа,
;то в слоте Number этой ячейки сохранилось это число
; (Number ~?num) – условие неравенства числа, которое мы собираемся
; передвигать –числу от которого была последней освобождена эта ячейка
; так можно избавиться от простых зацикливаний
; а от сложных нельзя – нужно придумывать что-то другое
; в переменную ?to_id сохраняется идентификатор ячейки
?to<-(puzzle (ID ?to_id) (Used no) (Number ~?num))
;находим факт, соответствующий допустимому переходу из
;ячейки ?from_id в одну из ячеек массива $?to_items, содержащегося в слоте to
;(обозначения переменных массивов начинаются на $)
;$?to_items&:(member$ ?to_id ?to_items)) – это условие правильного перехода
;это значит что прочитанная переменная to_items должна содержать в качестве
;одного из элементов ?to_id идентификатор свободной ячейки,
;которую мы собираемся занять на этом ходе
(step (from ?from_id) (to $?to_items&:(member$ ?to_id ?to_items)))
=>
;если все сложные условия выполнились – можно перейти к действиям
;освобождаем ячейку, цифру которой двигали
;модифицируя значение слота Used
(modify ?from (Used no))
;занимаем ячейку, в которую двигали цифру
;говорим что она занята (Used yes) числом ?num (Number ?num)
(modify ?to (Used yes) (Number ?num)))
-
Определить правило, которое опознает конечное состояние.
Конечное состояние для головоломки характеризуется для всех занятых ячеек правилом равенством цифры, которая занимает ячейку, адресу идентификатору ячейки. Формулируется это на первый взгляд просто:
(defrule finish
;если нет ни одной задействованной ячейки в которой не располагалась бы цифра
;равная адресу ячейки
?p1<-(puzzle (ID ?id1&1)(Number ?id1))
?p2<-(puzzle (ID ?id2&2)(Number ?id2))
?p3<-(puzzle (ID ?id3&3)(Number ?id3))
?p4<-(puzzle (ID ?id4&4)(Number ?id4))
?p5<-(puzzle (ID ?id5&5)(Number ?id5))
?p6<-(puzzle (ID ?id6&6)(Number ?id6))
?p7<-(puzzle (ID ?id7&7)(Number ?id7))
?p8<-(puzzle (ID ?id8&8)(Number ?id8))
?p9<-(puzzle (ID ?id9&9))
=>
(printout t ?id1 "||" ?id1 crlf)
(printout t ?id2 "||" ?id2 crlf)
(printout t ?id3 "||" ?id3 crlf)
(printout t ?id4 "||" ?id4 crlf)
(printout t ?id5 "||" ?id5 crlf)
(printout t ?id6 "||" ?id6 crlf)
(printout t ?id7 "||" ?id7 crlf)
(printout t ?id8 "||" ?id8 crlf)
(printout t ?id9 "||" "0" crlf)
(halt))
Или так, не читая конкретных ячеек:
(defrule finish
(not (exists (puzzle (ID ?id) (Used yes) (Number ~?id))))
=>
;но тогда мы уже не можем вывести на печать реального состояния базы фактов
;поэтому всё равно, что печатать
(printout t “Success” crlf)
(halt))
Но в таком случае правило сработает при обнаружении хотя бы одного совпадения. Для того, чтобы представить в CLIPS правило, срабатывающее в случае такого совпадения для всех экземпляров puzzle, присутствующих в базе фактов и соответствующих заполненным ячейкам, необходимо обратить формулировку. Итак, правило должно активизироваться если в базе фактов нет ни одного экземпляра структуры puzzle, соответствующего заполненной ячейке, в котором в момент активизации не помещалась бы цифра, равная адресу ячейки. Для этого воспользуемся логическими элементами условия not и exists.
(defrule finish
(not (exists (puzzle (ID ?id) (Used yes) (Number ~?id))))
=>
(ppdeffacts Puzzle-facts)
(halt))
-
В результате 1-5 должна получиться система, которая почему-то не работает. Выяснить, почему не работает, воспользовавшись отладчиком CLIPS.
К этому шагу всё именно так и получилось: программа формально работает, но решения не находит, а, наоборот, зацикливается. Это немножко неприятно, но дает нам замечательную возможность познакомиться с отладчиком CLIPS. Для Вашего варианта может получиться, что программа работает, но медленно – в этом случае её также необходимо исследовать отладчиком, или даже отлично работает – это, при условии, пошагового выполнения лабораторной работы – чудо, которое тем более интересно исследовать отладчиком. Итак, воспользуемся командой Execution|Watch и включим опции Facts (показывать изменения базы фактов) и Rules (показывать активизацию правил). В меню Window выберем Facts (показывать текущее состояние базы фактов) и Agenda (показывать агенду – список правил, которые могут сработать на данном шаге выполнения программы при текущем состоянии базы фактов). Теперь загрузим программу (Load) и инициализируем базу фактов (Reset).
Выглядит всё так:

Рисунок 6. Вот так примерно удобно располагать окна при отладке
Далее приступаем к пошаговому выполнению программы (Execution|Step) см. табл. 4.
Таблица 4. Переходы между состояниями
|
Начальное состояние для операции |
Отладочная информация об операции |
Конечное состояние для операции |
|
|
<== f-7 (puzzle (ID 7)(Used yes) (Number 7)) ==> f-18 (puzzle (ID 7) (Used no) (Number 7)) <== f-6 (puzzle (ID 6) (Used no) (Number 1)) ==> f-19 (puzzle (ID 6) (Used yes)(Number 7)) |
|
|
|
<== f-8 (puzzle (ID 8) (Used yes) (Number 1)) ==> f-20 (puzzle (ID 8) (Used no) (Number 1)) <== f-18 (puzzle (ID 7) (Used no) (Number 7)) ==> f-21 (puzzle (ID 7)(Used yes) (Number 1)) |
|
|
|
<== f-1 (puzzle (ID 1) (Used yes) (Number 2)) ==> f-22 (puzzle (ID 1) (Used no) (Number 2)) <== f-20 (puzzle (ID 8) (Used no) (Number 1)) ==> f-23 (puzzle (ID 8) (Used yes)(Number 2)) |
|




Отсюда и дальнейшего хода выполнения программы понятно, что в нынешнем своём виде программа просто передвигает пустую ячейку по часовой стрелке, реализуя, строго говоря, поиск в глубину, но без исключения уже пройденных состояний. Помимо этого недостатка переход между состояниями ничем не направляется, то есть состояние игрового поля, в отсутствие оценки качества совершаемых ходов, может произвольно удаляться от цели или приближаться к ней.
Варианты решения перечисленных проблем – следующие:
-
сохранять предыдущие состояния – для того чтобы избежать возврата к ним;
-
реализовать generate-and-test в чистом виде, то есть порождать состояния и записывать их в список непосещённых; а при осуществлении перехода – переводить в список посещённых;
-
задать предельное значение глубины поиска – если это предельное значение превышено, начинать поиск с какого-нибудь состояния, не возвращаясь к пройденным состояниям;
-
организовать поиск с итерационным заглублением, когда на первом этапе поиск ограничен глубиной в один уровень, если цель не достигнута, то выполняется ещё один шаг с предельной глубиной 2;
-
организовать эвристический поиск: ввести оценочную функцию для каждого состояния, для того чтобы осуществлять переходы только от худшего состояния – к лучшему.
Есть еще нечестные варианты, при реализации которых мы как бы заранее знаем, как проще всего решать задачу, например, задать приоритеты операций, видя какой путь по дереву приводит к результату. Такие варианты мы рассматривать здесь не будем.
Итак, для того, чтобы просто усовершенствовать поиск в глубину нам необходимо создать механизм сохранения предыдущих состояний и, например, возвращаться из любого тупикового состояния к предыдущему.
Для этого введем ещё одну структуру для хранения пройденных состояний:
(deftemplate state
;идентификатор состояния
(slot ID (type INTEGER) (default 0))
;состав состояния – элементы размещены местам на поле соответствующим
;индексам в массиве
(multislot numbers (default 0 0 0 0 0 0 0 0 0))
;флаг - является состояние последним или нет
(slot last (type SYMBOL) (allowed-values yes no))
)
;и набор фактов для этой структуры
(deffacts states
(state (ID 0) (last yes)))
и усовершенствуем правило передвижения, таким образом, чтобы оно проверяло не находилось ли уже игровое поле в том состоянии, в которое его собирается перевести система:
(defrule move
?from<-(puzzle (ID ?from_id) (Used yes) (Number ?num))
?to<-(puzzle (ID ?to_id) (Used no) (Number ~?num))
(step (from ?from_id) (to $?to_items))
;читаем последнее состояние
?st<-(state (last yes) (ID ?state_id) (numbers $?some_nums))
;проверяем – является ли переход из поля ?from_id к полю ?to_id допустимым
;ходом
(test (member$ ?to_id $?to_items))
;убеждаемся, что для всех состояний, кроме последнего (возврат к последнему
;- и так проверяется
(forall (state (ID ~?state_id) (numbers $?nums&~$?some_nums))
;замена в последнем состоянии двух элементов, соответствующих ходу
;не переводит его в одно из существующих состояний, которые представлены
;переменной ?nums
(test (neq (replace$ (replace$ $?some_nums ?to_id ?to_id ?num)
?from_id ?from_id 0) ?nums)))
=>
;создаем новое последнее состояние
(modify ?st (last no))
(assert (state (last yes) (ID (+ ?state_id 1))))
;делаем ход
(modify ?from (Used no))
(modify ?to (Used yes) (Number ?num))
)
Заметим, что приведённое правило move сработает только в том случае если в базе фактов присутствуют два состояния с различными идентификаторами, стало быть перемещения из начального состояния оно осуществить не сможет. Поэтому (и для того чтобы не усложнять правило move) введём правило первого хода movefirst.
(defrule movefirst
;правило в общем работает так же как и move
?from<-(puzzle (ID ?from_id) (Used yes) (Number ?num))
?to<-(puzzle (ID ?to_id) (Used no) (Number ~?num))
(step (from ?from_id) (to $?to_items))
?st<-(state (last yes) (ID ?state_id) (numbers $?some_nums))
;но только в тех случаях когда в базе фактов нет ничего кроме начального
;состояния – что и обозначает следующее выражение
(forall (state (ID 0) (numbers $?nums)) (state (ID 0) (numbers $?some_nums)))
=>
(modify ?st (last no) (status closed))
(modify ?from (Used no))
(modify ?to (Used yes) (Number ?num))
(assert (state (last yes) (ID (+ ?state_id 1)))))
Но этого недостаточно – в системе теперь необходимы ещё два элемента: один выполнял бы сохранение состояния, а другой откидывал из тупикового состояния в любое другое, например, предыдущее. Правило сохранения состояния может выглядеть, например, так:
(defrule savestate
(declare (salience 10))
;читаем ячейку поля
?p<-(puzzle (ID ?id) (Used yes) (Number ?num))
;читаем последнее состояние
?st<-(state (last yes) (numbers $?nums))
;убеждаемся, что номер, расположенный в ячейке ещё не является частью
;состояния
(not (test (member$ ?num ?nums)))
=>
;вставляем в ?nums – состав текущего состояния
;новый элемент ?num по адресу ?id
;на самом деле здесь можно было обойтись replace$
;это просто, чтоб познакомиться с функциями
(bind ?nums (delete$ ?nums ?id ?id))
(bind ?nums (insert$ ?nums ?id ?num))
;обновляем состав состояния
(modify ?st (numbers ?nums) (status open))
)
Правило эвакуации из тупиковых состояний может выглядеть так:
(defrule reinit
(declare (salience -1))
;если мы не нашли решения
;то есть номера не расставлены в ячейках, так чтобы совпадать с адресом
(exists (puzzle (ID ?id&~9) (Used yes) (Number ~?id)))
;читаем ячейки
?p1<-(puzzle (ID 1))
?p2<-(puzzle (ID 2))
?p3<-(puzzle (ID 3))
?p4<-(puzzle (ID 4))
?p5<-(puzzle (ID 5))
?p6<-(puzzle (ID 6))
?p7<-(puzzle (ID 7))
?p8<-(puzzle (ID 8))
?p9<-(puzzle (ID 9))
;читаем последнее состояние
?last_st<-(state (ID ?x1) (last yes))
;читаем предпоследнее состояние
?st0<-(state (ID ?x2&:(= ?x2 (- ?x1 2))) (numbers $?nums))
=>
;говорим, что предпоследнее состояние стало последним
(modify ?st0 (last yes))
(modify ?last_st (last no))
;модифицируем ячейки в соответствие с предпоследним состоянием
(modify ?p1 (Used yes) (Number (nth$ 1 ?nums)))
(modify ?p2 (Used yes) (Number (nth$ 2 ?nums)))
(modify ?p3 (Used yes) (Number (nth$ 3 ?nums)))
(modify ?p4 (Used yes) (Number (nth$ 4 ?nums)))
(modify ?p5 (Used yes) (Number (nth$ 5 ?nums)))
(modify ?p6 (Used no))
(modify ?p7 (Used yes) (Number (nth$ 6 ?nums)))
(modify ?p8 (Used yes) (Number (nth$ 7 ?nums)))
(modify ?p9 (Used yes) (Number (nth$ 8 ?nums)))
)
Хочется обратить внимание, на выражение
(declare (salience n))
присутствующее в двух последних правилах. Salience (-10000 … 10000, по умолчанию 0) – это приоритет правила. Если механизм логического вывода имеет возможность выполнить в заданный момент времени более чем одно правило, то из конкурирующих правил будет выбрано то, приоритет которого – выше. Задавая правилу savestate более высокий приоритет мы добиваемся того, чтобы прежде чем сделать ход система сохранила предыдущее состояние. Правилу reinit задаётся низший по сравнению с остальными приоритет для того, чтобы оно выполнялось только в том случае, если состояние базы фактов не позволяет выполнить никаких других правил, то есть только в тупиковых состояниях.
Перечисленные правила – работают, можно проверить. Но решение ищется крайне долго и неэффективно. Конечно, можно ещё поработать над способом поиска в глубину, например, реализовать итерационное заглубление, но лучше всего – попробовать ввести какой-либо сравнительный критерий качества состояний.
-
Предложить варианты эвристической оценки состояний. Для выбранного варианта, реализовать функцию и правило, которое позволило бы осуществлять направленный эвристический поиск.
В нашем случае существует три варианта возможных эвристических функций оценки качества состояний. Для каждого состояния можно оценить:
-
количество фишек, находящихся не на своих местах;
-
сумму расстояний до целевого состояния, для фишек, находящихся не на своих местах;
-
количество прямых перестановок фишек (то есть, тех случаев, когда нужно поменять местами соседние фишки) до достижения целевого состояния: чем больше это число, тем «хуже» состояние, поскольку две соседние фишки могут поменяться местами минимум за три хода – данная эвристика, в отличие от предыдущих учитывает трудности при перестановке фишек.
Можно также использовать сочетание этих эвристик, так как в разных случаях они дают различные результаты.
Для того чтобы реализовать эвристику следует воспользоваться CLIPS-функциями. Функция в CLIPS – поименованная часть исполняемого кода, которая возвращает какое-то значение, или выполняет какое-либо действие. CLIPS предлагает несколько типов функций. Пользовательские (user defined) и системные (system defined) функции пишутся на языках процедурного программирования. Первые определяются в пользовательском коде на процедурных языках, после чего CLIPS пересобирается и перекомпилируется с вновь написанным кодом. Вторые существуют в коде реализации CLIPS. Конструкции deffunction и defgeneric позволяют определять функции, используя среду CLIPS. Такие функции не выполняются непосредственно, как в случае пользовательских и системных функций, а интерпретируются средой CLIPS. Функции, определенные с помощью deffunction, не могут быть перегружены. Во время выполнения функции действия выполняются в определенном пользователем порядке. Функция возвращает значение, которое является результатом последнего вычисленного выражения. Если последнее действие функции не возвращает никакого результата, то функция вернет FALSE.
В CLIPS также существуют родовые функции (generic functions). Для их объявления используются ключевые слова defgeneric и defmethod. Такие функции похожи на объявленные с помощью deffunction. Они так же позволяют создавать процедурный код непосредственно в среде CLIPS и вызываются тем же способом. Однако родовые функции обладают более широкими возможностями: они могут быть переопределяемыми, то есть выполнять разные действия в зависимости от количества переданных параметров и их типов. Родовые функции состоят из нескольких компонентов, называемых методами. Каждый из методов обрабатывает свои аргументы отличные от других методов той же функции. Всвязи с дополнительной возможностью переопределения при вызове общих функций CLIPS используется несколько иной внутренний механизм: сначала определяется, что была вызвана общая функция, затем по набору аргументов ищется подходящий метод, после чего найденный метод выполняется. Объявление родовой функции состоит из имени функции и нескольких методов (defmethod). В объявление каждого метода включается имя, индекс и комментарий (необязательные), параметры типизированные или нетипизированные, необязательный параметр-массив (для того, чтобы иметь возможность обрабатывать любое число параметров), тело функции – последовательность действий, которая выполняется при вызове. Для параметров также может быть определено ограничение, которому должен соответствовать параметр, чтобы вызывался именно этот метод. В качестве ограничения можно использовать глобальную переменную или вызов функции. Ограничение считается удовлетворенным, если при его вычислении было получено любое не-False значение. Имя общей функции необходимо для ее идентификации. Если использовать defmethod без defgeneric, то создается имя по умолчанию. Методы уникальным образом определяются по имени и индексу (индекс может быть назначен программистом или формироваться автоматически). Для каждой комбинации параметров определяется новый метод.
Реализовать функцию для выбранной эвристики и внедрить её в правило перемещения предлагается самостоятельно.