

9. Хранилище данных
Ясно, что принятие решений должно основываться на реальных данных о проблемной ситуации. Такая информация обычно хранится в оперативных базах данных. Но эти оперативные данные не подходят для целей анализа, так как для анализа и принятия стратегических решений в основном нужна агрегированная (обобщенная) информация. Кроме того, для целей анализа необходимо иметь возможность быстро манипулировать информацией, представлять ее в различных аспектах, производить различные нерегламентированные запросы к ней, что затруднительно реализовать на оперативных данных по соображениям производительности и технологической сложности.
Решением данной проблемы является создание отдельного хранилища данных (ХД), содержащего агрегированную информацию в удобном виде. Целью построения хранилища данных является интеграция, актуализация и согласование оперативных данных из разнородных источников для формирования единого непротиворечивого взгляда на ситуацию в целом.
Для хранилищ данных характерны следующие основные свойства:
1. Ориентация на предметную область — хранилище в первую очередь отражает специфику предметной области, а не приложений;
2. Интегрированность — информация, загружаемая в хранилище из баз, ориентиро-ванных на частные прикладные задачи, должна быть приведена к единому синтаксиче-скому семантическому виду. Важно также провести проверку поступающих данных на целостность и непротиворечивость. Чтобы при выполнении аналитических запросов из-бежать выполнения операций группирования, данные должны обобщаться (агрегировать-ся) при загрузке хранилища;
3. Неизменяемость данных — хранилищам свойственна ретроспективность: объем накопленных данных должен быть достаточным для решения аналитических задач с тре-буемым качеством. Поэтому данные после загрузки в них остаются обычно неизменными: внесение каких-либо изменений, кроме добавления записей, не предполагается;
4. Поддержка хронологии — для выполнения большинства аналитических запросов необходим анализ тенденций развития явлений или характера изменения значений пере-менных во времени, что обычно достигается введением атрибутов типа дата/время;
5. Многомерное концептуальное представление — совокупности данных могут быть проанализированы вдоль нескольких независимых измерений.
На уровне предприятия иногда выделяют организацию хранения на основе распределенных локальных БД, с использованием независимых витрин данных, двухуровневое хранение данных с использованием распределенных локальных БД и централизованногохранилища, трехуровневое хранение данных с использованием распределенных локальных БД, централизованного хранилища и витрин данных.
Независимые витрины данныхчасто появляются в организации исторически и встречаются в крупных организациях с большим количеством независимых подразделений, зачастую имеющих свои собственные отделы информационных технологий.

Витрины – это предметно-ориентированные хранилища как правило агрегированной информации, предназначенное для использования группой пользователей в рамках конкретного вида деятельности. Витрины проектируются для ответов на конкретный ряд вопросов. Данные в витрине оптимизированы для использования определенными группами пользователей, что облегчает процедуры их наполнения, а также способствует повышению производительности
Недостатки:
Данные хранятся многократно в различных витринах данных. Это приводит к дублированию данных и, как следствие, к увеличению расходов на хранение и потенциальным проблемам, связанным с необходимостью поддержания непротиворечивости данных
Данные не консолидируются на уровне предприятия, таким образом, отсутствует единая картина бизнеса
Двухуровневое хранилище данныхстроится централизованно для предоставления информации в рамках компании. Это означает, что вся организация должна согласовать все определения и процессы преобразования данных.

Преимущества:
Данные хранятся в единственном экземпляре
Минимальные затраты на хранение данных
Отсутствуют проблемы, связанные с синхронизацией нескольких копий данных
Данные консолидируются на уровне предприятия, что позволяет иметь единую картину бизнеса
Недостатки:
Данные не структурируются для поддержки потребностей отдельных пользователей или групп пользователей
Возможны проблемы с производительностью системы
Возможны трудности с разграничением прав пользователей на доступ к данным
Концепция хранилищ данных предполагает не просто единый логический взгляд на данные организации, а действительную реализацию единого интегрированного источника данных. Альтернативным по отношению к этой концепции способом формирования единого взгляда на корпоративные данные является создание виртуального источника, опирающегося на распределенные локальные БД различных систем. При этом каждый запрос к такому источнику динамически транслируется в запросы к исходным базам данных, а полученные результаты на лету согласовываются, связываются, агрегируются и возвращаются к пользователю. Однако такой способ обладает рядом существенных недостатков.
Время обработки запросов к распределенному хранилищу значительно превышает соответствующие показатели для централизованного хранилища.
Интегрированный взгляд на распределенное корпоративное хранилище возможен только при выполнении требования постоянной связи всех источников данных в сети. Таким образом, временная недоступность хотя бы одного из источников может либо сделать работу информационной системы невозможной, либо привести к ошибочным результатам.
Выполнение сложных аналитических запросов над таблицами СОД потребляет большой объем ресурсов сервера БД.
Различные распределенные локальные БД могут поддерживать разные форматы и кодировки данных, данные в них могут быть несогласованы. Часто на один и тот же вопрос может быть получено несколько вариантов ответа, что может быть связано с несинхронностью моментов обновления данных, отличиями в трактовке отдельных событий, понятий и данных, изменением семантики данных в процессе развития предметной области, ошибками при вводе, утерей фрагментов архивов и т. д. В таком случае цель – формирование единого непротиворечивого взгляда на объект управления – может не быть достигнута.
Часто локальные БД не могут позволить себе роскошь хранить данные за длительный период времени, по мере устаревания данные выгружаются в архив и удаляются. В результате часто нужные данные оказываются недоступными, отсутствует практическая возможность обзора длительных исторических последовательностей данных.
Хранилище данных функционирует по следующему сценарию. По заданному регламенту в него собираются данные из различных источников – баз данных систем оперативной обработки. В хранилище поддерживается хронология: наравне с текущими хранятся исторические данные с указанием времени, к которому они относятся. В результате необходимые доступные данные об объекте управления собираются в одном месте, приводятся к единому формату, согласовываются и, в ряде случаев, агрегируются до минимально требуемого уровня обобщения.
Трёхуровневое хранилище данных
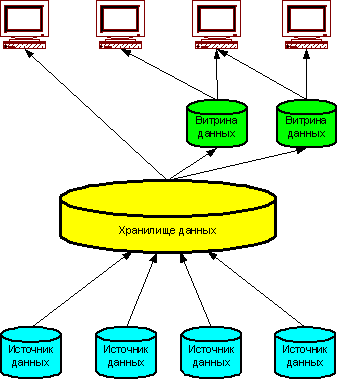
Хранилище данных представляет собой единый централизованный источник корпоративной информации. Витрины данных представляют подмножества данных из хранилища, организованные для решения задач отдельных подразделений компании. Конечные пользователи имеют возможность доступа к детальным данным хранилища, в случае если данных в витрине недостаточно, а также для получения более полной картины состояния бизнеса.
Преимущества:
Создание и наполнение витрин данных упрощено, поскольку наполнение происходит из единого стандартизованного надежного источника очищенных нормализованных данных
Витрины данных синхронизированы и совместимы с корпоративным представлением. Имеется корпоративная модель данных. Существует возможность сравнительно лёгкого расширения хранилища и добавления новых витрин данных
Недостатки:
Существует избыточность данных, ведущая к росту требований на хранение данных
Требуется согласованность с принятой архитектурой многих областей с потенциально различными требованиями (например, скорость внедрения иногда конкурирует с требованиями следовать архитектурному подходу)
10. Информация хранится в базах данных, базах знаний и должна быть соответствующим образом структурирована.
База данных может быть определена как совокупность различных типов записей и отношений между элементами, записями и сегментами данных. Банк данных содержит информацию о характеристиках и признаках ситуаций, в том числе признаках появления, возможных причинах возникновения, важности, директивном времени и т.д. Каждый представленный в базе данных объект должен имел определенную совокупность описывающих его атрибутов. Кроме того, требуется, чтобы существовали правила, позволяющие сопоставить эти атрибуты. Структурирование данных связано с использованием одной из трех моделей данных: реляционной, иерархической и сетевой.
База знаний создается на этапе обучения создаваемая на основе обработки экспертной информации. Подсистема знаний представляет собой организованную совокупность знаний системы в проблемной области. Эти знания содержат большие объёмы фактов и отношений между ними. Цель подсистемы знаний - получение выводов, представляющих собой эффективные рекомендации по принятию решения. Насколько качественно
будут структурированы исходные данные и профессиональные знания;
сформированы новые знания, положенные в основу баз знаний;
подобрана математическая модель представления данных и знаний
зависит оперативность и качество принимаемых решений СППР.
В рамках СППР можно выделить 3 типа знаний:
- структурированные статические знания о предметной области (декларативные (экстенсиональные) знания) после того, как эти знания выявлены они уже не изменяются. Эти знания представляют собой свойства, события, эмпирические факты, хорошо известные в исследуемой предметной области.
- структурированные динамические знания – изменяемые знания о предметной области, которые обновляются по мере выявления новой информации. Обычно эти знаний основываются на собственном опыте эксперта, накопленном в результате многолетней практики, в силу этого они являются эвристическими, экспериментальными, неопределенными и оперируют абстрактными объектами, событиями и отношениями. Но, тем не менее, специалисты отмечают, что именно эта категория знаний играет решающую роль в повышении эффективности систем принятия решений.
- текущие знания – используются для решения конкретных задач и проведения консультаций
При разработке СППР неизбежно возникает о выборе модели представления данных и знаний.
Представление знаний – это формализация и структурирование (в целях облегчения решения задачи) знаний, с помощью которых отражаются основные характерные признаки: внутренняя интерпретируемость, структурированность,связность», семантическая метрика и др.
Модель представления знаний определяется выбранными средствами, с помощью которых можно адекватно описать предметную область. В настоящее время наиболее проработанными и традиционно используемыми моделями представления данных являются иерархическая, сетевая и реляционная модели, а для представления знаний – семантические сети, фреймы, логические модели и системы продукций.
Иерархическая модель данных – это модель представления элементов данных и связей между элементами данных в виде древовидных структур.
Сетевая модель данных реализуется на основе ориентированных графов, где вершинам графа соответствуют специальным образом организованные данные, а дугам – типы связей между этими данными.
Реляционная модель данных базируется на теоретико-множественном понятии отношения, то есть множества кортежей фиксированной длины. Где каждый кортеж задает описание объекта в виде множества значений признаков, а связи между элементами данных задаются путем включения одинаковых признаков в разные отношения. На логическом уровне реляционная модель представляется набором связанных между собой таблиц с данными.
В представлении знаний семантическая сеть – это ориентированный граф, вершины которого – понятия (абстрактные или конкретные объекты), а дуги – отношения между ними.
Помимо произвольных отношений, специфических для предметной области, семантические сети включают следующие характерные типы отношений: класс - подкласс (человек - студент); часть - целое (книга - обложка); класс - экземпляр (пример) класса (человек - Иван Петров); свойство - значение: название (цвет - красный).
Проблема поиска решения сводится к задаче поиска фрагмента сети, соответствующего некоторой подсети, представляющей ответ на поставленный вопрос. Основным преимуществом этой модели является то, что она достаточно хорошо согласуется ссовременным представлениям об организации долговременной памяти человека. Недостатком этой модели является сложность организации процедуры поиска вывода на семантической сети.
Фрейм - это представление знаний в виде объектов и отношений между объектами. Основными понятиями являются понятия структуры, объекта, слота, атрибута, значения.
Структурно состоят из имени фрейма и слотов, прнимающих конкретные значения атрибутов фрейма.
Имя фрейма:
Имя слота 1 (значение слота 1)
Имя слота 2 (значение слота 2)
... ... ... ... ... ... ...
Имя слота К (значение слота К).
При конкретизации фрейма ему и слотаему и слотам присваиваются конкретные имена и происходит заполнение слотов. Например, у фрейма с именем «комната» могут быть слоты с именами «высота», «ширина», «число окон» и т.д.
Существуют следующие разновидности фреймов, позволяющие отобразить достаточно многообразные знания о мире:
• фреймы-структуры, использующиеся для обозначения объектов и понятий (банк, комната, стол);
• фреймы-роли (администратор, машинист, студент);
• фреймы-сценарии (сдача экзамена, образование юридического лица, верстка газе-ты);
• фреймы-ситуации (тревога, авария, рабочий режим устройства) и др.
Различают фреймы-образцы, или прототипы, хранящиеся в базе знаний, и фреймы-экземпляры, которые создаются для отображения реальных фактических ситуаций на основе поступающих данных.
Фреймы могут объединяться в сети наподобие семантических. Предметная область описывается некоторой иерархической структурой. Из теории семантических сетей фреймы также заимствовали наследование свойств: фреймы, занимающие более низкое положений, наследуют свойства фреймов более высокого уровня.
Логические модели Основная идея при построении логических моделей знаний заключается в том, что вся информация, необходимая для решения прикладных задач, рассматривается как совокупность фактов и утверждений, которые представляются как формулы в некоторой логике. Знания отображаются совокупностью таких формул, а получение новых знаний сводится к реализации процедур логического вывода.
Продукционная модель представления знаний оперирует с правилами импликативного вида «Если А, то В», называемыми продукциями и задающими элементарные шаги преобразований и умозаключений, где левая часть правил является посылкой (причиной), а правая – заключением (следствием).вместо логического вывода применяется вывод на знаниях. Достоинствами этой модели являются наглядность, высокая модульность, легкость внесения дополнений и изменений и простота механизма логического вывода.
11. Принятие решения базируется на анализе оперативных текущих данных с учетом информации, находящейся в хранилищах и выявлении зависимостей между данными. Можно выделить два основных подхода:
1) пользователь сам производит анализ и выдвигает гипотезы относительно зависимостей между данными. Такой подход реализован, например, в рамках такого развитого средства как OLAP, (см. п.11), поскольку в нем процесс поиска по-прежнему полностью контролируется человеком. Во многих системах при этом автоматизирована проверка достоверности гипотез, что позволяет оценить вероятность тех или иных зависимостей в базе данных. Типичным примером может служить, такой вывод: вероятность того, что рост продаж продукта А обусловлен ростом продаж продукта В, составляет 0,75;
2) поиск закономерностей возлагается на компьютер. Для реализации такого подхода используются методы автоматического интеллектуального анализа данных. Этот подход, хотя и интенсивно развивающийся, находится еще на этапе становления
В настоящее время сложилась следующая ситуация:
- объемы подлежащих анализу данных для принятия эффективных решений обычно очень велики. Современный уровень развития аппаратных и программных средств с некоторых пор сделал возможным повсеместное ведение баз данных оперативной информации на разных уровнях управления. В процессе своей деятельности предприятия, корпорации, ведомственные структуры, органы государственной власти накопили большие объемы данных. Они хранят в себе большие потенциальные возможности по извлечению полезной аналитической информации, на основе которой можно выявлять скрытые тенденции, строить стратегию развития, находить новые решения;
- человеческий разум сам по себе не приспособлен для восприятия больших массивов разнородной информации. Человек к тому же не способен улавливать более двух-трех взаимосвязей даже в небольших выборках;
- созданы необходимые технические предпосылки для автоматизации подобного анализа - современные компьютеры по своим техническим характеристикам способны, в отличие от своих относительно недавних предшественников, решать очень трудоемкие (в частности, переборные) задачи
В такой ситуации большой интерес представляет автоматизация интеллектуального анализа данных, позволяющего провести наиболее полный и глубокий анализ проблемы, дающего возможность обнаружить скрытые взаимосвязи, принять наиболее обоснованное решение.
12. Комплексный взгляд на собранную информацию, ее обобщение и агрегация, многомерный анализ являются задачамисистем оперативной аналитической обработки данных — OLAP (On-LineAnalyticalProcessing).Основное назначение OLAP-технологий– подготовка информацию для принятия решения на основе динамического многомерного анализа данных, моделирования и прогнозирования. Часто при этом используются различные статистические группировки данных
В основе концепции оперативной аналитической обработки OLAP лежит многомерное представление данных, позволяющее объединять, просматривать и анализировать данные с точки зрения множественности измерений, наблюдать данные в различных измерениях, направлениях или сечениях, что отражаетестественный взгляд аналитиков на объект управления.OLAP расширяет функциональность реляционных СУБД и включает многомерный анализ как одну из своих характеристик.
Многомерное представление означает собой множественную перспективу, состоящую из нескольких независимых измерений, вдоль которых могут быть проанализированы определенные совокупности данных.Можно сказать, что в основе OLAP лежит понятие гиперкуба, или многомерного куба данных, в ячейках которого хранятся анализируемые (числовые) данные, например объемы продаж. Измерения представляют собой совокупности значений других данных, скажем названий товаров и названий месяцев года. В простейшем случае двумерного куба (квадрата) мы получаем таблицу, показывающую значения уровней продаж по товарам и месяцам.
Одновременный анализ по нескольким измерениям данных определяется как многомерный анализ.
Каждое измерение включает направления консолидации данных, состоящие из серии последовательных уровней обобщения, где каждый вышестоящий уровень соответствует большей степени агрегации данных по соответствующему измерению. Так, измерение Исполнитель может определяться направлением консолидации, состоящим из уровней обобщения «предприятие – подразделение – отдел – служащий». Измерение Время может даже включать два направления консолидации – «год – квартал – месяц – день» и «неделя – день», поскольку счет времени по месяцам и по неделям несовместим. В этом случае становится возможным произвольный выбор желаемого уровня детализации информации по каждому из измерений. Операция спуска соответствует движению от высших ступеней консолидации к низшим; напротив, операция подъема означает движение от низших уровней к высшим.
Усложнение модели данных может идти по нескольким направлениям:
увеличение числа измерений - данные о продажах не только по месяцам и товарам, но и по регионам. В этом случае куб становится трехмерным;
усложнение содержимого ячейки – например, нас может интересовать не только уровень продаж, но и, скажем, чистая прибыль или остаток на складе. В этом случае в ячейке будет несколько значений;
введение иерархии в пределах одного измерения - общее понятие ВРЕМЯ естественным образом связано с иерархией значений: год состоит из кварталов, квартал из месяцев и т. д.
Все данные, необходимые для принятия решений, предварительно агрегированы на всех соответствующих уровнях и организованы так, чтобы обеспечить максимально быстрый доступ к ним.
Основатель OLAP Кодд определил 12 правил, которым должен удовлетворять программный продукт класса OLAP (таб. 2.1).
Таблица Правила оценки программных продуктов класса OLAP
|
№ |
Правило |
Описание |
|
1. |
Многомерное концептуальное представление данных |
Концептуальное представление модели данных в продукте OLAP должно быть многомерным по своей природе, то есть позволять аналитикам выполнять интуитивные операции "анализа вдоль и поперек", вращения и размещения направлений консолидации, т.е. выполнять анализ вдоль нескольких независимых измерений. Каждое измерение включает направления консолидации данных, состоящие из серии последовательных уровней обобщения, где каждый вышестоящий уровень соответствует большей степени агрегации данных по соответствующему измерению. |
|
2. |
Прозрачность |
Пользователь не должен знать о том, какие конкретные средства используются для хранения и обработки данных, как данные организованы и откуда берутся. |
|
3. |
Доступность |
Аналитик должен иметь возможность выполнять анализ в рамках общей концептуальной схемы, но при этом данные могут оставаться под управлением оставшихся от старого наследства СУБД, будучи при этом привязанными к общей аналитической модели. То есть инструментарий OLAP должен накладывать свою логическую схему на физические массивы данных, выполняя все преобразования, требующиеся для обеспечения единого, согласованного и целостного взгляда пользователя на информацию. |
|
4. |
Устойчивая производительность |
С увеличением числа измерений и размеров БД аналитики не должны столкнуться с каким бы то ни было уменьшением производительности. Устойчивая производительность необходима для поддержания простоты использования и свободы от усложнений, которые требуются для доведения OLAP до конечного пользователя. |
|
5. |
Клиент - серверная архитектура |
Большая часть данных, требующих оперативной аналитической обработки, хранится в мэйнфреймовых системах, а извлекается с персональных компьютеров. Поэтому одним из требований является способность продуктов OLAP работать в среде клиент-сервер. Главной идеей здесь является то, что серверный компонент инструмента OLAP должен быть достаточно интеллектуальным и обладать способностью строить общую концептуальную схему на основе обобщения и консолидации различных логических и физических схем корпоративных баз данных для обеспечения эффекта прозрачности. |
|
6. |
Равноправие измерений |
Все измерения данных должны быть равноправны. Дополнительные характеристики могут быть предоставлены отдельным измерениям, но поскольку все они симметричны, данная дополнительная функциональность может быть предоставлена любому измерению. Базовая структура данных, формулы и форматы отчетов не должны опираться на какое-то одно измерение. |
|
7. |
Динамическая обработка разреженных матриц |
Инструмент OLAP должен обеспечивать оптимальную обработку разреженных матриц. Скорость доступа должна сохраняться вне зависимости от расположения ячеек данных и быть постоянной величиной для моделей, имеющих разное число измерений и различную разреженность данных. |
|
8. |
Поддержка многопользовательского режима |
Зачастую несколько аналитиков имеют необходимость работать одновременно с одной аналитической моделью или создавать различные модели на основе одних корпоративных данных. Инструмент OLAP должен предоставлять им конкурентный доступ, обеспечивать целостность и защиту данных. |
|
9. |
Неограниченная поддержка кроссмерных операций |
Вычисления и манипуляция данными по любому числу измерений не должны запрещать или ограничивать любые отношения между ячейками данных. Преобразования, требующие произвольного определения, должны задаваться на функционально полном формульном языке. |
|
10. |
Интуитивное манипулирование данными) |
Переориентация направлений консолидации, детализация данных в колонках и строках, агрегация и другие манипуляции, свойственные структуре иерархии направлений консолидации, должны выполняться в максимально удобном, естественном и комфортном пользовательском интерфейсе. |
|
11. |
Гибкий механизм генерации отчетов) |
Должны поддерживаться различные способы визуализации данных, то есть отчеты должны представляться в любой возможной ориентации. |
|
12. |
Неограниченное количество измерений и уровней агрегации |
Настоятельно рекомендуется допущение в каждом серьезном OLAP инструменте как минимум пятнадцати, а лучше двадцати, измерений в аналитической модели. Более того, каждое из этих измерений должно допускать практически неограниченное количество определенных пользователем уровней агрегации по любому направлению консолидации. |
Набор этих требований, послуживших фактическим определением OLAP, следует рассматривать как рекомендательный, а конкретные продукты оценивать по степени приближения к идеально полному соответствию всем требованиям.
13. Интеллектуальный анализ данных (ИАД)
В настоящее время широко распространение получило такое направление аналитической технологии обработки данных как ИАД. Нередко наряду с ИАД говорят о Data Mining ("добыча" или "раскопка данных") или "обнаружении знаний в базах данных". Их можно считать синонимами ИАД. Возникновение всех указанных терминов связано с новым витком в развитии средств и методов обработки данных.
ИАД (DataMining) - это процесс поддержки принятия решений, основанный на поиске в данных скрытых закономерностей (шаблонов информации). При этом накопленные сведения автоматически обобщаются до информации, которая может быть охарактеризована как знания.
Как уже отмечалось, человеческий разум сам по себе не приспособлен для восприятия больших массивов разнородной информации. Да и традиционная математическая статистика, долгое время претендовавшая на роль основного инструмента анализа данных, также нередко пасует при решении задач из реальной сложной жизни. Она оперирует усредненными характеристиками выборки, которые часто являются фиктивными величинами (типа средней температуры пациентов по больнице, средней высоты дома на улице, состоящей из дворцов и лачуг и т.п.). Поэтому методы математической статистики оказываются полезными главным образом для проверки заранее сформулированных гипотез.
Современные технологии ИАД перелопачивают информацию с целью автоматического поиска шаблонов (паттернов), характерных для каких-либо фрагментов неоднородных многомерных данных. В отличие от оперативной аналитической обработки данных OLAP в ИАД бремя формулировки гипотез и выявления необычных, непредсказуемых шаблонов переложено с человека на компьютер.
В принципе в постановке задачи ИАД нет ничего нового. Специалисты на протяжении нескольких последних десятков лет решали подобные задачи ("поиск эмпирических закономерностей", "эвристический поиск в сложных средах", "индуктивный вывод" и т. п.). Но только сейчас общество в целом созрело для понимания практической важности и широты этих задач. Во-первых, в связи с развитием технологий записи и хранения данных сегодня на людей обрушились колоссальные потоки информации в самых различных областях, которые без продуктивной переработки грозят превратиться в никому не нужные свалки. И, во-вторых, средства и методы обработки данных стали доступными и удобными, а их результаты понятными любому человеку.
Процессы ИАД подразделяются на три большие группы: поиск зависимостей, прогнозирование и анализ аномалий. Поиск зависимостей состоит в просмотре базы данных с целью автоматического выявления зависимостей. Проблема здесь заключается в отборе действительно важных зависимостей из огромного числа существующих в БД. Прогнозирование предполагает, что пользователь может предъявить системе записи с незаполненными полями и запросить недостающие значения. Система сама анализирует содержимое базы и делает правдоподобное предсказание относительно этих значений. Анализ аномалий - это процесс поиска подозрительных данных, сильно отклоняющихся от устойчивых зависимостей.
Можно сказать, что в общем случае процесс ИАД состоит из трёх стадий:
выявление закономерностей;
использование выявленных закономерностей для предсказания неизвестных значений (прогностическое моделирование);
анализ исключений, предназначенный для выявления и толкования аномалий в найденных закономерностях.
В системах ИАД применяется чрезвычайно широкий спектр математических, логических и статистических методов. Пока трудно говорить о перспективности или предпочтительности тех или иных методов. Технология ИАД находится в начале пути, и практического материала для каких-либо рекомендаций или обобщений явно недостаточно.
Выделяют пять стандартных типов закономерностей, которые позволяют выявлять методы ИАД:
ассоциация
последовательность
классификация
кластеризация
прогнозирование
Ассоциацияимеет место в том случае, если несколько событий связаны друг с другом. Например, исследование, проведенное в супермаркете, может показать, что 65% купивших кукурузные чипсы берут также и "кока-колу", а при наличии скидки за такой комплект "колу" приобретают в 85% случаев. Располагая сведениями о подобной ассоциации, менеджерам легко оценить, насколько действенна предоставляемая скидка.
Если существует цепочка связанных во времени событий, то говорят о последовательности. Так, например, после покупки дома в 45% случаев в течение месяца приобретается и новая кухонная плита, а в пределах двух недель 60% новоселов обзаводятся холодильником.
С помощью классификациивыявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил.
Кластеризацияотличается от классификации тем, что сами группы заранее не заданы. С помощью кластеризации средства ИАД самостоятельно выделяют различные однородные группы данных.
Основой для всевозможных систем прогнозированияслужит историческая информация, хранящаяся в БД в виде временных рядов. Если удается построить математическую модель и найти шаблоны, адекватно отражающие эту динамику, есть вероятность, что с их помощью можно предсказать и поведение системы в будущем.
Новыми компьютерными технологиями, образующими ИАД являются экспертные и интеллектуальные системы, методы искусственного интеллекта, базы знаний, базы данных, нейронные сети, нечеткие системы. Современные технологии ИАД позволяют создавать новое знание, в автоматическом и автоматизированном режиме отыскивать скрытые зависимости и взаимосвязи в огромных массивах информации. Перспективно применение в СППР комбинированных методов принятия решений в сочетании с технологиями ИАД, методами искусственного интеллекта и компьютерным моделированием, различные имитационно-оптимизационные процедуры, принятие решений в сочетании с экспертными процедурами.
14 Математическое обеспечение интеллектуального анализа, применяемые в системах поддержки принятия решений:
- методы статистической обработки данных, которые можно разделить на четыре взаимосвязанных раздела:
предварительный анализ природы статистических данных (проверка гипотез стационарности, нормальности, независимости, однородности, оценка вида функции распределения и ее параметров);
выявление связей и закономерностей (линейный и нелинейный регрессионный анализ, корреляционный анализ);
многомерный статистический анализ (линейный и нелинейный дискриминантный анализ, кластер-анализ, компонентный анализ, факторный анализ);
динамические модели и прогноз на основе временных рядов.
- методы, основанные на нечетких множествах. Их применение позволяет ранжировать данные по степени близости к желаемым результатам, осуществлять так называемый нечеткий поиск в базах данных. Однако платой за повышенную универсальность является снижение уровня достоверности и точности получаемых результатов.
- методы нейронных сетей, эволюционного и генетического программирования. Однако, решения, полученные этими методами, часто не допускают наглядных интерпретаций, что в определенной степени усложняет работу предметных экспертов;
- синергетические методы. Их применение позволяет реально оценить горизонт долгосрочного прогноза. Особенный интерес вызывают исследования, связанные с попытками построения эффективных систем управления в неустойчивых режимах функционирования.
- традиционные методы решения оптимизационных задач - вариационные методы, методы исследования операций, включающие в себя различные виды математического программирования (линейное, нелинейное, дискретное, целочисленное), динамическое программирование, методы теории систем массового обслуживания. Программные реализации большинства этих методов входят в стандартные пакеты прикладных программ, например Math CAD и MatLab.
- методы, связанные с непосредственным использованием опыта эксперта. К их числу относят, например, метод «ближайшего соседа».
- методы, связанные с построением дерева решений, в каждом узле которого эксперт осуществляет простейший логический выбор («да» - «нет»). В зависимости от принятого выбора, поиск решения продвигается по правой или левой ветви дерева и в конце концов приходит к терминальной ветви, отвечающей конкретному окончательному решению.
- экспертные методы предметно-ориентированного анализа ситуаций и прогнозирования. Роль эксперта состоит в выборе наиболее адекватной системы и интерпретации полученного алгоритма. Достоинства и недостатки таких систем очевидны - предельная простота и доступность применения и расплата достоверностью и точностью за эту простоту.
- методы визуализации данных и результатов их анализа, позволяющие наглядно отображать полученные выводы для создания у предметных экспертов и/или руководителей проектов единой картины ситуации.
15 Типы систем интеллектуального анализа данных по используемым методам
Очень важной особенностью интеллектуальной системы является то, что сама логика взаимодействия ее с пользователем обычно диктуется процессом решения функциональной задачи, и поэтому работа с такой системой выглядит для него, как ни парадоксально, гораздо проще и естественнее, чем в справочной системе.
Большие преимущества применение технологий интеллектуальных систем дает там, где область управления располагает большими объемами накопленной информации - базами данных. Это дает возможность их обобщения и, например, для решения задач планирования, прогнозирования и т.п. Интеллектуальная система формирует обычно один или несколько вариантов решения в порядке предпочтения.
Все наиболее распространенные методологии структурного подхода базируются на ряде общих принципов. В качестве двух базовых принципов используются следующие: принцип декомпозиции - решения сложных проблем путем их разбиения на множество меньших независимых задач, легких для понимания и решения; принцип иерархического упорядочивания - организации составных частей проблемы в иерархические древовидные структуры с добавлением новых деталей на каждом уровне. Выделение двух базовых принципов не означает, что остальные принципы являются второстепенными, поскольку игнорирование любого из них может привести к непредсказуемым последствиям (в том числе и к провалу всего проекта). Основными из этих принципов являются следующие: принцип абстрагирования - заключается в выделении существенных аспектов системы и отвлечения от несущественных; принцип формализации - заключается в необходимости строгого методического подхода к решению проблемы; принцип непротиворечивости - заключается в обоснованности и согласованности элементов; принцип структурирования данных - заключается в том, что данные должны быть структурированы и иерархически организованы.
Главной особенностью ИАД является сочетание последних достижений в области компьютерных технологий с широким спектром математических инструментов - от фундаментальных статистических методов регрессионного и многофакторного дисперсионного анализа до новых кибернетических алгоритмов, основанных на нейронных сетях, эволюционном моделировании и т.п. ИАД сочетает строго формализованные математические технологии анализа количественной информации с методами неформального качественного анализа, опирающегося на субъективные знания экспертов. ИАД осуществляет аналитическую обработку сверхбольших объемов данных, содержащихся в информационном хранилище в интересах, прежде всего, решения задачи формирования наилучших (в некотором, заранее определенном смысле) проектов искомых решений. По существу, методология ИАД сводится к структуризации прогностической информации на основе машинного анализа ретроспективных данных.
Главным отличием аналитических информационных систем, использующих методологию ИАД, является попытка подойти к задаче формирования решения с позиции историзма, т.е. на основе полномасштабного количественного анализа всего предшествующего опыта, отраженного в данных в системах хранения информации.
С учетом приведенного выше (см. п. 13) математического обеспечения можно выделить следующие классы систем интеллектуального анализа данных
Предметно-ориентированные аналитические системыочень разнообразны. Наиболее широкий подкласс таких систем, получивший распространение в области исследования финансовых ранков, носит название "технический анализ". Он представляет собой совокупность нескольких десятков методов прогноза динамики цен и выбора оптимальной структуры инвестиционного портфеля, основанных на различных эмпирических моделях динамики рынка.
Статистические пакеты- хотя последние версии почти всех известных статистических пакетов включают наряду с традиционными статистическими методами также элементы ИАД, основное внимание в них уделяется все же классическим методикам — корреляционному, регрессионному, факторному анализу и другим. Недостатком систем этого класса считают требование к специальной подготовке пользователя. Также отмечают, что мощные современные статистические пакеты являются слишком "тяжеловесными" для массового применения в финансах и бизнесе.
Есть еще более серьезный принципиальный недостаток статистических пакетов, ограничивающий их применение в ИАД. Большинство методов, входящих в состав пакетов опираются на статистическую парадигму, в которой главными фигурантами служат усредненные характеристики выборки. А эти характеристики при исследовании реальных сложных жизненных феноменов часто являются фиктивными величинами.
Нейронные сети— это большой класс систем, архитектура которых пытается имитировать построение нервной ткани из нейронов. В одной из наиболее распространенных архитектур, многослойном перцептроне с обратным распространением ошибки, эмулируется работа нейронов в составе иерархической сети, где каждый нейрон более высокого уровня соединен своими входами с выходами нейронов нижележащего слоя. На нейроны самого нижнего слоя подаются значения входных параметров, на основе которых нужно принимать какие-то решения, прогнозировать развитие ситуации и т. д. Эти значения рассматриваются как сигналы, передающиеся в вышележащий слой, ослабляясь или усиливаясь в зависимости от числовых значений (весов), приписываемых межнейронным связям. В результате на выходе нейрона самого верхнего слоя вырабатывается некоторое значение, которое рассматривается как ответ, реакция всей сети на введенные значения входных параметров. Для того чтобы сеть можно было применять в дальнейшем, ее прежде надо "натренировать" на полученных ранее данных, для которых известны и значения входных параметров, и правильные ответы на них. Эта тренировка состоит в подборе весов межнейронных связей, обеспечивающих наибольшую близость ответов сети к известным правильным ответам.
Основным недостатком нейросетевой парадигмы является необходимость иметь очень большой объем обучающей выборки. Другой существенный недостаток заключается в том, что даже натренированная нейронная сеть представляет собой черный ящик. Знания, зафиксированные как веса нескольких сотен межнейронных связей, совершенно не поддаются анализу и интерпретации человеком (известные попытки дать интерпретацию структуре настроенной нейросети выглядят неубедительными.
Системы на основе прецедентности- системы рассуждений на основе аналогичных случаев (прецедентов) на первый взгляд крайне проста. Для того чтобы сделать прогноз на будущее или выбрать правильное решение, эти системы находят в прошлом близкие аналоги наличной ситуации и выбирают тот же ответ, который был для них правильным. Системы на основе принятия решения по прецедентности показывают очень хорошие результаты в самых разнообразных задачах. Главным их минусом считают то, что они вообще не создают каких-либо моделей или правил, обобщающих предыдущий опыт, — в выборе решения они основываются на всем массиве доступных исторических данных, поэтому невозможно сказать, на основе каких конкретно факторов системы строят свои ответы. Проблематичен также вопрос выбора меры "близости". От этой меры самым решительным образом зависит объем множества прецедентов, которые нужно хранить в памяти для достижения удовлетворительной классификации или прогноза.
Деревья решенияявляются одним из наиболее популярных подходов к решению задач ИАД. Они создают иерархическую структуру классифицирующих правил типа "ЕСЛИ... ТО...", имеющую вид дерева (это похоже на определитель видов из ботаники или зоологии). Для того чтобы решить, к какому классу отнести некоторый объект или ситуацию, требуется ответить на вопросы, стоящие в узлах этого дерева, начиная с его корня. Вопросы имеют вид "значение параметра A больше x?". Если ответ положительный, осуществляется переход к правому узлу следующего уровня, если отрицательный — то к левому узлу; затем снова следует вопрос, связанный с соответствующим узлом.
Популярность подхода связана с наглядностью и понятностью. Но очень остро для деревьев решений стоит проблема значимости. Дело в том, что отдельным узлам на каждом новом построенном уровне дерева соответствует все меньшее и меньшее число записей данных — дерево дробит данные на большое количество частных случаев. Чем больше этих частных случаев, чем меньше обучающих примеров попадает в каждый такой частный случай, тем менее уверенной становится их классификация. Если построенное дерево слишком "кустистое" — состоит из неоправданно большого числа мелких веточек ≈ оно не будет давать статистически обоснованных ответов. Как показывает практика, в большинстве систем, использующих деревья решений, эта проблема не находит удовлетворительного решения. Кроме того, общеизвестно, и это легко показать, что деревья решений дают полезные результаты только в случае независимых признаков. В противном случае они лишь создают иллюзию логического вывода.
Эволюционное программирование- проиллюстрируем современное состояние эволюционного программирования на примере системы PolyAnalyst. В данной системе гипотезы о виде зависимости целевой переменной от других переменных формулируются в виде программ на некотором внутреннем языке программирования. Процесс построения программ строится как эволюция в мире программ (этим подход немного похож на генетические алгоритмы). Когда система находит программу, достаточно точно выражающую искомую зависимость, она начинает вносить в нее небольшие модификации и отбирает среди построенных таким образом дочерних программ те, которые повышают точность. Таким образом система "выращивает" несколько генетических линий программ, которые конкурируют между собой в точности выражения искомой зависимости. Специальный транслирующий модуль системы PolyAnalyst переводит найденные зависимости с внутреннего языка системы на понятный пользователю язык (математические формулы, таблицы и пр.), делая их легкодоступными. Для того чтобы сделать полученные результаты еще понятнее для пользователя-нематематика, имеется богатый арсенал разнообразных средств визуализации обнаруживаемых зависимостей. Для контроля статистической значимости выводимых зависимостей применяется набор современных методов, например рандомизированное тестирование.
Пусть нам надо найти решение задачи, наиболее оптимальное с точки зрения некоторого критерия. Пусть каждое решение полностью описывается некоторым набором чисел или величин нечисловой природы. Скажем, если нам надо выбрать совокупность фиксированного числа параметров рынка, наиболее выраженно влияющих на его динамику, это будет набор имен этих параметров. Об этом наборе можно говорить как о совокупности хромосом, определяющих качества индивида — данного решения поставленной задачи. Значения параметров, определяющих решение, будут тогда называться генами. Поиск оптимального решения при этом похож на эволюцию популяции индивидов, представленных их наборами хромосом. В этой эволюции действуют три механизма: отбор сильнейших — наборов хромосом, которым соответствуют наиболее оптимальные решения; скрещивание — производство новых индивидов при помощи смешивания хромосомных наборов отобранных индивидов; и мутации ≈ случайные изменения генов у некоторых индивидов популяции. В результате смены поколений в конце концов вырабатывается такое решение поставленной задачи, которое уже не может быть далее улучшено.
Генетические алгоритмы имеют ряд недостатков. Критерий отбора хромосом и сама процедура являются эвристическими и далеко не гарантируют нахождения «лучшего» решения. Как и в реальной жизни, эволюцию может «заклинить» на какой-либо непродуктивной ветви. И, наоборот, можно привести примеры, как два неперспективных родителя, которые будут исключены из эволюции генетическим алгоритмом, оказываются способными произвести высокоэффективного потомка. Это особенно становится заметно при решении высокоразмерных задач со сложными внутренними связями.
Алгоритмы ограниченного переборабыли предложены в середине 60-х гг. для поиска логических закономерностей в данных. С тех пор они продемонстрировали свою эффективность при решении множества задач из самых различных областей.
Эти алгоритмы вычисляют частоты комбинаций простых логических событий в подгруппах данных. Примеры простых логических событий: X = a; X < a; X > a; a < X < b и др., где X — какой либо параметр, a и b — константы. Ограничением служит длина комбинации простых логических событий. На основании анализа вычисленных частот делается заключение о полезности той или иной комбинации для установления ассоциации в данных, для классификации, прогнозирования и пр. Наиболее ярким современным представителем этого подхода является система WizWhy предприятия WizSoft, на практике продемонстрировавшая высокую эффективность при решении реальных задач.
15 . Главной подсистемой, которая управляет работой СППР, является ядро (диспетчер). Оно принимает запросы от интерфейса пользователя и преобразует их в вызовы процедур, содержащихся в библиотеке методов и моделей. Интерфейсом между ядром и СУБД служит подсистема манипулирования данными. Ядро формирует символьные строки команд для работы с базой данных и переадресует их для выполнения в подсистему манипулирования данными. Эта подсистема «знает», где находится база данных: на локальной машине или на другом сервере в локальной сети. Подсистема манипулирования данными выполняет команды и сообщает ядру результат: выполнено успешно или с ошибкой. Результаты запросов на выборку данных подсистема манипулирования данными передает ядру. Ядро готовит данные для передачи их функциям (процедурам), реализующим математические методы. При этом оно формирует необходимые структуры данных в памяти в том виде, в каком требуется для библиотеки методов и моделей. Ядро принимает результаты выполнения математических процедур от библиотеки методов и моделей и передает их для визуализации или формирует строки команд для вставки записей в таблицы базы данных. Ядро считывает файлы конфигурации и формирует необходимые глобальные структуры данных.