

2.2. Реляционная модель организации данных. (вопросы 7,8)
2.2.1. Структурная составляющая. (вопрос 7)
В реляционной модели объекты-сущности инфологической схемы предметной области АИС представляются плоскими таблицами данных.
Столбцы таблицы (колонки), называемые полями базы данных, соответствуют атрибутам объектов-сущностей инфологической схемы предметной области.
Множество атомарных значений атрибута называют доменом.
Строки таблицы содержат сведения о представленных в ней фактах (или документах, или людях одним словом – об однотипных объектах).
Строки таблицы представляют различные сочетания значений полей из доменов и называются также записями (кортежами).
На пересечении столбца и строки находятся конкретные значения содержащихся в таблице данных. Данные в таблицах удовлетворяют следующим принципам.
-
Каждое значение, содержащееся на пересечении строки и колонки, должно быть атомарным (то есть не расчленяемым на несколько значений).
-
Значения данных в одной и той же колонке должны принадлежать к одному и тому же типу, доступному для использования в данной СУБД.
-
Каждая запись в таблице уникальна, то есть не существует двух записей с полностью совпадающим набором значений ее полей.
-
Каждое поле имеет уникальное имя.
-
Последовательность полей в таблице несущественна.
-
Последовательность записей также несущественна.
Несмотря на то, что строки таблиц считаются неупорядоченными, любая СУБД позволяет сортировать строки и колонки в выборках нужным пользователю способом.
Поскольку последовательность полей (колонок) в таблице несущественна, обращение к ним производится по имени, и эти имена для данной таблицы уникальны, но не обязаны быть уникальными для всей базы данных.
Ключи и связи. Для иллюстрации некоторых положений рассмотрим примеры, воспользовавшись базой данных North Wind, входящей в комплект поставки Microsoft SQL Server и Microsoft Access.
Рассмотрим фрагмент таблицы Клиенты (рис. 2.2).

Рис. 2.2. Фрагмент таблицы Клиенты.
Поскольку строки в таблице не упорядочены, необходимо создавать поле (колонку) или несколько полей (колонок) для уникальной идентификации каждой строки (конкретного экземпляра объекта).
Этот набор колонок называется первичным ключом (primary key - PK). Первичный ключ любой таблицы должен содержать уникальные непустые значения для каждой строки. Если ключ состоит из нескольких полей (колонок), он называется составным первичным ключом (composite primary key).
Совокупность определенных для именованной таблицы - отношения полей, их свойства (ключи и пр.) составляют схему таблицы отношения.
Как уже отмечалось, таблица в реляционной модели отражает определенный объект – сущность из инфологической схемы предметной области АИС. Типичная база данных обычно состоит из нескольких связанных таблиц.
Отношения связей объектов сущностей устанавливаются через введение в таблицах дополнительных полей, которые дублируют ключевые поля связанной таблицы. Рассмотрим фрагмент таблицы Заказы (рис. 2.3.).

Рис. 2.3. Фрагмент таблицы Заказы.
Поле Клиент ID этой таблицы содержит идентификатор клиента, разместившего заказы. Если нужно узнать, как называется компания, разместившая заказы, мы должны отыскать это же значение идентификатора клиента в поле Клиент ID таблицы Клиенты и в найденной строке прочитать значение поля Наименование компании. Другими словами нужно связать две таблицы Клиенты и Заказы по полю Клиент ID.
Поля, дублирующие ключ, указывающие на запись в другой таблице, называется внешним ключом (foreign key - FK). Как видно, в случае таблицы Заказы внешним ключом является поле Клиент ID (Рис. 2.4.).

Рис. 2.4. Первичные и внешние ключи в таблице Клиенты и Заказы.
Подобное взаимоотношение между таблицами и называется связью (relationship). Связь между двумя таблицами устанавливается путем присваивания значений первичного ключа одной таблицы значениям внешнего ключа другой таблицы.
Если каждый клиент в таблице Клиенты может разместить только один заказ, говорят, что эти две таблицы связаны соотношением «один – к - одному» (one-to-one relationship).
Если же каждый клиент в таблице Клиенты может поместить ноль, один или много заказов, говорят, что эти две таблицы связаны соотношением «один - ко - многим» (one-to-many relationship) или соотношением master-detail. Именно такие соотношения между таблицами используются наиболее часто. И в этом случае, таблица, содержащая внешний ключ, называется detail-таблицей, а таблица, содержащая первичный ключ, определяющий возможные значения внешнего ключа, называется master-таблицей. В некоторых таблицах роль ключа могут играть сразу несколько полей – группа полей (рис. 2.5.).
Так как значения первичного ключа уникальны, то есть не могут повторяться, в таблице «Отделы» может быть только один кортеж по 123 отделу, например. Значения других полей, и, в частности, внешнего ключа могут повторяться. Например, в таблице «Сотрудники» может быть несколько кортежей по 123 отделу. Такой механизм автоматически обеспечивает связь типа «один – ко - многим».

Рис. 2.5. Несколько полей образуют первичный ключ. Связь « один – ко - многим».
Связи «один - к - одному» обеспечиваются автоматически при одинаковых первичных ключах. Например, между таблицей «Сотрудник» с ключом Табельный номер, и таблицей «Паспорт» с таким же ключом (рис. 2.6).
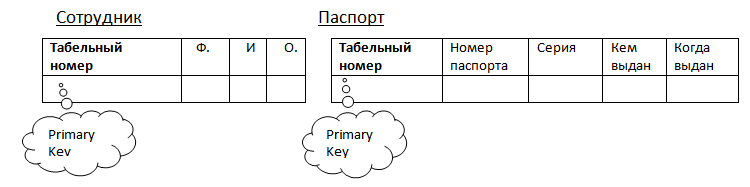
Рис. 2.6. Реализация связи « один - к - одному».
Из анализа данного механизма реализации связей вытекает, что реляционная модель не может непосредственно отражать связи типа «многие – ко - многим».
Группа связанных таблиц называется схемой базы данных. Информация о таблицах, их колонках (имена, тип данных, длина поля), первичных и внешних ключах, а также иных объектах базы данных называется метаданными (metadata).
Любые манипуляции с данными в базах данных, такие как выбор, вставка, удаление, обновление данных, изменение или выбор метаданных, называются запросом (query) к базе данных. Запросы формулируются, на каком либо языке, который может быть как стандартным для разных СУБД, так и индивидуальным для конкретной СУБД.
Индексирование полей. Теоретико-множественный характер реляционных таблиц требует отсутствия упорядоченности записей и полей. Отсутствие упорядоченности записей усложняет поиск нужных кортежей при обработке таблиц.
На практике для создания условий быстрого нахождения нужной записи таблицы без постоянного переупорядочения записей при любых изменениях данных вводят индексирование полей (обычно ключевых). Индексирование полей состоит в построении дополнительной упорядоченной информационной структуры для быстрого доступа к записям.
В большинстве реляционных СУБД ключи реализуются с помощью объектов, называемых индексами.
Индексы можно определить как список номеров записей, указывающий, в каком порядке их представлять. В каждый конкретный момент времени любая запись занимает определенное физическое место в файле базы данных, которое в процессе редактирования данных или в результате «внутренней деятельности» СУБД может изменяться.
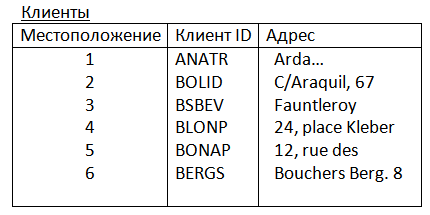
Рис. 2.7. Фрагмент таблицы с индексами.
Пусть в какой-то момент времени записи в таблице «Клиенты» хранились в таком порядке как это представлено на (Рис.2.7.). Теперь предположим, что нужно получить эти данные, упорядоченные по полю Клиент ID. Опустив технические детали, мы можем сказать, что индекс по этому полю – это последовательность номеров записей, в соответствии с которой их нужно выводить, то есть:
1, 6, 4, 2, 5, 3.
Если мы пожелаем упорядочить записи по полю адреса, последовательность номеров будет другой:
5, 4, 1, 6, 2, 3.
Очевидно, что хранение индексов требует существенно меньше места, чем хранение по-разному отсортированных версий самой таблицы. Если нас интересуют данные о клиентах, у которых значение поля «Клиент ID» начинается с символов «BO», мы с помощью индекса можем определить местоположение этих записей. В данном случае - это позиции 2 и 5. Очевидно, что в индексе номера этих записей идут подряд. После этого нужно прочесть только вторую и пятую записи, вместо того чтобы просматривать всю таблицу.
Таким образом, использование индексов снижает время выборки данных.