

Федеральное агентство по образованию
ГОСУДАРСТВЕННОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
Рязанский государственный радиотехнический университет
СТРУКТУРЫ И АЛГОРИТМЫ
ОБРАБОТКИ ДАННЫХ
Поиск. Сортировка. Классы в Delphi
Методические указания
Рязань 2007
Структуры и алгоритмы обработки данных. Поиск. Сортировка. Классы в Delphi: Методические указания / Рязан. гос. радиотехн. ун-т; Сост. В.В. Белов, В.И. Чистякова. Рязань, 2007. 66 с.
Содержит описания двух тем, посвященных изучению различных алгоритмов обработки данных на ЭВМ. Подробно рассмотрены алгоритмы поиска, хеширования и сортировки информации. Приведены задания к двум лабораторным работам. Алгоритмы реализованы на языке Delphi 7 с использованием технологии объектно-ориентированного программирования. В приложениях приведены сведения о возможностях работы в консольном режиме Delphi 7, об особенностях языка программирования Delphi, об обработке исключительных ситуаций в программах на Delphi, о специфике создания объектно-ориентированных программ в Delphi. Предназначены для студентов дневной, вечерней и заочной форм обучения специальности 230105 «Программное обеспечение вычислительной техники и автоматизированных систем» при изучении дисциплины «Структуры и алгоритмы обработки данных».
Библиогр.: 7 назв.
Компьютерный набор и верстка В.И. Чистяковой.
Поиск, расстановка, сортировка, Delphi 7, язык Delphi, обработка исключительных ситуаций, классы.
Печатается по решению методического совета Рязанского государственного радиотехнического университета.
Рецензент: кафедра вычислительной и прикладной математики Рязанского государственного радиотехнического университета (зав. кафедрой д‑р техн. наук, проф. А.Н. Пылькин)
Содержание
Тема 5. Поиск и преобразование ключей 2
Тема 6. Сортировка 18
Приложение 1. Разработка и выполнение программ в консольном режиме Delphi 7 33
Приложение 2. Особенности языка программирования Delphi 36
Приложение 3. Классы в Dephi 47
Библиографический список 63
Тема 5. Поиск и преобразование ключей
-
О
 сновные
понятия и определения
сновные
понятия и определения
Совокупность элементов, среди которых ведется поиск, назовем таблицей, каждый элемент – записью. Для каждой записи определен ключ, используемый для того, чтобы отличать одну запись от другой.
Ключ может быть полем внутри записи – это внутренний ключ.
Ключом может быть относительная позиция записи внутри таблицы, либо существует таблица ключей, содержащая указатели на записи. Такой ключ называется внешним.
Первичный ключ – ключ, являющийся уникальным для каждой записи.
Вторичный ключ – не являющийся уникальным. Несколько записей могут иметь одинаковое значение ключа.
Алгоритм поиска – алгоритм, воспринимающий некоторый аргумент x и локализующий запись с ключом x. Успешный поиск называется извлечением. В случае неудачи алгоритм возвращает или пустую запись, или пустой указатель, или флаг.
Алгоритм поиска и вставки – включает в таблицу новую запись с аргументом x в качестве ключа, если поиск был неудачным.
Для представления элемента таблицы хорошо подходит такая структура данных, как запись, одной из компонент которой является ключ Key элемента, а другими компонентами являются все существенные данные об элементе. Таблицу при этом можно описать как массив a1, a2,.., an из n записей-элементов или как связанный список таких элементов с заголовком Head.
Замечание: во всех приведенных ниже алгоритмы поиска предполагается, что таблица не пуста и установлена директива компилятора {$B-}.
-
Оценка эффективности алгоритмов поиска
Эффективность алгоритмов поиска оценивают по следующим параметрам:
-
объем памяти ЭВМ, кроме памяти, необходимой для хранения таблицы;
-
быстродействие алгоритма, удобной мерой которого является число необходимых для поиска сравнений ключей (C). Эта величина является функцией от n.
-
Последовательный (линейный) поиск
Линейный поиск используется в том случае, если никакой дополнительной информации о разыскиваемых данных нет. Применяется к таблице, организованной как массив или как список. Последовательность шагов поиска в непустой таблице элемента ключом x имеет вид (Search – адрес искомого элемента, Search=0, если элемент не найден):
-
для массива:
i:=1;
while (i<n) and (a[i].Key<>x) do Inc(i);
if a[i].Key=x
then Search:=i
else Search:=0; // i=n и a[n].Key x
-
для списка (в этом и последующих примерах предполагается, что список не пуст):
Item:= Head;
while (Item^.Next<>nil) and (Item^.Key<>x) do Item:= Item^.Next;
if Item^.Key=x
then Search:= Item
else Search:=nil;
Списковая структура является более предпочтительной, если в таблице должно быть сделано много вставок и удалений.
Поиск с включением реализуется следующим образом:
-
для массива необходимо выделить достаточное место в памяти (для последующих включений):
i:=1;
while (i<n) and (a[i].Key<>x) do Inc(i);
if a[i].Key<>x
then begin // элемент в списке отсутствует
i:=n+1; a[i].Key:=x;... // запись в a[i] ключа и других полей
n:=i;
end;
Search:=i;
-
для списка:
Item:= Head;
while (Item^.Next<>nil) and (Item^.Key<>x) do Item:= Item^.Next;
if Item^.Key<>x
then begin // элемент в списке отсутствует
New(Item^.Next);
Item:=Item^.Next;
Item^.Key:=x;
... // запись в Item^ других полей
Item^.Next:=nil;
end;
Search:=Item;
Поиск с барьером. На каждом шаге алгоритма поиска необходимо увеличивать индекс (или сдвигать указатель) и вычислять логическое выражение. Можно ускорить поиск, если упростить логическое выражение. Это можно сделать, если гарантировать, что совпадение ключа текущего элемента с x обязательно произойдет. Для этого в конец массива или списка помещается элемент с ключом x, называемый «барьером», т.к. он охраняет нас от перехода за пределы массива. Последовательность шагов поиска имеет вид:
-
для массива:
a[n+1].Key:=x; // барьер
i:=1;
while a[i].Key<>x do Inc(i);
if i<n+1
then Search:=i
else Search:=0;
-
для списка необходимо определить указатель Rear на конец списка (для эффективного включения в конец списка):
InsertRear(x); // включение x в конец списка – барьер
Item:= Head;
while Item^.Key<>x do Item:= Item^.Next;
if Item^.Next<>nil
then Search:=Item
else Search:=nil;
-
Поиск с переупорядочиванием списка
Эффективность линейного поиска зависит от вероятностей задания различных аргументов поиска. Целесообразно распределять записи в таблице таким образом, чтобы записи с часто используемыми ключами помещались в начало таблицы. При этом среднее число сравнений уменьшится и, возможно, значительно.
Если существует статистическая информация о частоте использования ключей различных записей (например, при построении таблицы операций компилятора), то построение таблицы можно выполнить один раз до осуществления операций поиска.
К сожалению, указанные вероятности ключей редко известны заранее, кроме того, вероятность, с которой заданная запись будет извлекаться, может измениться со временем. Поэтому было бы полезно иметь алгоритм, непрерывно переупорядочивающий таблицу так, что записи, доступ к которым осуществляется более часто, передвигались бы к началу, а редко востребуемые записи перемещались бы к концу.
Метод перемещения в начало является эффективным только для таблицы, организованной как список. В этом методе при успешном поиске извлеченная запись удаляется из своей позиции в списке и помещается в голову списка (очевидно, что операции исключения и включения элементов выполнять не нужно, перемещение реализуется переключением связей между элементами списка). В приведенной ниже схеме Item_1 – указатель элемента, предшествующего элементу с указателем Item (семантика обозначения – на 1 шаг назад от Item), в скобках указан порядок переключений связей.
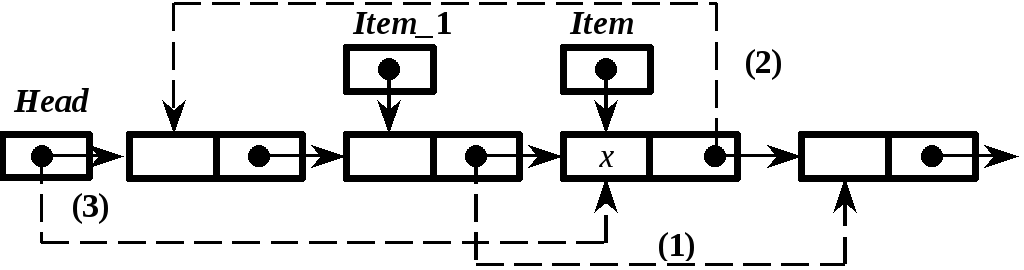
Item:= Head;
Item_1:= nil;
while (Item^.Next<>nil) and (Item^.Key<>x) do begin
Item_1:= Item;
Item:= Item^.Next;
end;
if Item^.Key=x
then begin
if Item_1<>nil
then begin // найденный элемент не первый
Item_1^.Next:= Item^.Next;
Item^.Next:= Head;
Head:= Item; // перемещение
end;
Search:= Item;
end
else Search:= nil;
Метод транспозиции может использоваться для поиска в таблице, организованной как массив и как список, и заключается в том, что извлеченная запись меняется местами с записью, которая ей предшествует:
-
для массива вводится переменная Temp типа элемента массива, через которую выполняется обмен элементами:
i:=1; while (i<n) and (a[i].Key<>x) do Inc(i);
if a[i].Key=x
then begin // элемент найден
if i>1
then begin // элемент не в первой позиции обмен
Temp:= a[i];
a[i]:=a[i-1];
a[i-1]:=Temp;
Dec(i);
end;
Search:=i;
end
else Search:=0;
-
для списка необходимо ввести указатель Item_2 элемента, предшествующего элементу с указателем Item_1 (на 2 шага назад от Item):

Item:= Head; Item_2:= nil; Item_1:= nil;
while (Item^.Next<>nil) and (Item^.Key<>x) do begin
Item_2:= Item_1;
Item_1:= Item;
Item:= Item^.Next;
end;
if Item^.Key=x
then begin
if Item_1<>nil
then begin // найденный элемент не первый
Item_1^.Next:= Item^.Next;
Item^.Next:= Item_1;
if Item_2<>nil
then Item_2^.Next:= Item
else Head:= Item; // элемент второй в списке
end;
Search:= Item;
end
else Search:= nil;
Показано, что метод транспозиции дает более эффективный поиск, чем метод перемещения в начало, для тех списков, в которых вероятность доступа к некоторому элементу остается постоянной во времени. Однако метод транспозиции требует большего времени для достижения максимальной эффективности. Кроме того, метод транспозиции одинаково эффективен и для массивов, и для списков.
-
Поиск в упорядоченной таблице
Бинарный поиск. В отсортированной последовательности выбираем либо левую, либо правую половину для поиска в зависимости от значения ключа среднего элемента в таблице.
В приведенном ниже участке программы Left, Right – левая и правая границы поиска; Middle – середина области поиска.
Left:=1; Right:=n;
while Left<Right do begin
Middle:= (Left+Right) div 2;
if a[Middle].Key<x then Left:=Middle+1 else Right:=Middle;
end;
if a[Right].Key=x
then Search:=Right
else Search:=0;
Если есть элементы с одинаковыми ключами, то алгоритм находит первый из них.
Алгоритм бинарного поиска может быть использован только при хранении таблицы в виде массива, т.к. он использует тот факт, что индексами элементов массива являются последовательные целые числа. По этой же причине бинарный поиск практически бесполезен в ситуациях, где имеется много вставок или удалений.
Индексно-последовательный поиск. В дополнение к отсортированной таблице заводится вспомогательная таблица, называемая индексом. Каждый элемент индекса состоит из ключа Key и указателя Addr на запись в исходной таблице, соответствующую этому ключу. Индекс можно описать как массив Ind1, Ind2, …, Indm из m элементов. Элементы в индексе также отсортированы по ключу Key. Если индекс имеет размер, составляющий одну пятую, например, от размера таблицы, то каждая пятая запись представлена в индексе.
|
|
Индекс |
|
|
Таблица |
||
|
|
Ключ (Key) |
Указатель (Addr) |
|
|
Ключ (Key) |
Другие данные |
|
1 |
28 |
|
|
1 |
5 |
|
|
2 |
54 |
|
|
2 |
11 |
|
|
... |
... |
|
|
... |
17 |
|
|
m |
961 |
|
|
|
21 |
|
|
|
|
|
|
|
28 |
|
|
|
|
|
|
|
29 |
|
|
|
|
|
|
|
40 |
|
|
|
|
|
|
|
42 |
|
|
|
|
|
|
|
49 |
|
|
|
|
|
|
|
54 |
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
800 |
|
|
|
|
|
|
|
961 |
|
|
|
|
|
|
|
1005 |
|
|
|
|
|
|
n |
1021 |
|



Последовательный поиск выполняется сначала по индексу, а затем по части записей самой таблицы, называемой пространством поиска.
Индекс применяется для отсортированной таблицы, представленной и в виде списка, и в виде массива. Использование списка приводит к накладным расходам по пространству для указателей, хотя вставки и удаления могут быть выполнены проще.
Рассмотрим пример с таблицей в виде массива, где Ind, m – имя и размер индекса, a, n – имя и размер таблицы, Low и High – нижняя и верхняя границы поиска в таблице, Key – имя ключевого поля индекса и таблицы, Addr – имя поля-указателя в индексе.
i:=1; while (i<m) and (Ind[i].Key<=x) do Inc(i); // поиск в индексе
// определение нижней границы поиска в таблице:
if i=1 then Low:=1 else Low:=Ind[i-1].Addr;
// определение верхней границы поиска в таблице:
if (i=m) and (Ind[i].Key<=x)
then begin // пространство поиска – конец таблицы
High:=n; Low:=Ind[i].Addr;
end
else High:=Ind[i].Addr-1;
i:=Low; // поиск в таблице от Low до High:
while (i<High) and (a[i].Key<>x) do Inc(i);
if a[i].Key=x
then Search:=i
else Search:=0;
Если в таблице есть несколько элементов с одинаковыми ключами, то алгоритм не обязательно выдает первый из них.
Если использование одного индекса не дает достаточного эффекта, то может быть создан индекс второго уровня – индекс для индекса первого уровня.
Удаления из индексно-последовательной таблицы могут быть сделаны путем отметки удаленных записей. При последовательном поиске в таблице удаленные записи игнорируются, индекс при этом можно не изменять.
Вставка в индексно-последовательную таблицу является более сложной. Обычно по всей таблице расставляются пустые записи (места для вставок), или вставляемые записи связываются между собой, образуя цепочки переполнения.
-
Преобразование ключей (расстановка)
В предыдущих методах организация таблицы была такой, что для поиска нужного ключа нужно было проверить некоторое количество ключей (от n/2 в линейном поиске до log2n в бинарном поиске и поиске по дереву). Желательно иметь такую организацию таблицы, при которой положение записи внутри таблицы зависит только от данного ключа и не зависит от расположения других ключей. При этом исключаются ненужные сравнения.
Простейший случай такой организации таблицы – ключ используется как индекс записи в таблице. Поскольку любой ключ можно преобразовать в целое число, то в принципе это возможно. Однако такая система не всегда имеет практический смысл, так как от числа цифр ключа зависит размер таблицы. Например, для применения прямой индексации с использованием пятизначного ключа потребовался бы массив из 100 тысяч элементов, причем большая часть записей вероятно была бы пустой.
Следовательно, необходим некоторый метод преобразования ключа в целое число внутри ограниченного диапазона, причем в одно и то же число в идеале не должны преобразоваться два разных ключа.
Расстановка – процесс преобразования ключа в целое число внутри некоторого диапазона. Функция h, трансформирующая ключ в некоторый индекс в таблице, называется функцией расстановки. Если Key – некоторый ключ, то h(Key) – значение функции расстановки от ключа Key – индекс, по которому должна быть помещена в таблицу запись с ключом Key. Значения функции h должны покрывать все множество индексов таблицы.
Пусть существуют ключи Key1 и Key2 такие, что h(Key1)=h(Key2). Запись с ключом Key1 помещается в позицию h(Key1) таблицы. Ключ Key2 должен быть помещен на ту же позицию h(Key2). Такая ситуация называется конфликтом или столкновением.
Хорошая функция расстановки минимизирует конфликты и распределяет записи равномерно по всей таблице. Желательно иметь таблицу с размером большим, чем число реальных записей. Чем больше диапазон значений функции расстановки, тем меньше вероятность конфликтов. При этом возникает компромисс между временем и пространством. Мерой использования памяти в таблицах с прямым доступом служит коэффициент заполнения: =n/m (n – число записей; m – размер таблицы).
-
Функции расстановки
Метод деления – наиболее известная функция. Некоторый целый ключ делится на размер таблицы и остаток от деления берется в качестве значения функции: h(Key) = mod(Key, m) + 1, диапазон индексов: 1..m.
Наилучшие результаты для метода деления получаются тогда, когда размер таблицы m является простым числом. Следует в особенности избегать четных m. Удовлетворительные результаты получаются при нечетных значениях m, не имеющих множителей менее 20.
Метод середины квадрата. Ключ умножается сам на себя, и в качестве индекса используется несколько средних цифр результата, причем во всех ключах берутся одни и те же разряды. Если данный квадрат рассматривается как десятичное число, то размер таблицы должен быть степенью 10, если как двоичное – степенью 2.
Пример. Ключ 113586 дает в квадрате число 12901779396. В качестве четырехзначного индекса можно выбрать значение 1779. Причиной возведения в квадрат до извлечения средних цифр ключа является то, что все цифры первоначального числа дают свой вклад в значение средних цифр квадрата.
Метод свертки. Ключ разбивается на части, каждая из которых имеет длину, равную длине требуемого адреса (кроме, возможно, последней части). Части складываются без переноса в старшем разряде. Если ключи представлены в двоичном виде, может быть использовано сложение по модулю 2 (операция «исключающее ИЛИ»: 0+0=0; 0+1=1; 1+0=1; 1+1=0).
Примеры:
а) преобразование ключа 0101110010101102 в пятиразрядный индекс:
разбиение сложение: 01011 11001
010111001010110 +10010 +10110
11001 01111 = 1510 – индекс;
б) преобразование ключа 18724965310 в трехразрядный индекс:
разбиение сложение 187 436
187249653 +249 +653
436 089 – индекс;
в) разновидность свертки – граничное свертывание (перед сложением инвертируются цифры в крайних частях ключа), для ключа 18724965310:
781 030
+249 +356
030 386 – индекс.
Свертывание удобно для сжатия многословных ключей и последующего перехода к другим функциям расстановки.
Преобразование системы счисления – попытка получить случайное распределение ключей по адресам в адресном пространстве.
Ключ, представленный в системе счисления q (обычно q=2 или q=10), рассматривается как число в системе счисления p, где p>q, причем p и q взаимно простые. Это число из системы счисления с основанием p переводится в систему счисления с основанием q, и адрес формируется путем выбора правых цифр или битов нового числа или методом деления.
Например, ключ 53047610, рассматриваемый как 53047611, переводится в десятичную систему счисления следующим образом:
53047611=5115+3114+4112+711+6=84974510.
В качестве трехзначного индекса (диапазон 0..999) выбирается значение 745, четырехзначного (диапазон 0..9999) – 9745.
Алгебраическое кодирование разделяет скопления ключей. Состоящий из r битов ключ (k1, k2, ..., kr) рассматривается как многочлен
K(x)=![]() .
.
Если требуется сформировать адрес в интервале от 0 до m=2t (t-разрядный адрес), то многочлен K(x) делится на другой многочлен
P(x)=![]() ,
,
коэффициенты p которого выбираются произвольно. Получающийся при делении по модулю 2 остаток
mod(k(x),p(x))=![]()
дает адрес (h1h2...ht), где hi – цифры адреса.
Пример. Преобразовать ключ 10100112 (r=7) в четырехразрядный (t=4) двоичный адрес в диапазоне от 0 до 1111=24-1.
K(x)=1x0+0x1+1x2+0x3+0x4+1x5+1x6=x6+x5+x2+1.
P(x)=x4+x2+1 – выбирается произвольно (кроме одночлена xt=x4).
Д еление
многочленов по модулю 2:
еление
многочленов по модулю 2:
x6+x5+ x2+ 1 x4+x2+1
x 6+
x4+ x2 x2+x+1
6+
x4+ x2 x2+x+1
 x5+x4+
1
x5+x4+
1
x5+ x3+ x
 x4+x3+
x+1
x4+x3+
x+1
x4+ x2+ 1
 x3+x2+x
H(x)=0x0+1x1+1x2+1x3
адрес – 01112.
x3+x2+x
H(x)=0x0+1x1+1x2+1x3
адрес – 01112.
Замечание. При делении по модулю 2 вычитание выполняется по правилам:
0–0=0;
1–0=1;
1–1=0;
0–1=1.
Мультипликативная функция. Для неотрицательного целого ключа Key и константы c такой, что 0<c<1, функция определяется в виде h(Key)=[mmod(cKey,1)]+1, где mod(cKey,1) – дробная часть величины cKey; [x] – наибольшее целое, не превышающее x. Функция дает хорошие результаты при правильном выборе c, что можно сделать только исследованием различных вариантов.
-
Методы разрешения конфликтов при расстановке
Функция расстановки часто отображает разные ключи в один и тот же адрес. При этом записи переполнения должны запоминаться в других адресах таблицы, которые определяются с помощью методов устранения конфликтов. Существуют две основных группы таких методов: открытая адресация или повторная расстановка (линейное и случайное опробование, двойная расстановка) и метод цепочек (раздельное и внутреннее сцепление).
Линейное опробование – помещение конкурирующей записи в ближайшую свободную позицию в массиве, причем направление поиска свободной позиции должно быть постоянным, например в сторону увеличения индекса.
Пример. Ключи 3953, 4148, 52, 549, 748, 2350 преобразуются с помощью функции h(Key)=mod(Key,100)+1 для получения индекса в диапазоне 1..100.
Распределение ключей в таблице приведено ниже.
|
Адрес |
Ключ |
|
|
1 |
|
|
|
... |
|
|
|
49 |
4148 |
7 |
|
50 |
549 |
|
|
51 |
748 |
2 |
|
52 |
2350 |
|
|
53 |
52 |
|
|
54 |
3953 |
|
|
... |
|
|
|
100 |
|
|


 48
48


 350
350
Пунктирная линия указывает на позицию, в которую должен помещаться ключ в соответствии со значением функции расстановки, сплошная линия – на позицию, в которую реально помещается ключ в случае конфликта.
Функция повторной расстановки rh воспринимает один индекс в массиве и выдает другой индекс. Если h(Key) занята, то определяется новое значение адреса ключа Key как i=rh(h(Key)). Если ячейка i опять занята, то преобразование выполняется еще раз, и проверяется ячейка с адресом rh(rh(h(Key))). Этот процесс повторяется, пока не будет найдена ячейка, содержащая заранее определенное значение «пусто». Для линейного опробования rh(i)=mod(i,m)+1, т.е. повторное преобразование индекса дает следующую позицию в массиве, замкнутом в кольцо.
В приведенной ниже программе поиска и вставки: x – ключ; h(x) функция расстановки ключа x; rh(i) – функция повторной расстановки адреса i; a, m – имя и размер таблицы; i, j – позиции (адреса) записей в таблице. Отрицательное значение ключа является признаком «пусто».
j:=h(x); i:=j;
// Повторная расстановка:
while (a[i].Key>=0) and (a[i].Key<>x) and (i<>j-1) do i:=rh(i);
if a[i].Key<0
then begin // позиция свободна – вставка
a[i].Key:=x; ... // запись в a[i] ключа и других полей
Search:=i;
end
else begin // позиция занята
if a[i].Key=x
then Search:=i // ключ в таблице есть
else Writeln('Переполнение таблицы');
end;
Для оценки эффективности методов устранения конфликтов используется средняя длина поиска ALOS (предполагается, что каждый ключ отображается в каждый из m адресов таблицы с вероятностью 1/m, т.е. существует mn вариантов отображения ключей в адреса). ALOS зависит от коэффициента заполнения таблицы =n/m (m – число адресов, n – число ключей) и представляет собой число попыток для размещения ключа. Для метода линейного опробования ALOS резко возрастает с ростом :

|
|
ALOS |
|
|
Успех |
Неудача |
|
|
0,10 |
1,056 |
1,117 |
|
0,50 |
1,500 |
2,500 |
|
0,90 |
5,500 |
50,500 |
|
0,95 |
10,500 |
200,500 |
Недостатки метода линейного опробования:
1) трудно выполнять удаление записей, необходимо вводить новый признак – «удаленная запись»; причем удаление большого числа записей приведет к неэффективному использованию таблицы;
2) возникновение эффекта «скучивания» – с возрастанием заполненности таблицы имеет место тенденция возникновения все более длинных последовательностей занятых подряд позиций (первичное скучивание).
Случайное опробование позволяет частично решить проблему первичных скучиваний. В этом методе при повторной расстановке функция rh(i) генерирует не линейную последовательность позиций, а случайную, например, rh(i)=mod(i+c, m)+1, где c и m – взаимно простые числа (если m простое число, то c может быть любым). Диапазон адресов – 1..m.
Для приведенного выше примера (m=100) при i=95 функция rh(i)=mod(i,100)+1 выдает последовательность 96, 97, 98, 99, 100, 1, 2, .., а функция, например, rh(i)=mod(i+41, 100)+1 выдает последовательность 37, 79, 21, 63, 5, 47, ...
Недостаток случайного опробования – вторичное скучивание (возникновение одинаковых последовательностей адресов при преобразовании двух ключей в один и тот же адрес). Возможность устранения этого недостатка – использование еще одной функции расстановки для выбора c.
Двойная расстановка. Пусть первая функция дает одинаковые адреса для различных ключей: h1(Key1)=h1(Key2). Тогда, если есть вторая функция h2 такая, что h1 и h2 являются независимыми и h2(Key1)h2(Key2), то любое из этих значений можно выбрать в качестве смещения c. Характеристики метода двойной расстановки значительно лучше, чем у линейного опробования:
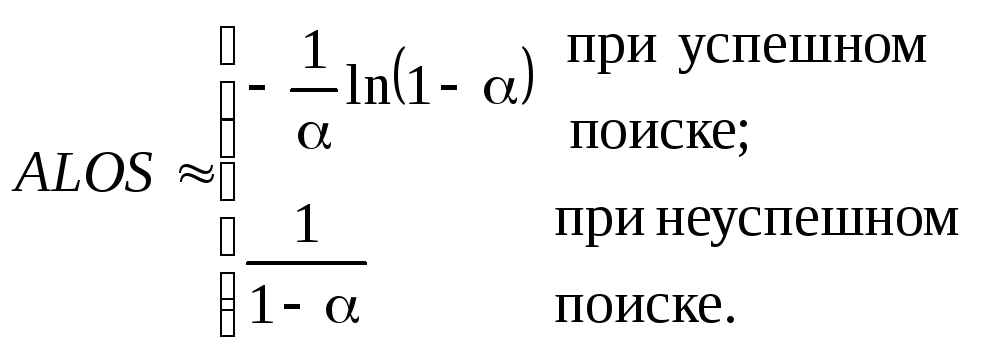
|
|
ALOS |
|
|
Успех |
Неудача |
|
|
0,10 |
1,054 |
1,111 |
|
0,50 |
1,386 |
2,000 |
|
0,90 |
2,558 |
10,000 |
|
0,95 |
3,153 |
20,000 |
Методы открытой адресации нецелесообразно использовать для меняющихся таблиц из-за большой возможности конфликтов и трудности физического удаления записей из таблицы.
Раздельное сцепление. Метод заключается в организации связанного списка из всех записей, чьи ключи преобразуются в один и тот же адрес.
Пусть функция расстановки выдает значения в диапазоне от 1 до m. В этом случае говорят, что ключи распределяются по m классам эквивалентности. Каждый класс хранится в виде связанного списка. Указатели на списки содержатся в массиве длиной m. Запись, попавшая в один из классов эквивалентности, вставляется в начало (или конец) списка.
Пример. Обрабатываются ключи 75, 17, 12, 40, 35, 95, 87. Функция расстановки h(Key)=mod(Key,10).

Характеристики метода раздельного сцепления:

|
|
ALOS |
|
|
Успех |
Неудача |
|
|
0,10 |
1,050 |
1,005 |
|
0,50 |
1,250 |
1,107 |
|
0,90 |
1,450 |
1,307 |
|
0,95 |
1,475 |
1,337 |
Формулы ALOS справедливы и при >1, однако коэффициент заполнения желательно иметь небольшим. Метод эффективен, хорошо работает с меняющимися таблицами, но требует дополнительной памяти для m+n указателей.
Внутреннее сцепление позволяет при увеличении размера таблицы m (для уменьшения ) исключить большое количество заголовков для пустых списков. В этом методе узлы списков частично совпадают с заголовками списков. Такая организация таблицы позволяет для n записей резервировать память только для m указателей. Поиск свободных мест можно осуществлять любым способом, например линейным поиском с конца таблицы.
Пример. Обрабатываются ключи 75, 17, 12, 40, 35, 95, 87. Функция расстановки h(Key)=mod(Key,10).
|
|
Ключ |
Указатель |
|
|
|
1 |
|
nil |
|
|
|
2 |
12 |
nil |
|
|
|
3 |
|
nil |
|
|
|
4 |
|
nil |
|
|
|
5 |
75 |
|
|
Начало цепочки |
|
6 |
87 |
nil |
|
с индексом 5 |
|
7 |
17 |
|
|
|
|
8 |
95 |
nil |
|
|
|
9 |
35 |
|
|
|
|
0 |
40 |
nil |
|
|









Коэффициент заполнения должен быть меньше 1. Средняя длина поиска несколько выше, чем при раздельном сцеплении, однако экономия памяти делает метод привлекательным.
К недостаткам метода относится возможное смешивание цепочек. Например, для поиска пришел ключ 29. Его надо поместить в цепочку с индексом 9, а он будет помещен в конец цепочки с индексом 5 (75, 35, 95) – в ячейку с индексом 4 (первая свободная при поиске от ячейки 9 к ее началу).
Л абораторная
работа 5.
Поиск
и преобразование ключей
абораторная
работа 5.
Поиск
и преобразование ключей
Задание
Составить программу формирования заданным методом таблицы поиска и последующего поиска в этой таблице элементов из входной последовательности.
Программу необходимо выполнить с двумя вариантами исходных данных:
– отладочный (10 элементов), демонстрирующий работу алгоритма поиска;
– рабочий (50 элементов), в результате обработки которого выводятся значения параметров эффективности (число сравнений ключей), определенных для заданного метода поиска.
Исходные данные и результаты работы программы (демонстрационные и рабочие) разместить в текстовых файлах.
В вариантах с нечетными номерами каждый элемент – строковая переменная. В вариантах с четными номерами элемент состоит из двух полей: строковой переменной и числового ключа.
При расстановке строковые ключи необходимо предварительно свернуть каким-либо методом.
В вариантах, отмеченных звездочкой, таблица организована в виде списка, в остальных вариантах таблица хранится в массиве.
|
Вариант |
Метод поиска |
Метод устранения конфликтов при расстановке |
|
1, 2* |
Линейный поиск с барьером |
|
|
3* |
Метод перемещения в начало |
|
|
4, 5* |
Метод транспозиции |
|
|
6, 7* |
Индексно-последовательный поиск |
|
|
8 |
Бинарный поиск |
|
|
9, 10 |
Расстановка методом деления |
Линейное опробование |
|
11, 12 |
Расстановка методом деления |
Случайное опробование |
|
13, 14 |
Расстановка методом деления |
Двойная расстановка |
|
15, 16 |
Расстановка методом середины квадрата |
Двойная расстановка |
|
17, 18 |
Расстановка методом середины квадрата |
Раздельное сцепление |
|
19, 20 |
Расстановка методом свертки |
Внутреннее сцепление |
|
21, 22 |
Расстановка методом свертки |
Раздельное сцепление |
|
23, 24 |
Расстановка методом свертки |
Двойная расстановка |
|
25, 26 |
Расстановка граничной сверткой |
Двойная расстановка |
|
27, 28 |
Мультипликативная функция |
Внутреннее сцепление |
|
29, 30 |
Преобразование системы счисления |
Двойная расстановка |
Рекомендации по выполнению работы
Для создания таблицы и последующего поиска в ней рекомендуется создать текстовый файл, содержащий порядка 100 элементов.
Сначала выполнить работу в отладочном (демонстрационном) режиме, для чего прочитать из этого файла первые 10 элементов и создать таблицу. Ввести в диалоговом режиме значение элемента, присутствующего в таблице, и выполнить его поиск, демонстрируя все шаги алгоритма (индексы и результаты сравнений). Затем ввести значение элемента, которого нет в таблице, и выполнить поиск с демонстрацией шагов алгоритма. Результаты поиска вывести в текстовый файл.
Затем выполнить работу в рабочем режиме. Для этого открыть тот же файл с исходными данными для чтения, прочитать из него первые 50 элементов и создать таблицу. Затем вновь открыть этот файл для чтения, последовательно прочитать из него и выполнить поиск всех 100 элементов, подсчитывая количество операций сравнения ключей на каждом шаге поиска. При этом в файл результатов вывести только результаты исследования процедуры поиска (число сравнений ключей, потребовавшихся для поиска). Чтобы правильно оценить эффективность поиска, необходимо, чтобы во второй половине текстового файла содержались элементы, отсутствующие в таблице.
Для методов разрешения конфликтов при расстановке необходимо отдельно оценивать эффективность успешного и неуспешного поиска.