

2. Лабораторная работа №2. Корреляционный и регрессионный анализ
2.1. Основные теоретические положения
Основные положения корреляционного анализа. Двумерная модель
Корреляционный анализ применяют, когда данные наблюдений или эксперимента считаются случайными и выбранными из нормальной совокупности.
На
практике часто имеет место генеральная
совокупность, которая исследуется
не по одному, а по двум признакам или
переменным
![]() и
и
![]() ,
являющимся случайными
величинами.
При
этом требуется установить наличие и
степень связи между
,
являющимся случайными
величинами.
При
этом требуется установить наличие и
степень связи между
![]() и
и
![]() .
.
Поскольку исследовать всю генеральную совокупность по этим признакам в большинстве случаев не представляется возможным, то проводится случайная выборка.
В результате изучения выборки исследователь получает пары чисел (точки):
![]() ,
,
где
![]() – объём выборки.
– объём выборки.
Если нанести эти точки на координатную плоскость, то можно получить возможные картины распределения точек выборки (рис. 2.1).
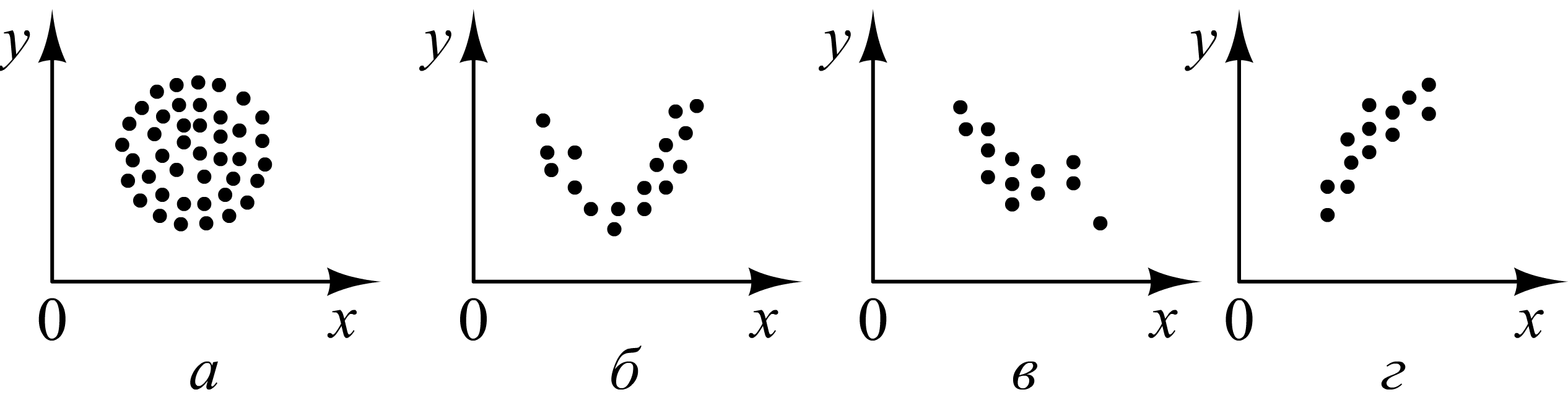
Рис. 2.1. Некоторые диаграммы рассеяния точек выборки
На
рис. 2.1, а
![]() и
и
![]() скорее независимы:
зная, какое значение приняла величина
скорее независимы:
зная, какое значение приняла величина
![]() ,
ничего однозначно
нельзя сказать о значении
,
ничего однозначно
нельзя сказать о значении
![]() .
На остальных рисунках зависимость
очевидна, причем на рис. 2.1, б
она близка к квадратичной, а на рис. 2.1,
в и
г она
близка к линейной. Такие величины
называются коррелированными.
.
На остальных рисунках зависимость
очевидна, причем на рис. 2.1, б
она близка к квадратичной, а на рис. 2.1,
в и
г она
близка к линейной. Такие величины
называются коррелированными.
В
случае, когда было известно двумерное
распределение случайной величины (![]() ,
,
![]() )
в генеральной
совокупности, можно найти генеральный
коэффициент корреляции и по его величине
судить о степени связи
)
в генеральной
совокупности, можно найти генеральный
коэффициент корреляции и по его величине
судить о степени связи
![]() и
и
![]() .
Поскольку исследователь
располагает только результатами изучения
выборки, то в качестве оценки генерального
коэффициента корреляции
.
Поскольку исследователь
располагает только результатами изучения
выборки, то в качестве оценки генерального
коэффициента корреляции
![]() может быть использован выборочный
(статистический) коэффициент корреляции
может быть использован выборочный
(статистический) коэффициент корреляции
![]() .
.
Алгоритм
нахождения выборочного коэффициента
корреляции
![]() следующий:
следующий:
а)
вычисляются выборочные средние переменных
![]() ,
,![]() и
и
![]() по формулам
по формулам
![]()
б)
вычисляются выборочные средние
квадратические отклонения переменных
![]() и
и
![]()
![]() ;
;
в) вычисляется выборочный корреляционный момент (выборочная ковариация)
![]() ;
;
г) вычисляется выборочный коэффициент корреляции
![]() .
.
Основные свойства выборочного коэффициента корреляции при достаточно большом объеме выборки аналогичны свойствам коэффициента корреляции двух случайных величин.
1.
Коэффициент корреляции принимает
значения на отрезке
![]() ,
т.е.
,
т.е.
![]() .
.
В
зависимости от того, насколько
![]() приближается к единице, различают
слабую, умеренную и сильную связь: чем
ближе
приближается к единице, различают
слабую, умеренную и сильную связь: чем
ближе
![]() к единице, тем теснее связь между
признаками
к единице, тем теснее связь между
признаками
![]() и
и
![]() .
.
2.
Если переменные
![]() и
и
![]() умножить на одно и то
же число, то коэффициент корреляции
не изменится.
умножить на одно и то
же число, то коэффициент корреляции
не изменится.
3.
Если
![]() ,
то корреляционная связь между
,
то корреляционная связь между
![]() и
и
![]() пред-ставляет собой
линейную зависимость.
пред-ставляет собой
линейную зависимость.
Выборочный
коэффициент корреляции
![]() является оценкой генерального коэффициента
корреляции
является оценкой генерального коэффициента
корреляции
![]() ,
тем более точной, чем больше объем
выборки
,
тем более точной, чем больше объем
выборки
![]() .
.
Так
как
![]() вычисляется по данным выборки, то, в
отличие от генерального коэффициента
корреляции
вычисляется по данным выборки, то, в
отличие от генерального коэффициента
корреляции
![]() ,
,
![]() является величиной
случайной. Если
является величиной
случайной. Если
![]() ,
то возникает вопрос: объясняется ли
это действительно существующей линейной
связью между
,
то возникает вопрос: объясняется ли
это действительно существующей линейной
связью между
![]() и
и
![]() или вызвано случайными
факторами?
или вызвано случайными
факторами?
Для
выяснения значимости коэффициента
корреляции проверяется гипотеза
![]() об отсутствии линейной корреляционной
связи между переменными
об отсутствии линейной корреляционной
связи между переменными
![]() и
и
![]() ,
т.е.
,
т.е.
![]() :
:
![]() .
.
При справедливости этой гипотезы статистика
![]()
имеет
распределение Стьюдента с
![]() степенями сво-боды. Поэтому гипотеза
степенями сво-боды. Поэтому гипотеза
![]() отвергается,
если
отвергается,
если
![]() ,
,
где
![]() – табличное значение распределения
Стьюдента (прил. 5), определенное на
уровне значимости
– табличное значение распределения
Стьюдента (прил. 5), определенное на
уровне значимости
![]() при числе степеней свободы
при числе степеней свободы
![]() .
.
Пользуясь
таблицей приложения, следует вместо
![]() подставлять вычисленное значение
подставлять вычисленное значение
![]() и
вероятность
и
вероятность
![]() .
.
Рассмотренный коэффициент корреляции является показателем тесноты связи лишь в случае линейной зависимости.
Разброс
значений величины
![]() вокруг математического ожидания
вокруг математического ожидания
![]() измеряется общей дисперсией
измеряется общей дисперсией
![]() ,
или
,
или
![]() .
По определению
.
По определению
![]() .
.
Этот разброс может быть вызван:
– наличием
случайных факторов, действующих на
![]() через переменную
через переменную
![]() (межгрупповая факторная
дисперсия);
(межгрупповая факторная
дисперсия);
– зависимостью
![]() от случайных факторов (остаточных),
влияющих только на
от случайных факторов (остаточных),
влияющих только на
![]() и не влияющих на
и не влияющих на
![]() (остаточная
дисперсия).
(остаточная
дисперсия).
Запишем правило сложения дисперсий в форме
![]()
![]() – общая
дисперсия переменной
– общая
дисперсия переменной
![]() (дисперсия, вычисленная для всей
совокупности),
(дисперсия, вычисленная для всей
совокупности),
![]() – среднее
значение для всей совокупности.
– среднее
значение для всей совокупности.
Разделим
значения
![]() на
на![]() групп
групп![]() ,
,![]() ,
тогда
,
тогда – групповые средние,
– групповые средние,
![]() – объём
– объём
![]() -й
группы,
-й
группы,
![]() –
–
![]() -ечастоты для
-ечастоты для
![]() в группе
в группе
![]() .
Аналогично для групповых дисперсий:
.
Аналогично для групповых дисперсий: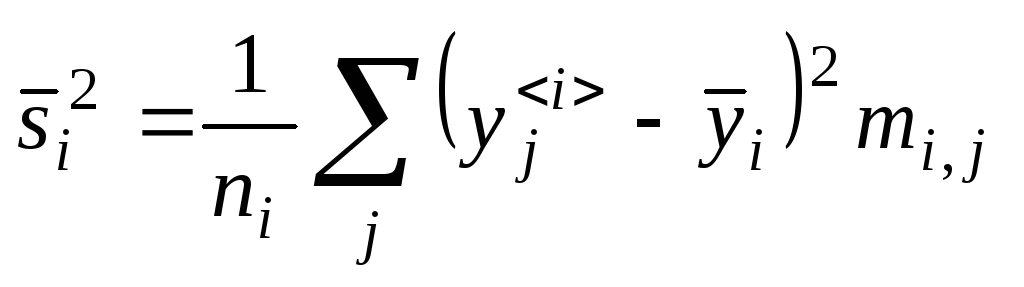 .
.
Получаем:
![]() – межгрупповая дисперсия;
– межгрупповая дисперсия;
![]() – внутригрупповая дисперсия.
– внутригрупповая дисперсия.
Величина
![]()
называется генеральным корреляционным отношением.
Чем
теснее связь, тем большее влияние на
вариацию
![]() оказывает изменчивость
оказывает изменчивость
![]() ,
тем больше
,
тем больше![]() .
.
Величина![]() является генеральным коэффициентом
детерминации. Он показывает, какую долю
дисперсии величины
является генеральным коэффициентом
детерминации. Он показывает, какую долю
дисперсии величины
![]() составляет дисперсия условных
математических ожиданий, или, иначе
говоря, какая доля дисперсии
составляет дисперсия условных
математических ожиданий, или, иначе
говоря, какая доля дисперсии
![]() объясняется корреляционной
зависимостью
объясняется корреляционной
зависимостью
![]() от
от
![]() .
.
Чем
ближе
![]() к
единице, тем теснее наблюдения примыкают
к линии регрессии, тем лучше регрессия
описывает зависимость переменных.
Можно показать, что для линейной модели
к
единице, тем теснее наблюдения примыкают
к линии регрессии, тем лучше регрессия
описывает зависимость переменных.
Можно показать, что для линейной модели
![]() .
.
Свойства корреляционного отношения.
1.
![]() принимает только
положительные значения и диапазоне
принимает только
положительные значения и диапазоне
![]() .
.
2.
Если
![]() ,
то корреляционная зависимость между
,
то корреляционная зависимость между
![]() и
и
![]() отсутствует.
отсутствует.
3.
Условие
![]() является необходимым
и достаточным для функциональной
зависимости величины
является необходимым
и достаточным для функциональной
зависимости величины
![]() от
от
![]() .
Это основное свойство
корреляционного отношения.
.
Это основное свойство
корреляционного отношения.
Проиллюстрируем сформулированные свойства диаграммами рассеивания (рис. 2.2).
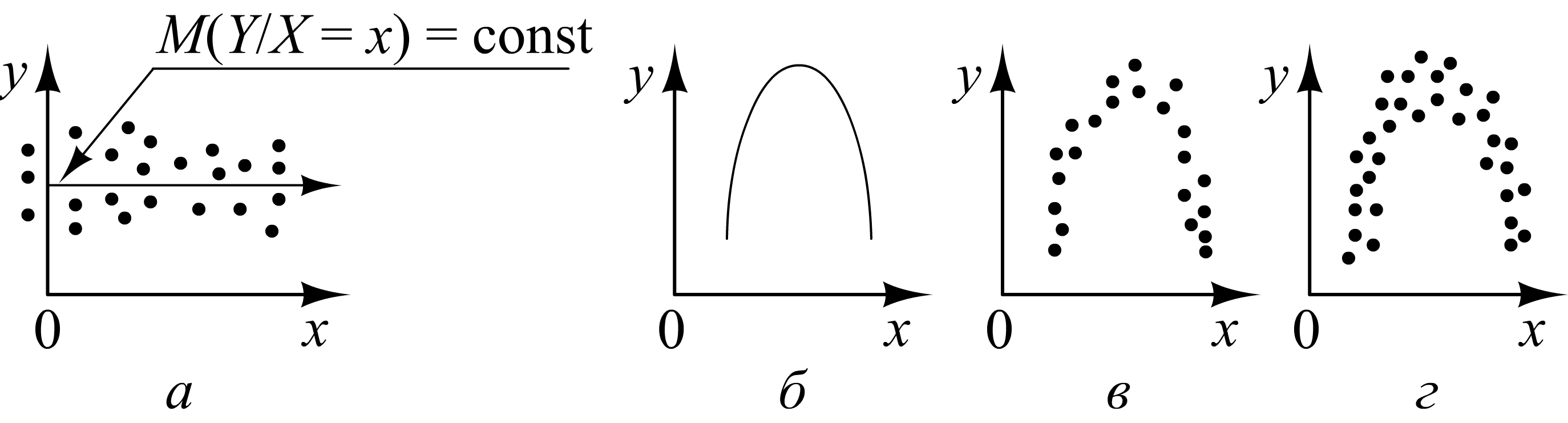
Рис. 2.2. Диаграммы рассеивания
Пояснения
к рисунку: а
– корреляционная зависимость отсутствует;
б – зависимость
![]() от
от
![]() функциональная:
функциональная:
![]() ;
в – стохастическая
зависимость довольно сильная: точки
сконцентрированы в относительно узкой
«параболической полосе»; г
– стохастическая
зависимость по сравнению с зависимостью,
изображенной на рис. 2.2, в,
менее сильная: точки концентрируются
в более широкой «параболической полосе».
;
в – стохастическая
зависимость довольно сильная: точки
сконцентрированы в относительно узкой
«параболической полосе»; г
– стохастическая
зависимость по сравнению с зависимостью,
изображенной на рис. 2.2, в,
менее сильная: точки концентрируются
в более широкой «параболической полосе».
Основные положения регрессионного анализа. Парная регрессионная модель
При
изучении стохастических зависимостей
в задачах техники, экономики и т.д. одним
из главных моментов является установление
вида зависимости
![]() от
от
![]() ,
т.е. вида уравнения
регрессии. Это связано в первую очередь
с необходимостью прогнозирования
исследуемых процессов.
,
т.е. вида уравнения
регрессии. Это связано в первую очередь
с необходимостью прогнозирования
исследуемых процессов.
Установление формы зависимости, оценка функции регрессии и ее параметров являются задачами регрессионного анализа.
В регрессионном анализе изучаются модели вида
![]() ,
(2.1)
,
(2.1)
где
![]() – неслучайная
независимая переменная, называемая
фактором;
– неслучайная
независимая переменная, называемая
фактором;
![]() – случайная зависимая
переменная (результирую-щий признак);
– случайная зависимая
переменная (результирую-щий признак);
![]() – случайная переменная, характеризующая
отклонение фактора
– случайная переменная, характеризующая
отклонение фактора
![]() от линии регрессии
(остаточная переменная).
от линии регрессии
(остаточная переменная).
Основными предпосылками регрессионного анализа являются следующие.
1.
Для каждого из наблюдений каждая
случайная переменная
![]() распределена по нормальному закону.
Причем
распределена по нормальному закону.
Причем
![]() .
.
2.
Для разных наблюдений переменные
![]() и
и
![]() некоррелированы.
некоррелированы.
Уравнение регрессии (2.1) записывается в виде
![]() ,
(2.2)
,
(2.2)
где х – значения величины Х;
![]()
![]() – параметры
функции регрессии.
– параметры
функции регрессии.
Таким
образом, задача
регрессионного анализа
состоит в определении
функции
![]() ,
ее параметров
,
ее параметров
![]() и дальней-шем статистическом
исследовании уравнения (2.2).
и дальней-шем статистическом
исследовании уравнения (2.2).
Рассмотрим
понятие корреляционного
поля. Пусть
зависимость между
![]() и
и
![]() на координатной плоскости
на координатной плоскости
![]() име-ет
вид, представленный на рис. 2.3. Графическое
изображение такой зависимости
называется корреляционным
полем.
име-ет
вид, представленный на рис. 2.3. Графическое
изображение такой зависимости
называется корреляционным
полем.
Для
каждого значения
![]() вычислим групповые
средние
вычислим групповые
средние
![]() .
Соединив полученные
точки ломаной линией, получим график
эмпирической линии
регрессии
.
Соединив полученные
точки ломаной линией, получим график
эмпирической линии
регрессии
![]() по
по
![]() .
По виду эмпирической
линии регрессии (см. рис. 2.3) можно
предположить, что связь между величинами
.
По виду эмпирической
линии регрессии (см. рис. 2.3) можно
предположить, что связь между величинами
![]() и
и
![]() является
линейной.
является
линейной.
Рассмотрим
парную линейную регрессионную модель
взаимосвязи двух переменных, для которой
функция регрессии
![]() линейна относительно переменной
линейна относительно переменной
![]() .
Обозначим через
.
Обозначим через
![]() условную
среднюю признака
условную
среднюю признака
![]() в генеральной
совокупности при фиксированном значении
в генеральной
совокупности при фиксированном значении
![]() переменной
переменной
![]() .
Тогда уравнение
регрессии будет иметь вид
.
Тогда уравнение
регрессии будет иметь вид
![]() .
.
Коэффициент
![]() в этом уравнении
называется коэффициен-том
регрессии. Он
показывает, на сколько единиц в среднем
изменяется переменная
в этом уравнении
называется коэффициен-том
регрессии. Он
показывает, на сколько единиц в среднем
изменяется переменная
![]() при изменении
переменной
при изменении
переменной
![]() на одну единицу.
на одну единицу.
Поскольку
коэффициенты
![]() и
и
![]() для генеральной
совокуп-ности неизвестны, проводится
их оценка с использованием выборки.
С этой целью обычно используют метод
наименьших квадратов.
для генеральной
совокуп-ности неизвестны, проводится
их оценка с использованием выборки.
С этой целью обычно используют метод
наименьших квадратов.

Рис. 2.3. Корреляционное поле
Как указывалось ранее, в распоряжении исследователя имеются только результаты изучения выборки в виде пар чисел (точек)
![]() ,
,
где
![]() –
объём выборки.
–
объём выборки.
Применяя к этим точкам метод наименьших квадратов, получаем
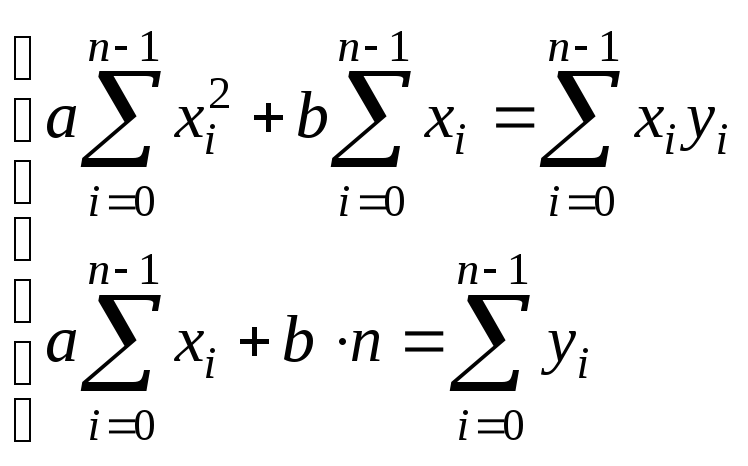
разделив
оба уравнения на
![]() и используя
обозначения
и используя
обозначения
![]() ,
,
получаем систему уравнений в виде
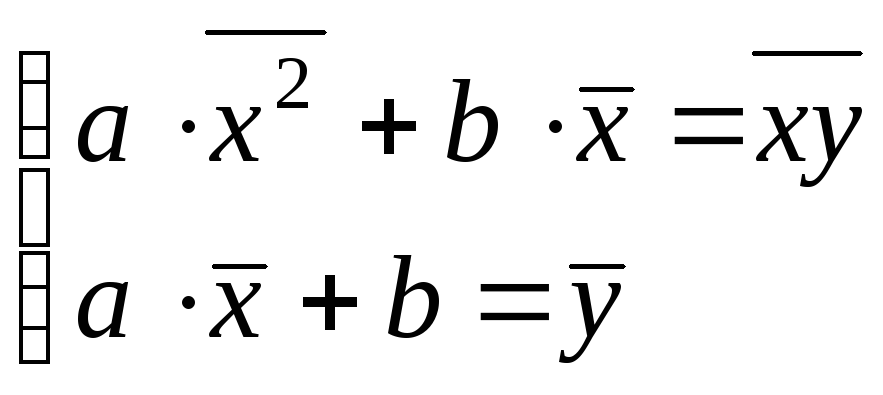 .
.
Решаем эту систему по правилу Крамера
![]() ,
,
![]()
отсюда
![]() .
.
Свободный
член
![]() проще вычислить по формуле
проще вычислить по формуле
![]()
Вычислив
значения
![]() и
и
![]() ,
найдем прямую, наилучшим
образом выражающую статистическую
связь между величинами
,
найдем прямую, наилучшим
образом выражающую статистическую
связь между величинами
![]() и
и
![]() .
Эта прямая, определяемая
уравнением регрессии
.
Эта прямая, определяемая
уравнением регрессии
![]() ,называется
прямой регрессии
,называется
прямой регрессии
![]() на
на
![]() .
.
Коэффициент регрессии можно рассчитать по другой формуле:
![]() .
.
Линейное уравнение регрессии обычно записывается в принятой математической статистике форме:
![]()
или
![]() .
.
Аналогично,
уравнение регрессии
![]() на
на
![]() имеет вид
имеет вид
![]() .
.
Статистический анализ уравнения регрессии
Для того чтобы установить, соответствует ли выбранная регрессионная модель экспериментальным данным, используют основное уравнение дисперсионного анализа
![]() ,
,
где
![]() – общая сумма квадратов отклонений от
среднего;
– общая сумма квадратов отклонений от
среднего;
![]() – сумма
квадратов от среднего, обусловленная
регрессией
– сумма
квадратов от среднего, обусловленная
регрессией
![]() ;
;
![]() – остаточная
сумма квадратов.
– остаточная
сумма квадратов.
Для
заданного уровня значимости
![]() по таблицам находим критическое
значение
по таблицам находим критическое
значение
![]() распределения Фишера
при
распределения Фишера
при
![]() ,
,![]() степенях свободы, где
степенях свободы, где
![]() – число наблюдений;
– число наблюдений;
![]() – число групп в корреляционной таблице
(прил. 6) или число оцениваемых параметров.
Если расчетное значение
критерия Фишера (2.3) будет меньше, чем
табличное значение, то нет оснований
считать, что независимый фактор оказывает
влияние на разброс средних значений, в
противном случае, независимый фактор
оказывает существенное влияние на
разброс средних значений.
– число групп в корреляционной таблице
(прил. 6) или число оцениваемых параметров.
Если расчетное значение
критерия Фишера (2.3) будет меньше, чем
табличное значение, то нет оснований
считать, что независимый фактор оказывает
влияние на разброс средних значений, в
противном случае, независимый фактор
оказывает существенное влияние на
разброс средних значений.
![]() .
(2.3)
.
(2.3)
Воздействие
неучтенных случайных факторов в линейной
модели определяется остаточной дисперсией
![]() .
Оценкой этой дисперсии является
выборочная остаточная дисперсия:
.
Оценкой этой дисперсии является
выборочная остаточная дисперсия:
![]() .
.
Интервальная оценка и проверка значимости уравнения регрессии
Интервальная
оценка уравнения регрессии заключается
в вычислении доверительных интервалов
коэффициентов
![]() и
и
![]() в
уравнении регрессии с доверительной
вероятностью
в
уравнении регрессии с доверительной
вероятностью
![]() .
Поскольку коэффициенты
.
Поскольку коэффициенты
![]() и
и
![]() определены по результатам
изучения выборки, то они являются лишь
точечными оценками истинных коэффициентов
уравнения регрессии в генеральной
совокупности
определены по результатам
изучения выборки, то они являются лишь
точечными оценками истинных коэффициентов
уравнения регрессии в генеральной
совокупности
![]() и
и
![]() .
.
Доверительными
интервалами коэффициентов
![]() и
и
![]() с доверительной
вероятностью
с доверительной
вероятностью
![]() называются интервалы с границами
называются интервалы с границами
![]()
где
![]() и
и
![]() – средние квадратические
отклонения коэффициентов
– средние квадратические
отклонения коэффициентов
![]() и
и
![]() ;
;
![]() – параметр распределения
Стьюдента с
– параметр распределения
Стьюдента с
![]() степенями свободы (
степенями свободы (![]() – объём выборки). Этот коэффициент
определяется в прил. 5, в котором вместо
– объём выборки). Этот коэффициент
определяется в прил. 5, в котором вместо
![]() берётся значение
берётся значение
![]() .
.
Параметры
![]() и
и
![]() вычисляются по следующим
формулам:
вычисляются по следующим
формулам:
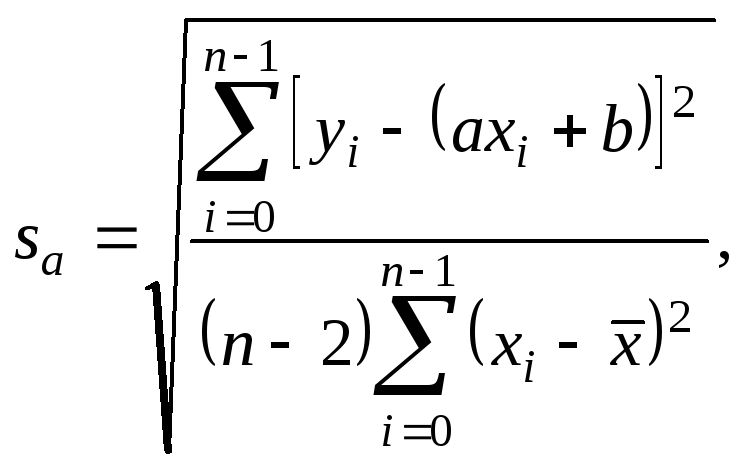
 .
.
Проверить значимость уравнения регрессии – значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным. Проверку значимости уравнения регрессии обычно проводят по критерию Фишера – Снедекора, который часто называют просто критерием Фишера.
Согласно этому критерию уравнение регрессии
![]()
является
значимым при уровне значимости
![]() ,
если фактически наблюдаемое значение
статистики критерия Фишера
,
если фактически наблюдаемое значение
статистики критерия Фишера
![]()
больше,
чем табличное значение
![]() ,
определенное для уровня значимости
,
определенное для уровня значимости
![]() при
при
![]() и
и
![]() ,
,
где
![]() – число оцениваемых параметров уравнения
регрессии. В рассматриваемом случае их
два:
– число оцениваемых параметров уравнения
регрессии. В рассматриваемом случае их
два:
![]() и
и
![]() ;
;
![]() – объём выборки.
– объём выборки.
Значения
![]() приведены в прил. 6. Величины
приведены в прил. 6. Величины
![]() и
и
![]() определяются по формулам
определяются по формулам
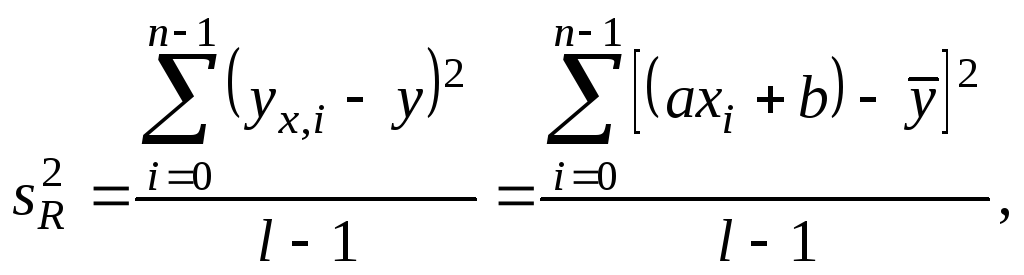
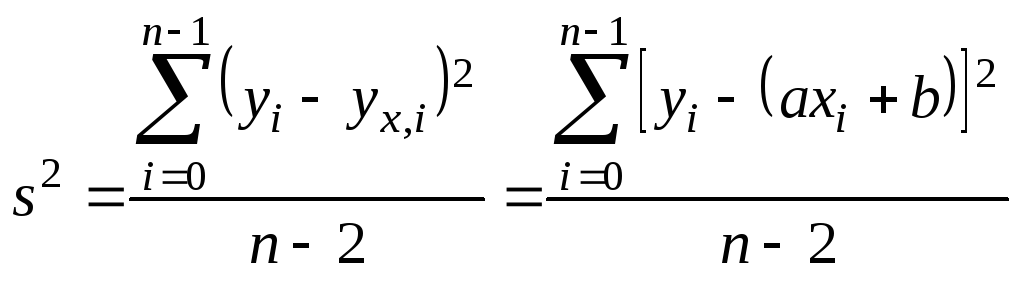 .
.