

-
Классификация структур данных по различным признакам
Всю совокупность данных можно разделить на две большие группы: данные статической структуры и данные динамической структуры.
Данные статической структуры характеризуются тем, что взаимное положение и взаимосвязь элементов структуры всегда остаются постоянными. Данные статической структуры могут быть простыми (скалярными) и составными, которые формируются из простых структур по какому-либо закону.
Данные динамической структуры – это данные, внутреннее строение которых формируется по какому-либо закону, но количество элементов, их взаиморасположение и взаимосвязи могут динамически изменяться во время выполнения программы согласно закону формирования. К данным динамической структуры относятся файлы, несвязанные и связанные динамические данные.
По различным признакам структуры данных можно классифицировать следующим образом.
-
По отношению к месту хранения:
-
оперативные структуры (во внутренней памяти);
-
файловые структуры (во внешней памяти).
-
По наличию связей между элементами данных:
-
несвязные (векторы, массивы);
-
связные (списковые структуры):
-
односвязные (списки);
-
двусвязные (списки, бинарные деревья);
-
многосвязные (деревья, графы).
-
По признаку изменчивости (возможность изменения числа элементов и связей между ними):
-
статические (векторы, массивы);
-
полустатические (стеки, очереди, реализованные с помощью статических физических структур);
-
динамические (стеки, очереди, реализованные с помощью динамических физических структур, списки).
-
По признаку упорядоченности элементов структуры:
-
линейные (массивы, стеки, очереди, списки);
-
нелинейные (деревья, графы).
-
Типовые операции над структурами данных
1. Операция «создать» создает соответствующую структуру данных. Например, в Паскале переменная и массив могут быть созданы с помощью соответствующих операторов описания, что приводит к выделению адресного пространства для переменной и массива. Процедура New приводит к созданию переменной типа указателя.
2. Операция «уничтожить» приводит к уничтожению созданной структуры данных.
Например, в Паскале структуры данных, созданные внутри блока (процедуры), уничтожаются после выхода из этого блока. Процедура Dispose уничтожает переменную типа указателя.
3. Операция «выбрать» осуществляет доступ к данным внутри самой структуры. Выполнение этой операции зависит от структуры данных. Обращение, например, к переменной или элементу массива в операторе присваивания делает доступной соответствующую область памяти.
4. Операция «обновить» приводит к изменению данных в структуре.
-
Эффективность алгоритмов. O-обозначения
Эффективность алгоритмов зависит от двух факторов:
1) память, требуемая для реализации алгоритма на ПК;
2) время, необходимое для выполнения алгоритма.
Лучший способ сравнения эффективностей алгоритмов состоит в сопоставлении их порядков сложности. Порядок сложности алгоритма выражает его эффективность обычно через количество обрабатываемых данных. Порядок алгоритма – это функция, доминирующая над точным выражением временной сложности. Наиболее часто для выражения порядка сложности алгоритма используется так называемое О-обозначение. В этой нотации порядок сложности функции заключается в скобки, следующие за буквой «О». О-функция выражает относительную скорость алгоритма в зависимости от некоторой переменной. Например, скорость работы алгоритма с временной сложностью O(n) падает пропорционально росту n. Существуют три важных правила для определения сложности:
1) постоянные множители не имеют значения для определения порядка сложности, т.е. O(k·f) =O(f);
2) порядок сложности произведения двух функций равен произведению их сложностей: О(f·g) = O(f)·O(g);
3)
порядок сложности суммы функций равен
порядку доминанты слагаемых, например:
![]() .
.
Приведем список функционального доминирования:
если N и L – переменные, a, b, c, d – константы, то
![]() доминирует над
доминирует над
![]() ;
;
![]() доминирует над
доминирует над
![]() ;
;
![]() доминирует над
доминирует над
![]() ,
если a
> b;
,
если a
> b;
![]() доминирует над
доминирует над
![]() ,
если а
> 0;
,
если а
> 0;
![]() доминирует над
доминирует над
![]() ,
если c
> d;
,
если c
> d;
N
доминирует над
![]() ,
если a
> 1.
,
если a
> 1.
Любой терм с одной переменной N не доминирует ни над каким термом с одной независимой переменной L.
Сложность алгоритма может быть определена исходя из анализа его управляющих структур. Алгоритмы без циклов и рекурсивных вызовов имеют константную сложность. Поэтому определение сложности алгоритма сводится в основном к анализу циклов и рекурсивных вызовов. Рассмотрим алгоритм удаления k-го элемента из массива размером n, состоящий из перемещения элементов массива от (k+1)-го до n-го на одну позицию назад к началу массива и уменьшения числа элементов n на единицу. Сложность цикла обработки массива составляет О(n – k), т.к. тело цикла (операция перемещения) выполняется n – k раз и сложность тела цикла равна О(1), т.е. является константой. Тип цикла (for, while, repeat) не влияет на сложность. Если один цикл вложен в другой и оба цикла зависят от размера одной и той же переменной, то вся конструкция характеризуется квадратичной сложностью. Вложенность повторений является основным фактором роста сложности. В качестве примера приведем сложность хорошо известных алгоритмов поиска и сортировки для массива размером n:
-
последовательный поиск:
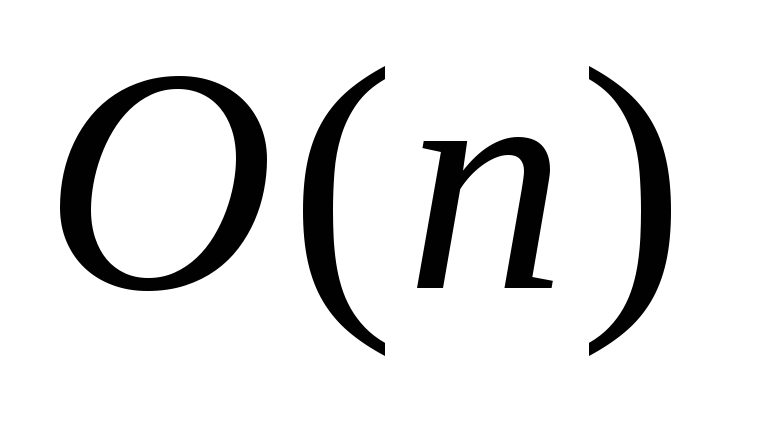 ;
; -
бинарный поиск:
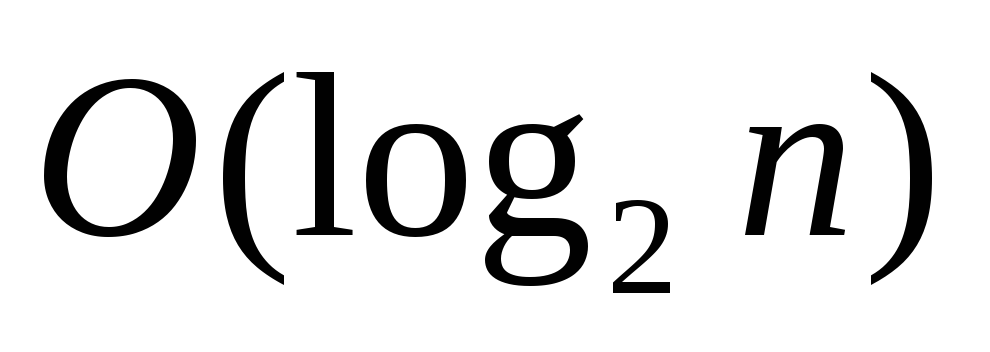 ;
; -
пузырьковая сортировка:
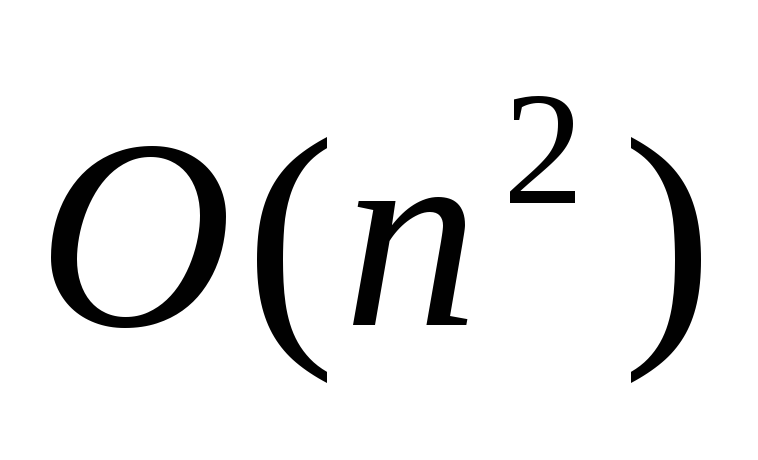 .
.
При изучении алгоритмов в последующих темах будут приведены оценки их сложности.