

UP_Vved_v_ekonometriku_-_N_Novgorod_2010
.pdfПроверить, имеется ли тенденция в изменении выпуска продукции. Выбрать тип модели кривой роста и рассчитать ее параметры.
Проверить качество построенной модели на основе исследования ряда остатков. Выбрать и построить модель тренда и сделать прогноз на один шаг вперед.
Таблица 9
годы |
2000 |
2001 |
2002 |
2003 |
2004 |
2005 |
2006 |
2007 |
2008 |
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
Y |
10 |
12 |
15 |
16 |
20 |
22 |
25 |
24 |
27 |
U |
|
1 |
1 |
1 |
1 |
1 |
1 |
0 |
1 |
V |
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Введем начало отсчета временного ряда с 2000 года и поставим ему в соответствие переменную t=1, остальные года пронумеруем по порядку.
1. Для выявления тенденции используем метод Фостера – Стьюарта.
Определим величины Ut и Vt (см. табл.9). Величина Ut =1,если
соответствующий уровень временного ряда больше всех предшествующих уровней. Vt =1, если соответствующий уровень временного ряда меньше всех
предшествующих уровней.
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
n |
|
|
Рассчитаем величины: K и |
L . |
K |
(Ut Vt ) =7; |
L (Ut Vt ) =7 |
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
t 1 |
|
|
|
|
|
|
|
|
t 1 |
|
||
Рассчитаем t– статистики: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
tK |
|
K K |
|
= |
|
7 3,7 |
|
2,66 ; |
|
tL |
|
L |
|
|
= |
|
|
7 |
|
|
3,63 |
. Значения |
, k , L |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
K |
|
1,24 |
|
|
L |
|
1,93 |
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
k |
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
выбрали из таблицы табулированных значений для n=9.(таблица 3).
Найдем теоретическое значение статистики Стьюдента по таблице t -
распределения |
для |
=0,05 |
и числа |
степеней свободы |
n m 1 7 |
(двусторонний |
тест): |
t =2,365. |
Так как |
обе статистики tk |
и tL больше |
табличного значения t , то с вероятностью 95% можем утверждать, что временной ряд имеет тенденцию как в среднем (т.е. имеется тренд), так и в дисперсии.
2. Построение модели.
По расположению точек на диаграмме рассеяния (рис.6) можно предположить, что кривую роста можно представить в виде линейной функции
(прямая линия). Тогда уравнение модели запишем: ˆ . t
b
a
Y
61

объем выпуска (млн. руб)
30
25
20
15
10
5
0
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
время
Рис. 6. Диаграмма рассеяния уровней временного ряда Найдем параметры этого уравнения по методу наименьших квадратов,
для чего составим систему нормальных уравнений
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
b Y |
|
|
a 5 b 19 |
|||||
|
a t |
|
||||||||||
t |
|
|
|
|
5 a 31,67 b 109, 44 |
|||||||
a t2 b tY |
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
Промежуточные расчеты отразим в таблице 10.
Таблица 10
Таблица для расчета параметров и характеристик модели.
|
|
|
|
|
t2 |
|
|
|
|
e |
(et et 1) |
2 |
2 |
|
|
|
|
|
|
|
|
|
|
|
ei |
|
100 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
t |
Y |
|
t*y |
ˆ |
et |
p |
|
(Y Y )2 |
(Y Y )2 |
( |
t t |
)2 |
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
Y |
|
t 1 |
|
|
et |
|
|
|
|
|
|
|
|
|
Yi |
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
1 |
10 |
|
1 |
10 |
10,33 |
-0,33 |
|
-0,50 |
0,03 |
|
0,11 |
81,00 |
75,11 |
|
16 |
|
|
|
3,33 |
||||||||
|
2 |
12 |
|
4 |
24 |
12,50 |
-0,50 |
1 |
0,33 |
0,69 |
|
0,25 |
49,00 |
42,25 |
|
9 |
|
|
|
4,17 |
||||||||
|
3 |
15 |
|
9 |
45 |
14,67 |
0,33 |
1 |
-0,83 |
1,35 |
|
0,11 |
16,00 |
18,78 |
|
4 |
|
|
|
2,22 |
||||||||
|
4 |
16 |
|
16 |
64 |
16,83 |
-0,83 |
1 |
1,00 |
3,36 |
|
0,69 |
9,00 |
4,69 |
|
1 |
|
|
|
5,21 |
||||||||
|
5 |
20 |
|
25 |
100 |
19,00 |
1,00 |
1 |
0,83 |
0,03 |
|
1,00 |
1,00 |
0,00 |
|
0 |
|
|
|
5,00 |
||||||||
|
6 |
22 |
|
36 |
132 |
21,17 |
0,83 |
1 |
1,67 |
0,70 |
|
0,69 |
9,00 |
4,69 |
|
1 |
|
|
|
3,79 |
||||||||
|
7 |
25 |
|
49 |
175 |
23,33 |
1,67 |
1 |
-1,50 |
10,03 |
|
2,78 |
36,00 |
18,78 |
|
4 |
|
|
|
6,67 |
||||||||
|
8 |
24 |
|
64 |
192 |
25,50 |
-1,50 |
1 |
-0,67 |
0,69 |
|
2,25 |
25,00 |
42,25 |
|
9 |
|
|
|
6,25 |
||||||||
|
9 |
27 |
|
81 |
243 |
27,67 |
-0,67 |
|
|
|
|
0,44 |
64,00 |
75,11 |
|
16 |
|
|
|
2,47 |
||||||||
|
45 |
171 |
285 |
985 |
171 |
0,00 |
7 |
|
16,88 |
|
8,33 |
290 |
281,67 |
|
60 |
|
|
|
39,10 |
|||||||||
Ср. |
5 |
19 |
|
31,67 |
109,44 |
19 |
0,00 |
|
|
|
|
RSS |
TSS |
ESS |
|
|
|
|
|
4,34 |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
tY |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
b |
|
t |
Y |
|
109, 44 5 19 |
2,17 : |
|
|
|
|
|
||||||
|
a Y |
b |
t |
19 2,17 5 8,17 |
|||||||||||||
|
|
|
|
|
|
|
|
31, 67 25 |
|||||||||
t2 ( |
|
|
)2 |
||||||||||||||
|
t |
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
ˆ |
8,17 2,17 t |
|||||
Уравнение кривой роста:Y |
|||||||||||||||||
3. Проверка качества модели.
Проверку качества трендовой модели можно провести также как для модели парной регрессии, проверяя статистическую значимость параметров и общее качество с помощью коэффициента детерминации R2 .
a). Рассчитаем R2 ESS 281, 67 0, 97 .
TSS 290
Проверим его статистическую значимость на основе F–критерия Фишера.
62

|
S 2 |
|
ESS (n m 1) |
|
281,67 |
7 |
|
|
|
F |
r |
|
|
= |
|
|
236,69 |
, что больше табличного значения |
|
Se2 |
RSS m |
8,33 |
1 |
||||||
|
|
|
|
|
F( 0,05;k1 1,k2 7) 5,59.
Следовательно, уравнение кривой роста в целом статистически значимо. b). Проверим статистическую значимость параметра b .
|
|
|
|
|
|
b |
|
|
|
8,17 |
|
|
|
|
|
|
se2 |
8,33 |
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
Статистика t |
|
|
|
|
|
|
|
|
|
15,38 , где |
S 2 |
|
|
|
|
7 |
0,02 . |
|||||||
b |
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
n |
|
|
|
||||||||||||
|
|
|
Sb |
0,02 |
|
|
|
b |
|
|
|
)2 |
60 |
|
||||||||||
|
|
|
|
|
|
|
|
|
(ti t |
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
t 1 |
|
|
|
|
|
|
|
Статистика |
tb |
|
больше табличного значения |
статистики |
Стьюдента |
|||||||||||||||||||
t(7;0,05) =2,365 |
Следовательно, |
параметр |
b |
статистически |
значимо с |
|||||||||||||||||||
вероятностью 95% отличается от нуля, что подтверждает наличие зависимости показателя Y от времени.
c). Точность модели.
Для оценки точности модели рассчитаем среднюю относительную ошибку аппроксимации:
1n ei 100% =4,34 % < 10% , что свидетельствует о достаточной
i Yi
точности построенной модели (табл.10)
4. Проведем оценку качества модели кривой роста на основе исследования ряда остатков
|
|
|
ˆ |
|
|
|
|
|
|
Ряд |
остатков составляют |
величины |
i 1.n , |
(столбец et |
в |
||||
ei Yi Yi |
|||||||||
табл.10). |
Для того, чтобы |
считать построенную |
модель |
адекватной |
и |
||||
надежной проверим выполнение требований случайности и независимости элементов ряда остатков.
a). Проверку случайности ряда остатков проведем на основе критерия поворотных точек.
Внашем примере имеем 7 поворотных точек: p=7 (табл. 10). Рассчитаем теоретическое значение поворотных точек для 0,05
P 2(n 2) / 3 2 |
|
2(9 2) / 3 2 |
|
2 . |
(16 n 29) / 90 |
(16 9 29) / 90 |
|||
1 |
|
|
|
|
Так как P>P1, ряд остатков является случайным с вероятностью 95%
b). Проверку независимости элементов ряда остатков осуществим на основе критерия Дарбина –Уотсона.
|
|
|
n |
2 |
n |
|
|
|
|
||
Вычисляем статистику d : d = et et 1 |
|
/ et 2 16,88/8,33=2,026. |
|||
|
|
t 2 |
|
t 1 |
|
Рассчитаем d * 4 d =1,974. Критические значения статистики d при 5% |
|||||
уровне значимости: d =0,824 и |
d |
2 |
=1,32. Расчетное значение статистики d * |
||
1 |
|
|
|
|
|
63

попадает в интервал: d2 d * 2 , что свидетельствует об отсутствии автокорреляции в ряду остатков
c). Проверим соответствие ряда остатков нормальному закону распределения на основе RS–критерия.
При соответствии ряда остатков нормальному закону распределения для
величины |
RS (Emax Emin ) / S должно выполняться, условие: |
RS , |
где и |
нижнее и верхнее значения критических уровней, рассчитанных |
|
в зависимости от доверительной вероятности и количества уровней ряда остатков (таблица 16).
Рассчитаем статистику RS: RS (Emax Emin ) / S =(1,67 -(-1,5)/1,02=3,1
|
n |
2 |
|
|
|
|
|
|
ei |
|
|
|
|
|
|
|
|
|
|
8,33 |
|
|
|
где S |
i 1 |
|
|
|
1,02 . |
||
|
|
|
|||||
n 1 |
9 1 |
|
|||||
Значения нижней и верхней границ интервала для статистики RS , при доверительной вероятности 0.95:: 2,59; 3,399
Следовательно, элементы ряда остатков подчиняются нормальному закону распределения, и мы можем, с помощью построенной трендовой модели, дать не только точечный, но и доверительный интервальный для Y(t).
Вывод: исследование ряда остатков свидетельствует об адекватности и надежности построенной модели.
5. .Построим точечный и интервальный прогноз на один шаг вперед
Выберем t 10 и подставим в уравнение тренда:
Y(10)=8,17 +2,17 10=29,8. Получили точечный прогноз (точечную оценку). Так как элементы ряда остатков подчиняются нормальному закону распределения, можно построить доверительные интервалы для математического ожидания среднего значения зависимой переменной.
Верхняя граница интервального прогноза: Y(t0)+tSyx. Нижняя граница интервального прогноза: Y(t0)–tSYX.
Здесь t – теоретическое значение статистики Стьюдента с выбранной доверительной вероятностью и n-2 степенями свободы: t(7;0,05) 2,365
|
|
1 |
|
(t |
|
|
|
|
)2 |
|
|
1 |
|
(10 5)2 |
|
|
|
|||
|
S 2 ( |
|
0 |
t |
|
|
|
|
|
|
||||||||||
S 2 |
|
|
|
|
|
|
|
|
) 1,19 ( |
|
|
|
) 0,628 |
для t0=10. |
||||||
|
n |
|
|
|
|
|
|
|
|
|
||||||||||
YX |
e |
n |
|
|
|
|
|
|
|
|
|
|
9 |
|
60 |
|
|
|
|
|
|
|
|
(ti t )2 |
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
i 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Тогда ожидаемое значение показателя Y (объема выпуска) при t 10 ( |
||||||||||||||||||||
в 2005 году) лежит в интервале: |
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
||||||||||||||
29,8 2,365 |
|
0,628 M (Y (t 10) 29,8 2,365 |
0,628 ; |
|||||||||||||||||
|
|
|
|
|
|
27,959 M (Y (t 10) 31,708. |
|
|
|
|||||||||||
64
7. Применение ППП “EXCEL” для эконометрического моделирования
Рассмотрим пример, представленный в п.6.2: построить линейную модель зависимости приращения прибыли (Y) в зависимости от инвестиционных
вложений в оборотные средства ( X1) |
и основной |
капитал |
( X 2 ). Имеются |
||||||||||
статистические данные по 7 предприятиям отрасли |
|
|
|
|
|
||||||||
|
Y |
50 |
120 |
290 |
|
|
190 |
200 |
|
300 |
|
320 |
|
|
X1 |
30 |
66 |
78 |
|
|
110 |
130 |
|
190 |
|
250 |
|
|
X2 |
6 |
10 |
20 |
|
|
15 |
16 |
|
18 |
|
20 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
a1X1 a2 X 2 . Найдем ее параметры |
||||||||
Выбираем линейную модель Y a0 |
|||||||||||||
иоценим качество с использованием средств ППП «EXCEL»
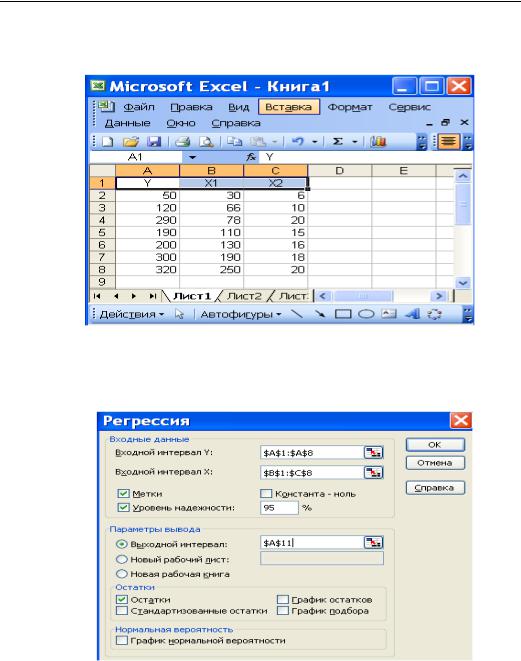
1.Запишем исходные данные в таблицу EXCEL, как это сделано на рис.7.
Рис. 7.Ввод данных на листе 1 таблицы EXCEL.
2. В меню Сервис выбираем строку Анализ данных. На экране появится окно, в котором выбираем пункт Регрессия. Появляется следующее диалоговое окно (рис.8)
Рис.8. Диалоговое окно функции «Регрессия» Пакета анализа
2.Диалоговое окно заполняется следующим образом:
Входной интервал Y – диапазон (столбец), содержащий данные со
65
значениями объясняемой переменной, в нашем примере: ($A$1:$A$8)
Входной интервал X – диапазон (столбцы), содержащий данные со значениями объясняющих переменных: $B$1:$C$8.
Метки – флажок, который указывает, содержат ли первые элементы отмеченных диапазонов названия переменных (столбцов) или нет
Константа-ноль - флажок, указывающий на наличие или отсутствие свободного члена в уравнении модели;
Уровень надежности 1 95% (выбирается однозначно)
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона, в котором будет сохранен отчет по построению модели ($A$11). Можно также вывести отчет на новый рабочий лист или новую книгу, для чего вводится флажок в соответствующее окно
ˆ |
ˆ |
|
Для получения расчетных значений Y , |
остатков e Y Y |
или |
графиков следует установить соответствующие флажки в диалоговом окне. После заполнения диалогового окна нажмите на кнопку Ok.
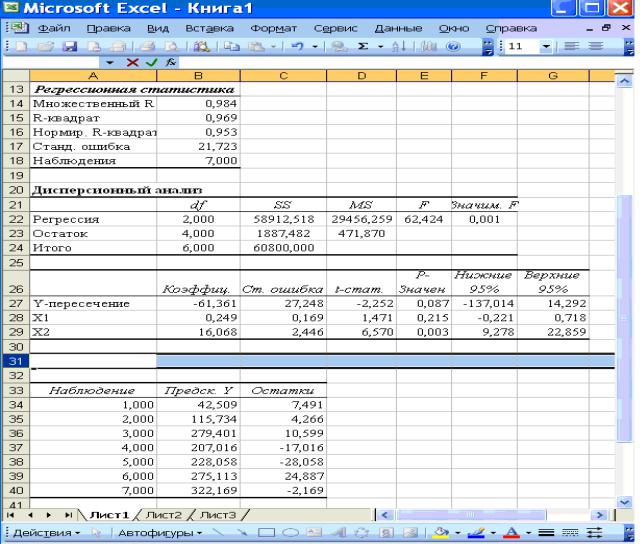
4. Дадим расшифровку результатам моделирования. Вид отчета о результатах регрессионного анализа представлен на рис. 9.
Рис. 9. Отчет о результатах регрессионного анализа
66

Рассмотрим регрессионную статистику. |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
R2 – |
|
|
|
|
|
|
||||||||||||||
Множественный R – это |
|
R2 |
, |
где |
R-квадрат |
(коэффициент |
|||||||||||||||||||||||
детерминации). |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
R2 0,969 |
свидетельствует |
|
о том, что изменения зависимой |
||||||||||||||||||||||||||
переменной Y на 96,9% можно объяснить изменениями включенных в модель |
|||||||||||||||||||||||||||||
объясняющих переменных. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
Нормированный |
R-квадрат |
|
– |
|
скорректированный |
коэффициент |
|||||||||||||||||||||||
детерминации R |
2 =1 |
1 R2 |
n 1 |
, |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
kor |
|
|
|
|
n k 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
где |
n – число наблюдений, k – число объясняющих переменных. |
||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
ei2 |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
|
|
|
|
2 |
|
|
|||
Стандартная ошибка регрессии |
|
S |
2 |
|
, где S |
|
|||||||||||||||||||||||
|
|
|
|
|
|
– |
|||||||||||||||||||||||
|
|
|
|
n k 1 |
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i 1 |
|
|
|
необъясненная дисперсия |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
Наблюдения – число наблюдений n . |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 11. |
|||
|
Коэффици- |
|
Стандарт |
|
t-статис- |
|
|
|
|
P- |
|
Нижние |
Верхние |
||||||||||||||||
|
|
|
|
|
енты |
|
|
|
ошибка |
|
|
|
тика. |
|
Значение |
|
|
95% |
|
95% |
|||||||||
Y-перес.. |
a |
0 |
|
-61,36 |
|
Sa 27,25 |
|
|
ta |
-2,25 |
|
|
|
|
0,09 |
|
|
-137,01 |
14,29 |
||||||||||
|
|
|
|
|
|
0 |
|
|
|
0 |
|
|
|
|
|
|
|
|
|
||||||||||
X1 |
a 0,25 |
|
|
Sa |
0,17 |
|
|
ta |
1,47 |
|
|
|
|
0,22 |
|
|
|
-0,22 |
0,72 |
||||||||||
|
|
|
1 |
|
|
|
1 |
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|||||||||
X2 |
a |
2 |
16,07 |
|
|
Sa |
2,45 |
|
|
ta |
6,57 |
|
|
|
|
0,00 |
|
|
|
9,28 |
22,86 |
||||||||
|
|
|
|
|
|
2 |
|
|
|
2 |
|
|
|
|
|
|
|
|
|
||||||||||
В таблице 11 представлены параметры модели (столбец «коэффициенты) |
|||||||||||||||||||||||||||||
и результаты их |
проверки |
на |
статистическую значимость. Следовательно, |
||||||||||||||||||||||||||
|
|
|
|
|
|
|
61,36 0,25 |
X1 16,07 X 2 |
|
|
|
|
|
|
|||||||||||||||
уравнение модели: Y |
|
|
|
|
|
|
|||||||||||||||||||||||
t –статистика |
|
получена |
делением |
коэффициентов |
|
на |
стандартные |
||||||||||||||||||||||
ошибки. Как нам уже известно, если расчетное значение превосходит критическое, полученное из таблиц теоретического распределения
Стьюдента с параметрами ( , n k 1) , то они статистически значимы.
Можно найти критические значения по таблицам t –распределения и провести сравнение (для данного примера t (0.05, 4)=2,77). В Пакете анализа предусмотрен другой инструмент оценки t –статистики: p-значение.
p-значение-величина, применяемая при статистической проверке гипотез с использованием компьютерных программ статистического анализа данных.. Представляет собой вероятность того, что критическое значение статистики используемого критерия (в данном случае t-статистики Стьюдента) превысит значение, вычисленное по выборке. Решение о принятии или отклонении нулевой гипотезы принимается в результате сравнения p-значения
с выбранным уровнем значимости . Если p, то нулевая гипотеза
отклоняется и принимается альтернативная о статистической значимости рассматриваемого параметра.
67
В данном примере |
параметр |
a1 статистически незначим |
так как |
|
p 0,215 0,05; |
параметр |
a2 |
статистически |
значим |
( p 0,003 0,05). |
|
|
|
|
Нижние 95% - Верхние 95% - доверительные интервалы для параметров модели. Вообще, доверительные интервалы строятся только для статистически
значимых величин. В данном случае для параметра a2 :
9,278 M (a2 ) 2 22,859 , т.е. с надежностью 95% истинное
значение параметра лежит в указанном интервале.
Рассмотрим таблицу дисперсионного анализа.
Дисперсионный анализ |
|
|
|
|
|
|
df |
SS |
MS |
F |
Значим. F |
Регрессия |
2,000 |
58912,518 |
29456,259 |
62,424 |
0,001 |
Остаток |
4,000 |
1887,482 |
471,870 |
|
|
Итого |
6,000 |
60800,000 |
|
|
|
df – degrees of freedom – число степеней свободы связано с числом единиц совокупности n и с числом определяемых по ней констант k 1 .
SS- обозначение полных сумм квадратов. В этом столбце в строке
«Регрессия» стоит факторная сумма отклонений ESS |
n |
ˆ |
|
|
|
2 |
: в строке |
||||
|
|
|
|
||||||||
.= (Yi Y ) |
|
||||||||||
|
|
|
|
|
i 1 |
|
|
|
|
|
|
|
|
|
|
n |
|
ˆ |
2 |
|
|
|
|
«Остаток» – |
остаточная сумма отклонений RSS = |
|
|
, |
а |
в строке |
|||||
(Yi Yi ) |
|
||||||||||
|
|
|
|
i 1 |
|
|
|
|
|
|
|
|
n |
|
)2 . |
|
|
|
|
|
|
|
|
«Итого» –общая сумма отклонений TSS = (Yi |
Y |
|
|
|
|
|
|
|
|
||
|
i 1 |
|
|
|
|
|
|
|
|
||
F и |
Значимость F позволяют проверить |
значимость |
|
уравнения |
|||||||
регрессии, По эмпирическому значению статистики F проверяется гипотеза равенства нулю одновременно всех коэффициентов модели. Уравнение регрессии значимо на уровне , если F Fкр , где Fкр - табличное значение F-
критерия Фишера с параметрами ,k,n k 1 .Если значимость F 0.05, то уравнение регрессии статистически значимо с вероятностью 95%
68
.Литература
1.Айвазян С.А., Мхитарян В.С. Прикладная статистика и основы эконометрики. Учебник для вузов. - М.: ЮНИТИ, 1998. 1008с.
2.Доугерти К. Введение в эконометрику. - М.: ИНФРА-М, 1997. 402с. 3.Замков О.О., Толстопятенко А.В. и др. Математические методы в
экономике. М.:ДИС, 2002. 368с.
4.Кремер Н.Ш., Путко Б.А. Эконометрика. М.: Юнити-дана,2002. 310с.
5.Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. Начальный курс. - М.: Дело, 1997. 247с.
6.Мамаева З.М. Эконометрика:учебно-методическое пособие. Нижний Новгород, изд.УРАО, 2005 , 50с.
7Мхитарян В.С., Архипова М.Ю. и др. Эконометрика-М.: Проспект, 2008, 380 с.
8.Носко В.П. "Эконометрика для начинающих. Москва, ИЭПП, 2000. 302с. http://www.iet.ru/archiv/zip/nosko.zip
9.Федосеев В.В., Гармаш А.Н., Дайитбегов Д.М.и др. Экономикоматематические методы и прикладные модели: Учеб. пособие для вузов / Под ред. В.В.Федосеева. М.: ЮНИТИ, 1999. 391с.
10..Эконометрика Учебное пособие /И.И. Елисеева. С.В. Курышева, Д.М. Гордиенко и др. - М.: Финансы и статистика, 2005. 340с.
69
Приложение. Статистические таблицы |
|
|
|
|
||||
|
|
|
|
|
|
|
Таблица 12 |
|
Распределение |
Стьюдента |
(t–распределение: |
критические |
|||||
значения)[1 ] |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Число |
Тесты |
|
|
Уровень значимости |
|
|
||
|
|
|
|
|||||
степен. |
|
|
|
|
|
|
|
|
свободы |
|
|
|
|
|
|
|
|
двусторонний |
|
|
|
|
|
|
|
|
|
0,2 |
0,1 |
0,05 |
0,02 |
|
0,01 |
0,002 |
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
1 |
|
3,078 |
6,314 |
12,706 |
31,821 |
|
63,657 |
636,619 |
|
|
|
|
|
|
|
|
|
2 |
|
1,886 |
2,920 |
4,303 |
6,965 |
|
9,925 |
31,599 |
|
|
|
|
|
|
|
|
|
3 |
|
1,638 |
2,353 |
3,182 |
4,541 |
|
5,841 |
12,924 |
|
|
|
|
|
|
|
|
|
4 |
|
1,533 |
2,132 |
2,776 |
3,747 |
|
4,604 |
8,610 |
|
|
|
|
|
|
|
|
|
5 |
|
1,476 |
2,015 |
2,571 |
3,365 |
|
4,032 |
6,869 |
|
|
|
|
|
|
|
|
|
6 |
|
1,440 |
1,943 |
2,447 |
3,143 |
|
3,707 |
5,959 |
|
|
|
|
|
|
|
|
|
7 |
|
1,415 |
1,895 |
2,365 |
2,998 |
|
3,499 |
5,408 |
|
|
|
|
|
|
|
|
|
8 |
|
1,397 |
1,860 |
2,306 |
2,896 |
|
3,355 |
5,041 |
|
|
|
|
|
|
|
|
|
9 |
|
1,383 |
1,833 |
2,262 |
2,821 |
|
3,250 |
4,781 |
|
|
|
|
|
|
|
|
|
10 |
|
1,372 |
1,812 |
2,228 |
2,764 |
|
3,169 |
4,587 |
|
|
|
|
|
|
|
|
|
11 |
|
1,363 |
1,796 |
2,201 |
2,718 |
|
3,106 |
4,437 |
|
|
|
|
|
|
|
|
|
12 |
|
1,356 |
1,782 |
2,179 |
2,681 |
|
3,055 |
4,318 |
|
|
|
|
|
|
|
|
|
13 |
|
1,350 |
1,771 |
2,160 |
2,650 |
|
3,012 |
4,221 |
|
|
|
|
|
|
|
|
|
14 |
|
1,345 |
1,761 |
2,145 |
2,624 |
|
2,977 |
4,141 |
|
|
|
|
|
|
|
|
|
15 |
|
1,341 |
1,753 |
2,131 |
2,602 |
|
2,947 |
4,073 |
|
|
|
|
|
|
|
|
|
16 |
|
1,337 |
1,746 |
2,120 |
2,583 |
|
2,921 |
4,015 |
|
|
|
|
|
|
|
|
|
17 |
|
1,333 |
1,740 |
2,110 |
2,567 |
|
2,898 |
3,965 |
|
|
|
|
|
|
|
|
|
18 |
|
1,330 |
1,734 |
2,101 |
2,552 |
|
2,878 |
3,922 |
|
|
|
|
|
|
|
|
|
19 |
|
1,328 |
1,729 |
2,093 |
2,539 |
|
2,861 |
3,883 |
|
|
|
|
|
|
|
|
|
20 |
|
1,325 |
1,725 |
2,086 |
2,528 |
|
2,845 |
3,850 |
|
односторонний |
0,100 |
0,05 |
0,025 |
0,01 |
|
0,005 |
0,001 |
|
|
|
|
|
|
|
|
|
Число степеней свободы равняется числу наблюдений за вычетом числа параметров модели. Например, для модели парной регрессии со свободным членом, число степеней свободы равняется (n-2)
70