

2.3.3. Индексирование данных.
Стандартным приемом повышения эффективности доступа к записям в базах данных является создание индексных массивов по отдельным, обычно ключевым полям.
Использование линейного упорядочения записей в таблице (например, по алфавиту для текстовых ключевых полей или по возрастанию значений числовых ключевых полей) приводит к тому, что накладные расходы по ранжированию всей таблицы после добавления либо удаления строк – превышает выигрыш по времени доступа.
Структура индексов (индексных массивов) строится так, чтобы на основе некоторого критерия можно было бы быстро находить по значению индексируемого поля указатель на нужную запись – строку таблицы и получить к ней доступ. При этом не обязательно упорядочивать совокупность записей базовой таблицы, а при изменении записей необходимо изменить лишь только индексный массив.
Для индексных массивов, как и для информационных массивов самих данных (таблиц) применимы линейные и нелинейные структуры.
2.3.3.1. Линейные структуры индексов. (вопрос 12)
В качестве линейных структур индексов в большинстве случаев выступают инвертированные списки.
Инвертированный список строится по схеме таблицы с двумя колонками – «Значение индексируемого поля» и «Номера строк». На практике номера строк не самой базовой таблицы, а номера строк файла БД, где расположена соответствующая строка (см. рис. 2.15).
Инвертированные списки чаще всего применяются для индексации полей, значения которых в разных строках-записях могут повторяться. Например, поле «Год рождения» таблицы «Сотрудники» (в реляционных базах данных такие поля не могут быть ключевыми). Строки инвертированного списка упорядочиваются по значению индексируемого поля.
Для доступа к нужной строке исходной таблицы сначала в упорядоченном инвертированном списке отыскивается строка с требуемым значением поля, затем считывается номер соответствующей строки или строк в исходной таблице и далее по нему уже производится доступ к исходной строке базовой таблицы.
При добавлении новой строки в базовую таблицу ее значение по индексируемому полю ищется в ранее составленном индексе. Если соответствующая строка инвертированного списка отыскивается (т.е. подобное значение индексируемого поля среди строк таблицы уже встречалось и было поставлено на учет), то в ячейку второго столбца соответствующей строки индекса дописывается номер страницы, куда была помещена соответствующая строка базовой таблицы.
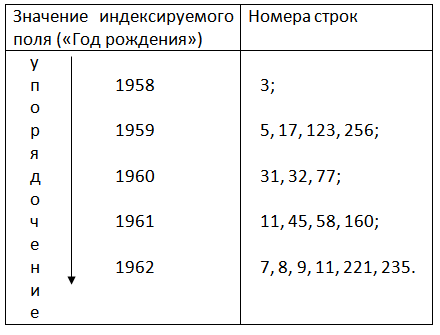
Рис. 2.15. Пример инвертированного списка.
Если такого значения в индексе нет, то создается новая строка индекса и осуществляется переупорядочение нового состояния индексного массива.
При удалении строки из базовой таблицы также производится поиск соответствующей строки в индексном массиве и осуществляется вычеркивание в индексе соответствующего номера отсылаемой строки базовой таблицы. Если при этом других строк в базовой таблице с таким же значением индексируемого поля не осталось, (соответствующая ячейка индекса стала пустой), то удаляется и вся строка индекса с последующим переупорядочением всего индексного массива. При этом за счет того, что индекс в виде инвертированного списка содержит лишь один столбец значений, затраты на переупорядочение при добавлении или удалении записей существенно меньше по сравнению с тем, если бы переупорядочение происходило непосредственно в самой базовой таблице. Кроме того, строки базовой таблицы можно упорядочивать только лишь по какому-либо одному полю, а индексные массивы можно создавать сразу по нескольким полям.
Индексы в виде инвертированных списков являются особенно эффективными в том случае, когда значения индексируемого поля часто повторяются, образуя равномерные по мощности группы. В этом случае количество ситуаций, при которых требуется добавление или удаление строк индекса, невелико, и затраты на переупорядочение индекса при изменениях данных в базовой таблице незначительны.
В результате выигрыш по затратам на доступ существенно превышает накладные расходы по переупорядочению индекса в процессе ведения базы данных.