

Тимофеева, УМК_Математ. методы в филологии
.pdfЭИГ – элементарная именная группа, ЭИГi – неполные элементарные именные группы: ЭИГ1 – элементарная именная группа без союза, ЭИГ2 – без союза и без ограничительной (отрицательной) частицы, ЭИГ3 – без союза, без ограничительной (отрицательной) частицы и без предлога. Далее препозитивные определения упорядочены в соответствии
со свойственной им позицией по отношению к определяемому существительному.
К одному классу относятся прилагательные, занимающие (обычно) одну и ту же позицию по отношению к определяемому существительному. Если прилагательное Х принадлежит классу i, а прилагательное Y – классу j, причѐм j i, то Х должно стоять дальше от существительного, чем Y.

Пример 6.
Пример 7.
Трансформационная грамматика содержит:
1)Базовый компонент: грамматика, порождающая ядерные типы предложений (синтаксически простые предложения),
2)Трансформационный компонент: правила трансформации, порождающие более
сложные предложения на основе ядерных предложений
Примеры ядерных типов предложений (Vt - переходный глагол, Vi - непереходный гла-
гол):
NP + Vi (чайник кипит)
NP + Vt + NP + NP (они написали брату письмо)
NP + Vi + Adj (Adv) (он поѐт хорошо)
Примеры трансформационных правил (описание синтаксической и морфологической
производности): |
|
|
|
An Nn |
N(A)n Ng (быстрое движение |
быстрота движения) |
|
V Na |
N(V)n Ng |
(прибавляю число прибавление числа) |
|
V Ni |
N(V)n Ni |
(управляю процессом |
управление процессом) |
V в Na |
N(V)n в Na (возвожу в степень |
возведение в степень) |
|
N1n из N2g A(N2)n N1n (предмет из металла металлический предмет)
Примеры трансформационных правил модификации и комбинации предложений:
X N, которое является Adj Y X N Adj Y (дерево, которое является хвойным хвойное дерево), это унарная трансформация (преобразует одну фразу в другую);
X N1Y, N2 VР X N, которое VР Y (вставление определительного придаточного предложения в главное предложение, например, человек посадил дерево + дерево является хвойным человек посадил дерево, которое является хвойным), это бинарная транс-
формация, она определена на парах фраз (преобразует две фразы в третью); данное правило объединяет два предложения (XN1Y и N2V ) в одно, X, Y – соответственно левый и правый контексты, N1 =N2 =N.
Пример 8.
Формальные грамматики также активно используются в когнитивных исследованиях. Одно из недавних исследований особенностей освоения языка ребѐнком провели итальян-
ские когнитивные лингвисты: Bannard C., Lieven E., Tomasello M. Modeling children's early grammatical knowledge // Proceedings of the National Academy of Sciences. 13 October 2009. V. 106. No. 41. P. 17284–17289.
Исследовался корпус детских текстов (60 часов детской речи). Корпус разделяли на:
1)главную часть, по ней автоматически строились вероятностные КС-грамматики, моделирующие языковую компетенцию ребѐнка (ни категории, ни правила заранее не задавали). Вероятностная КС-грамматика отличается от обычной КС-грамматики (определение которой было дано в разделе 3.2) тем, что правила в ней не равноправны: каждому из них приписана определѐнная мера его значимости (вероятность).
2)тестовую часть (на ней проверялись построенные грамматики).
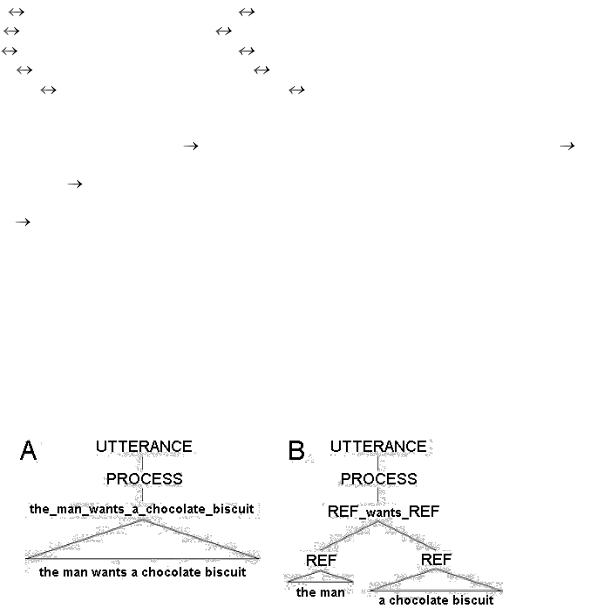
Цель авторов, в частности, состояла в том, чтобы (автоматически, с использованием компьютера) выявить вероятностную грамматику, оптимальным образом описывающую имеющийся корпус текстов, и оценить сложность этой грамматики. На рисунке выше приведены для иллюстрации две грамматики. Первая из них практически не содержит категорий (нетерминальных символов), предложение порождается за один шаг вывода. Вторая грамматика сложнее, процесс еѐ порождения основан на структурировании высказывания, выделении в нѐм определѐнных составляющих, и обозначение их посредством абстрактных категорий. Данные, полученные на главной части корпуса, затем проверялись на втором (тестовом) корпусе.
Литература по Модулю 3
1.Апресян Ю.Д. Идеи и методы современной структурной лингвистики. М., 1966.
2.Гладкий А.В. Формальные грамматики и языки. М., 1973.
3.Гладкий А.В., Мельчук И.А. Элементы математической лингвистики. М., 1969.
4.Гросс М., Лантен А. Теория формальных грамматик. М., 1971.
5.Лапшин В.А. Лекции по математической лингвистике. М.: Научный мир, 2010.
248 с.
6.Тимофеева М.К. Язык с позиций философии, психологии, математики. Новосибирск, НГУ, 2007. (М.: Флинта, Наука, 2010)
Модуль 4. Статистические методы
Тема 4.1. Основные направления применения в филологии
Прежде чем кратко характеризовать область применения статистики, разграничим задачи статистики и филологии.
В первом случае задача состоит в описании частотных закономерностей заданного материала, например, языковых текстов. Исследователь может задаться вопросом о том, как выявить, описать, оценить частотные характеристики, свойственные этому материалу. Ответ на этот вопрос он будет искать в рамках математической статистики и теории вероятностей. Для филолога такой ответ содержательно не интересен, так как не объясняет, какие языковые явления составляют основу данных характеристик.
Филологу важно понять, почему данному языковому материалу свойственны именно такие, а не иные вероятности, однако в рамках математической статистики такой вопрос не правомерен.
Иначе говоря, задача статистики – выявить количественные соотношения, вопрос об их качественном обосновании здесь, строго говоря, неуместен. Для филолога же количественные соотношения – это лишь исходные данные, которые надо ещѐ осмыслить и из которых предстоит сделать качественные выводы. Именно эти выводы (а не обусловившие их числовые соотношения) филолог и будет считать основным результатом своего исследования. Парадокс состоит в том, что как только такие выводы сделаны, числа вообще перестают играть существенную роль. Существенными становятся отношения порядка, определяемые этими числами.
Основной вывод из сказанного таков. Прежде чем браться за подсчѐт частотных характеристик каких-то языковых единиц, филологу уже надо иметь некоторую предварительную гипотезу относительно тех качественных соотношений, которые могут явиться их следствиями. Эта гипотеза и определяет, какие именно подсчѐты он должен производить. Без неѐ подсчѐты представляют интерес только для статистики и лишь случайно могут оказаться интересными также и для филологии. Возникает вопрос: какие филологические гипотезы обычно служат основаниями для подсчѐта частотных характеристик?
Для краткого ответа на этот вопрос перечислим то, что филологи считают результатами использования статистических методов.
Результаты первого типа – методологические. Их цель – понять, как следует выявлять такие количественных характеристики текстов, которые являются осмысленными, т. е. интерпретируемыми в терминах филологии. Например, как подбирать тот корпус текстов,

на котором будут производиться подсчѐты (эти тексты должны быть в определѐнном отношении однородными, но каков формальный критерий однородности?). Как объединение текстов влияет на результаты исследования? Подобные вопросы очень актуальны, в частности, для корпусной лингвистики.
Результаты второго типа – эмпирические. Их цель – выявить числовые характеристики единиц языка или соотношения между такими характеристиками. Например, частоты встречаемости букв в русских литературных текстах, средние длины словоформ в разных языках11, зависимость между возрастом (временем возникновения) и длиной слова в слогах12, между рангом (порядковый номер слова в частотном словаре) и длиной слова в слогах13. Сюда же относится изучение количественных характеристик авторских или функциональных стилей (художественного, публицистического, научного и т. д.), сопоставительный анализ родственных языков, приблизительная датировка памятников письменности, использование статистических измерений в экспериментальных исследованиях.
Один известных эмпирических результатов – закон Эсту–Ципфа–Мандельброта – состоит в следующем.
Пусть V={w1, w2, w3, ..., wn } – словарь, в котором слова упорядочены по убыванию частот их встречаемости в текстах, wr – r - е по порядку слово из этого словаря, n – частота встречаемости данного слова согласно словарю V. Порядковый номер r называется рангом слова wr (самое частое слово имеет ранг 1 и т. д.). Согласно закону Эсту–Ципфа– Мандельброта произведение частоты слова на его ранг мало зависит от того, какое слово мы выбрали: эта величина почти одинакова для всех слов из V. Закон Эсту–Ципфа– Мандельброта формулирует только определѐнную тенденцию, он не абсолютен. Наиболее явственно данная закономерность наблюдается на самых частотных словах, для нечасто встречающихся слов нередки отклонения.
Ещѐ одна закономерность, обнаруженная Дж. Ципфом, связывает время возникновения и частоту употребления слова. Самые частые слова обычно оказываются наиболее древними. Ципф предположил, что эту зависимость можно использовать при исследовании истории языка. Здесь уместно перейти к другому типу результатов, полученных путѐм применения количественных методов в лингвистике.
Результаты третьего типа – теоретические. Их цель – построение теории языка на базе количественных исследований. Самый известный результат такого рода глоттохронология, предложенная американским лингвистом Морисом Сводешем в середине ХХ в.
В основе глоттохронологии лежат следующие пять постулатов14.
1.В словаре каждого языка можно выделить специальный фрагмент, называемый ос-
новной или стабильной частью (примерно 200 слов).
2.Можно указать список значений, которые в любом языке обязательно выражаются словами из основной части (например, понятия «и», «все», «животные», «спина», «дерево», «больше»). Эти слова образуют основной список.
3.Доля слов из основного списка, которые сохранятся (не будут заменены другими словами) на протяжении некоторого интервала времени t (год, столетие, тысячелетие и т. д.) постоянна (т. е. зависит только от величины t, но не от его выбора и не от того, слова какого языка рассматриваются).
4.Все слова из основного списка имеют одинаковые шансы сохраниться (или не сохраниться) на протяжении этого интервала времени.
11Пиотровский Р. Г., Бектаев К. Б., Пиотровская А. А. Математическая лингвистика. М.: Высш. шк., 1977. С.
120; 259.
12Арапов М. В., М. М. Херц. Математические методы в исторической лингвистике. М.: Наука, 1974. С. 52.
13Арапов М. В. Квантитативная лингвистика. М.: Наука, 1988. С.125.
14Арапов М. В., М. М. Херц. Математические методы в исторической лингвистике. М.: Наука, 1974. С. 21–
5. Вероятность слова из основного списка праязыка сохраниться в основном списке языка-потомка не зависит от его вероятности сохраниться в аналогичном списке другого потомка.
Значение коэффициента сохранности слов основного словаря зависит от скорости развития языка и колеблется от 0,74 для быстро развивающихся языков до 0,91 для стабильных языков (в среднем 0,81).
Постулаты, сформулированные Сводешем (так же как закономерности, обнаруженные Ципфом, и другими авторами), конечно, не описывают процессы функционирования и исторического развития языка с абсолютной точностью. Эти гипотезы следует рассматривать как утверждения о наличии определѐнных тенденций, свойственных языку. Однако, как уже говорилось, для филолога важны именно подобные качественные выводы, а не сами по себе количественные характеристики. Поэтому предложенная Сводешем теория языка продолжает привлекать интерес; критический анализ и развитие данной теории можно найти в ряде более поздних работ. В частности, подробное обсуждение еѐ возможностей и перспектив содержится в уже названной выше книге М. В. Арапова и М. М. Херца.
Тема 4.2. Экспериментальные исследования
Статистические измерения, используются в ряде направлений экспериментальной лингвистики. Для таких исследований существенны понятия «независимая переменная» и «зависимая переменная», классификация шкал измерения.
Независимые (манипулируемые, классифицирующие) переменные – параметры эксперимента, значения которых определяет экспериментатор. Цель экспериментатора - исследовать корреляции между заданными значениями независимых переменных и полученными в результате проведения эксперимента значениями зависимых переменных.
Зависимые переменные – параметры эксперимента, значения которых экспериментатору неизвестны заранее (до проведения эксперимента), но в результате эксперимента он намеревается их исследовать.
Шкалы измерения – способы упорядочения, сравнения и оценки значений зависимых и независимых переменных. Принято выделять шесть типов шкал: номинальная (шкала наименований), порядковая, интервальная, шкала разностей, абсолютная шкала.
Номинальная шкала (шкала наименований). По сути, является классификацией на-
блюдений на взаимно исключающие категории, здесь числа обозначают не меру, не степень, а качество. Такие шкалы используют для различения и отождествления объектов. В один класс попадают тождественные объекты, они соотносятся с одной и той же позицией шкалы. Например, класс всех правшей можно обозначить числом 1, класс левшей – числом 2. Числа здесь фактически являются просто именами, к ним нельзя применять никакие арифметические операции. Поэтому неважно, какие именно числа приписаны каждой категории: можно было бы обозначить иначе (например, число 2 – правши, число 1 – левши). Номинальная шкала – качественная: она используется для различения данных по их качественным характеристикам.
Примеры: этническая принадлежность, родной язык, номера телефонов, паспортов, ярлыки на одежде, цвет волос, глаз, номера букв в алфавите.
Порядковая шкала. По сравнению с предыдущей шкалой здесь добавляется порядок, то есть принимаются во внимание не только качественные различия, но и различия в степени. Например, можно квалифицировать социальный статус людей как «низкий», «средний», «высокий», этим уровням можно приписать номера 1, 2, 3 соответственно. Пользуясь такой шкалой, исследователь должен сам выбрать точку отсчета и единицу измерения.
Порядковые шкалы часто используют в психологических и социологических исследованиях, когда объекты сравнительно просто ранжировать по важности, развитости и т. д., но трудно численно выразить различия между элементами разных классов. Поэтому, несмотря на то, что для именования упорядоченных классов объектов используются числа, арифметические операции к этим числам не применимы. Это означает, что шкала данного типа тоже является качественной: она не характеризует величину различий между соседними позициями. Невозможно сравнивать между собой разные интервалы такой шкалы. Например, применительно к оценкам успеваемости (1, 2, 3, 4, 5) бессмысленно было бы утверждать, что двоечник отличается от троечника на тот же объѐм знаний, на какой четвѐрочник отличается от пятѐрочника (хотя с позиции арифметики равенство 3 – 2 = 5 – 4 истинно).
Примеры: оценки успеваемости, стадии развития, академическая степень, 12-бальная шкала Бофорта для силы морского ветра (штиль, слабый ветер, умеренный ветер и т. д.), шкала силы землетрясений, стадии гипертонической болезни, оценка качества товаров и услуг, оценка экологических воздействий.
Шкала интервалов (интервальная шкала). Числовая характеристика объекта в этом случае отражает не только степень выраженности, но и величину измеряемого признака данного объекта. Здесь можно сравнивать не только порядок расположения объектов, но и интервалы между ними; разности между соседними точками в этой шкале равны. Поэтому получаемые данные называют количественными. Вместе с тем, в таких шкалах точка отсчѐта (величина 0) выбирается случайно, она не означает отсутствия измеряемого качества. Поэтому можно утверждать равенство интервалов, но нельзя утверждать, что один интервал вдвое больше другого.
Примеры: координата точки на прямой, температура по Фаренгейту или по Цельсию.
Шкала отношений. Как и шкала интервалов, данная шкала измерения позволяет сравнивать наблюдения и показывает, во сколько раз один показатель больше другого. Однако в отличие от предыдущей шкалы, здесь имеется естественная нулевая точка, характеризующая отсутствие измеряемого качества. С помощью таких шкал могут быть измерены масса, длина, сила, вес и рост человека. В когнитивной лингвистике так измеряют, например, время реакции, количество правильно запомненных слов и т. д.
Примеры: доход, шкала Кельвина (температур, отсчитанных от абсолютного нуля, с выбранной по соглашению специалистов единицей измерения – градус Цельсия).
Шкала разностей. В отличие от предыдущей шкалы здесь естественной является не точка отсчѐта, а единица измерения. Иначе говоря, шкала разностей не позволяет свободно выбирать единицу измерения, возможен лишь фиксированный сдвиг с произвольно выбранной точки отсчѐта.
Пример: время, если использовать год (или сутки – от полудня до полудня) как естественную единицу измерения.
Абсолютная шкала. Эта шкала имеет и естественную точку отсчѐта, и естественную единицу измерения. Для абсолютной шкалы результаты измерений – это числа в обычном смысле данного слова.
Примеры: число людей в аудитории, число книг в библиотеке. Различия между шкалами подытоживает табл. 1.
Виды шкал |
|
Свойства шкалы |
Качественные |
Номинальная |
Классификация |
|
Порядковая |
Классификация, |
|
|
порядок |
Количественные |
Интервальная |
Классификация, |
|
|
порядок, |
|
|
равные интервалы |
|
|
нет естественного ноля, |
|
|
нет естественной единицы измерения |
|
Отношений |
Классификация, |
|
|
порядок, |
|
|
равные интервалы, |
|
|
естественный ноль, |
|
|
нет естественной единицы измерения |
|
Разностей |
Классификация, |
|
|
порядок, |
|
|
равные интервалы, |
|
|
естественная единица измерения, |
|
|
нет естественного ноля |
|
Абсолютная |
Классификация, |
|
|
порядок, |
|
|
равные интервалы, |
|
|
естественная единица измерения, |
|
|
естественный ноль |
В качестве примера рассмотрим экспериментальные исследования в области когнитивной лингвистики.
Цель применения статистики здесь, как правило, состоит в выявлении и исследовании корреляций между свойствами изучаемых объектов. В качестве объектов могут рассматриваться различные составляющие языкового поведения. В зависимости от исследовательской ситуации корреляции интерпретируются по-разному: как причинноследственные связи, системные или ассоциативные связи, эволюционная преемственность и т. д.
Собственно применению статистических методов предшествует построение определѐнной осмысленной процедуры измерения тех сырых данных, которые подлежат изучению. Для этого надо выделить переменные, то есть те свойства или атрибуты, которые будут объектами измерений и могут принимать разные значения при разных наблюдениях. Способы измерения данных должны соответствовать корреляциям, интересующим исследователя.
В ходе планирования эксперимента исследователь изучает, как изменения значений независимых переменных воздействуют (и воздействуют ли) на изменение значений зависимых переменных.
Наличие корреляции между значениями переменных не свидетельствует о наличии причинной связи, хотя экспериментатор, на основе каких-то других соображений, может решить интерпретировать корреляцию именно как причинно-следственное отношение. В этом случае при изучении корреляции систематическим образом манипулируют значениями независимых переменных: прослеживают их влияние на зависимые переменные, оценивают прочность связи между независимыми и зависимыми переменными. Например, можно показать, что рост и вес – две коррелированные переменные: маленькие люди обычно весят меньше, чем очень высокие, и наоборот. Это соотношение, правда, иногда
нарушается, но если исследовать очень много людей, то рост и вес действительно окажутся связанными. Имеются специальные статистические методы, посредством которых можно оценить силу связи между этими переменными. Однако само по себе это не означает, что нам известна причина данной связи. Чтобы еѐ объяснить, надо привлекать какието дополнительные факты и предположения.
Литература по Модулю 4
1.Арапов М. В. Квантитативная лингвистика. М.: Наука, 1988. 183 с.
2.Арапов М. В., Херц М. М. Математические методы в исторической лингвистике.
М.: Наука, 1974. 168 с.
3.Золотаревская Д.И. Теория вероятностей. Задачи с решениями: Учебное пособие. Изд. 6-е. М.: Книжный дом «ЛИБРОКОМ», 2009. 168 с.
4.Кемени Дж., Снелл Дж., Томпсон Дж. Введение в конечную математику. Пер. с англ. М.Г. Зайцевой. Под ред. И.М. Яглома. М.: изд. иностр. лит., 1963. 488 с.
5.Пиотровский Р.Г., Бектаев К.Б., Пиотровская А.А. Математическая лингвистика: [пособие для педагогических институтов]. Москва, Высшая школа, 1977. 383 с.
6.Тимофеева М.К. Введение в экспериментальную когнитивную лингвистику. Новосибирск, НГУ, 2010. 114 с.
7.Фрумкина Р.М. Статистические методы и стратегия лингвистического исследования // Известия АН СССР, сер. лит. и яз.у 1975, т. 34, К 2, с. 129-140.
6.Материалы для самостоятельной работы
6.1. Тренировочные задания Тренировочные задания по Модулю 1
Задание 1. Сформулируйте несколько запросов для программы WordTabulator:
a.Поиск и подсчѐт всех вхождений слов с окончанием -ая,
b.Поиск и подсчѐт всех вхождений словосочетаний из двух слов, первое из которых является однобуквенным, второе – пятибуквенным,
c.Поиск и подсчѐт всевозможных вхождений двухсловных словосочетаний с предлогом в.
Задание 2.
1.Определите отношения между понятиями населѐнный пункт, город, районный центр, станица, село; изобразите соотношения между этими понятиями с помощью схем.
2.Какие из этих понятий связаны отношением гипонимии / гиперонимии?
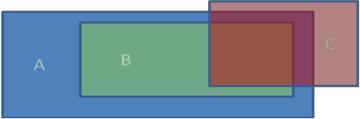
3.Каково отношение между понятиями А, В, С, если схематично это отношение можно изобразить так:

4. Придумайте примеры слов, связанных между собой отношениями а) гипонимии / гиперонимии, б) меронимии / холонимии.
Тренировочные задания по Модулю 2.
Задание 1. Опишите смыслы следующих предложений на языке логики предикатов:
Москва – столица России. Все адвокаты – юристы.
Если треугольник имеет равные стороны, то он имеет равные углы. Некоторые грибы являются съедобными.
Среди учителей есть профессионалы.
Если человек сильно захочет, он добъѐтся своего. Мексика – родина многих кактусов.
Ни один человек не имеет права нарушать закон.
Нет такого лабиринта, из которого не было бы выхода. Он и швец, и жнец, и на дуде игрец.
Задание 2. Найдите выражения, не являющиеся правильными формулами (содержащие синтаксические ошибки)
х [P(x) |
|
y Q(y)] |
[P(x) |
Q(x)] |
|
P(x) |
y |
|
х [P(x) |
|
Q(y)] |
x,y [H(x) |
F(y) M(x,y) |
|
x y [H(x) M(y)]
Задание 3. Опишите на языке логики предикатов следующие ситуации (для каждого предложения постройте отдельную формулу):
•Иванов – отличник, Петров – двоечник, Сидоров – не отличник и не двоечник. Двоечников, не ликвидировавших двойку, не переводят в следующий класс.
•Иванов играет Бендера, Петров – Балаганова, Сидоров – Паниковского. Тот, кто играет Козлевича, умеет водить машину;
•Ахиллес бежит и черепаха бежит; тот, кто первый добежит до финиша, победит; Ахиллес не заметил черепаху и побежал в другую сторону
•Имеются диван, чемодан, саквояж, картина, корзина, картонка и маленькая собачонка. Собачонка пропала. Некоторые пропавшие вещи находят.
•У некоего человека есть три говорящих попугая (серый, белый, пѐстрый). Если серый попугай разговаривает, то белый и пѐстрый тоже начинают говорить.
Задание 4. Приведѐнные ниже фразы синтаксически неоднозначны. Найдите возможные их трактовки, опишите каждую трактовку посредством формулы языка логики предикатов.
Роняет лес багряный убор.
Человек вызвал из телеателье мастера. На столе лежали новые тетради и книги. Хозяйка посадила не чѐрную смородину. Сосед поѐт и слушает оперные арии.