

FAQ_Print
.pdfВ настоящее время модель Белла-ЛаПадулы и другие модели мандатного правления доступом широко используются при построении и верификации автоматизированных систем, преимущественно предназначенных для работы
синформацией, составляющей государственную тайну.
6.Модели целостности информации.
Модель Кларка-Вилсона
Модель целостности Кларка-Вилсона была предложена в 1987 г. как результат анализа практики бумажного документооборота, эффективной с точки зрения обеспечения целостности информации. Модель Кларка-Вилсона является описательной и не содержит каких бы то ни было строгих математических конструкций
– скорее её целесообразно рассматривать как совокупность практических рекомендаций по построению системы обеспечения целостности в АС.
Введём следующие обозначения:
-S – множество субъектов;
-D – множество данных в автоматизированной системе (множество объек-
тов);
-CDI (Constrained Data Items) – данные, целостность которых контролируется;
-UDI (Unconstrained Data Items) – данные, целостность которых не
контролируется; I UDI,CDI∩UDI При этом D = CD =Ø.
-TP (Transformation Procedure) – процедура преобразования, т.е. компонент,
котрый может инициировать транзакцию – последовательность операций, переводящую систему из одного состояния в другое;
-IVP (Integrity Verification Procedure) – процедура проверки целостности CDI.
Правила модели Кларка-Вилсона:
1. В системе должны иметься IVP, способные подтвердить целостность любого CDI.
Примером IVP может служить механизм подсчёта контрольных сумм.
2.Применение любой TP к любому CDI должно сохранять целостность этого
CDI.
3.Только TP могут вносить изменения в CDI.
 231
231
4. Субъекты могут инициировать только определённые TP над определёнными CDI.
Данное требование означает, что система должна поддерживать отношения видаs (s,S,t,td),TPгде, d CDI . Если отношение определено, то субъект s может применить преобразование t к объекту d.
5.Должна быть обеспечена политика разделения обязанностей субъектов – т.е. субъекты не должны изменять CDI без вовлечения в операцию других субъектов системы.
6.Специальные TP могут превращать UDI в CDI.
7.Каждое применение TP должно регистрироваться в специальном CDI. При
этом:
-данный CDI должен быть доступен только для добавления информации;
-в данный CDI необходимо записывать информацию, достаточную для восстановления полной картины функционирования системы.
8.Система должна распознавать субъекты, пытающиеся инициировать TP.
9.Система должна разрешать производить изменения в списках авторизации только специальным субъектам (например, администраторам безопасности).
Данное требование означает, что тройки (s, t, d) могут модифицировать только определённые
субъекты.
Безусловными достоинствами модели Кларка-Вилсона являются её простота и лёгкость совместного использования с другими моделями безопасности.
Модель Биба
Модель Биба была разработана в 1977 году как модификация модели Бел-
ла-ЛаПадулы, ориентированная на обеспечение целостности данных. Аналогично моделиΛ=(IC,≤,•,Белла-ЛаПадулы,) модель Биба использует решётку классов целостности , где IC – классы целостности данных.
Базовые правила Модели Биба формулируются следующим образом:
1.Простое правило целостности (Simple Integrity, SI).Субъект с уровнем целостности xs может читать информацию из объекта с уровнем целостности xo тогда и только тогда, когда xo преобладает над xs.
2.* - свойство (* - integrity).Субъект с уровнем целостности xs может писать
информацию в объект с уровнем целостности xo тогда и только тогда, когда xs преобладает над xo.
 232
232
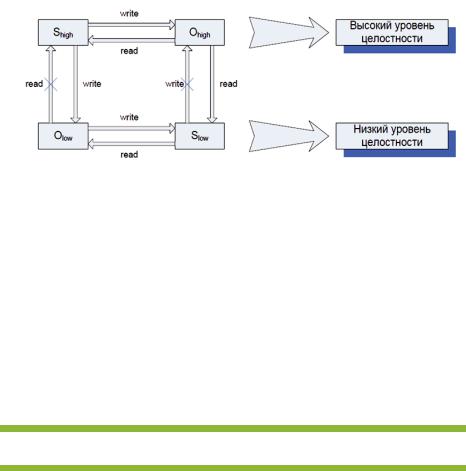
Для первого правила существует мнемоническое обозначение No Read Down, а для второго – No Write Up.
Рис.1 Диаграмма информационных потоков, соответствующая реализации модели Биба в системе с двумя уровнями секретности
Отдельного комментария заслуживает вопрос, что именно понимается в модели Биба под уровнями целостности. Действительно, в большинстве приложений целостность данных рассматривается как некое свойство, которое либо сохраняется, либо не сохраняется – и введение иерархических уровней целостности может представляться излишним. В действительности уровни целостности в модели Биба стоит рассматривать как уровни достоверности, а соответствующие информационные потоки – как передачу информации из более достоверной совокупности данных в менее достоверную и наоборот.
Формальное описание модели Биба полностью аналогично описанию модели Белла-ЛаПадулы. К достоинствам модели Биба следует отнести её простоту, а также использование хорошо изученного математического аппарата. В то же время модель сохраняет все недостатки, присущие модели Белла-ЛаПадулы.
7. Задача распознавания образов. Признаки и классификаторы.
Общие сведения из теории распознавания образов
Распознавание образов (обучение с учителем) – это научная дисциплина, целью которой является классификация объектов по нескольким категориям или классам. Объекты называются образами.
Процесс распознавания заключается в извлечении информации из известных примеров, которая используется для последующей классификации новых данных. Для этого необходим набор объектов с заранее известными классами – так называемая обучающая выборка. В процессе обучения классификатора строится разделяющая поверхность (граница) между объектами указанных классов из обучающей выборки.
 233
233
Для проверки пригодности использования построенного классификатора необходимо оценить точность предсказания. Для этого необходимо иметь в распоряжении так называемую тестовую выборку – дополнительную коллекцию образцов программ с заранее известным назначением, но не входивших обучающую
выборку. Диагностика образцов вредоносных программ (объектов) из тестовой выборки происходит путем последовательного применения найденного решающего правила. По количеству ошибок на тестовой выборке можно судить о применимости созданного классификатора (обнаружителя) вирусных программ.
Необходимо подчеркнуть основное правило для оценки точности классификатора – “никогда не тестироваться на объектах из обучающей выборки”.
В качестве примеров наиболее популярных алгоритмов обучения с учителем можно назвать нейронные сети, метод опорных векторов, метод k-ближайших соседей, деревья решений, байесовский классификатор.
Обобщение – это способность классификатора правильно предсказывать классы тех объектов, которых он раньше никогда не “видел”, то есть объектов, не входивших в обучающую выборку.
Переобучение – классификатор безошибочен на обучающей выборке, но плохо работает на тестовой (слабая обобщающая способность)
Особенности проведения процедуры обучения
Стандартная схема применения методов обучения с учителем состоит в разделении всех имеющихся данных на две части – обучающую и тестовую выборки. В процессе обучения классификатора формируется решающее правило, позволяющее правильно предсказывать класс объектов из обучающей выборки. После завершения подстройки классификатора под обучающую выборку, сформированное правило применяется к тестовой выборке. Результат предсказания сравнивается с истинными классами объектов тестовой выборки, что позволяет оценить точность построенного классификатора.
В случае сложных алгоритмов распознавания образов (например, нейронных сетей) необходимо подстроить значения множества параметров. Это означает, что при обучении с учителем желательно иметь как можно больше объектов в обучающей выборке, иначе алгоритму классификации может не хватить информации для построения решающего правила с приемлемой точностью работы.
Для решения этой проблемы часто применяют процедуру кросс-валидации. С этой целью все имеющиеся данные разделяют на k частей (блоков), см. рисунок 1. Обычно k задают равным 5 или 10 и говорят о 5-кратной или 10-кратной кросс-валидации. В предельном случае задают k равным количеству объектов, тогда говорят о кросс-валидации с исключением по одному. На каждом шаге процедуры кросс-валидации k–1 блоков данных объединяют в обучающую подвыборку, а оставшийся блок соответствует тестовой подвыборке. Затем обучают
классификатор на обучающей подвыборке и определяют долю ошибок на тесто-
 234
234

вой подвыборке. Далее вся последовательность повторяется, но в качестве обучающей и тестовой подвыборок используют уже другие блоки данных.
Рис. 1. Процедура кросс-валидации для оценки точности работы классификатора. Цветом показаны обучающая и тестовая подвыборки.
Необходимо подчеркнуть, что кросс-валидацию необходимо использовать только в том случае, если количество данных слишком мало для формирования достаточно больших обучающих и тестовых выборок.
Сравнение классификаторов
Рассмотрим двуклассовую задачу автоматического постановки распознавания спам-письма. При этом возможны два типа ошибок. Если письмо на самом деле деловое, а классификатор предсказывает получение спама, то такая ошибка называется ложно-положительной или ошибкой первого рода. Если же получен спам, а в результате применения классификатора он отнесен к классу “деловое”, то в этом случае совершается ложно-отрицательная ошибка или так называемая ошибка второго рода.
Рис. 2. Возможные варианты соответствия результатов классификации и золотого стандарта.
Для формальной оценки точности классификатора необходимо разделить число правильных ответов (т.е. когда результат классификации совпал со значением золотого стандарта) на общее число предсказаний:
 235
235

Чувствительность представляет собой ошибку классификатора на объектах,
которые согласно золотому стандарту принадлежат к классу “+”:
Специфичность – ошибка классификатора на объектах класса “–”:
Уменьшение количества признаков
Если количество признаков сопоставимо или превышает количество объектов (так называемое проклятие размерности, curse of dimensionality), то это сильно затрудняет работу алгоритмов классификации, способствуя переобучению.
стандартной практикой перед применением собственно методов распознавания образов, является уменьшение размерности пространства признаков (dimensionality reduction), то есть отбрасывание части переменных.
Методы отбора переменных (feature selection) можно разделить на два типа, относительно того используется ли при этом сам классификатор или нет. В первом случае “качество” отобранных переменных определяется точностью классификации, которая при этом достигается.
Вторая группа методов никак не опирается на методы классификации. Суще-
ствующие переменные отбираются либо с помощью классических статистических тестов (критерии Стьюдента, Фишера), либо формируются новые переменные как линейные комбинации исходных признаков (метод главных компонент). Еще одним подходом является исключение сильно зависимых друг от друга переменных с помощью кластерного анализа. Из каждого кластера оставляется только одна переменная.
8. Алгоритмы кластеризации данных.
Кластеризация (или кластерный анализ) — это задача разбиения множества
объектов на группы, называемые кластерами. Внутри каждой группы должны оказаться «похожие» объекты, а объекты разных группы должны быть как можно более отличны. Главное отличие кластеризации от классификации состоит в том, что перечень групп четко не задан и определяется в процессе работы алгоритма.
Кластеризация – объединение в группы схожих объектов – является одной из
фундаментальных задач в области анализа данных. Список прикладных областей, где она применяется, широк: сегментация изображений, маркетинг, борьба с мо-
шенничеством, прогнозирование, анализ текстов и многие другие.
 236
236
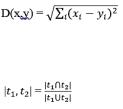
В ИБ присутствует в антивирусных программах, в системах обнаружения вторжений, при автоматизации аудита и т.д.
Кластеризация часто используется как первый шаг при анализе данных. Это связано с тем, что аналитику часто удобнее и проще выделить группы схожих объектов, изучить их особенности, и затем построить для каждой группы собственную модель, чем создавать одну общую модель для всех данных. После выявления схожих групп применяются другие методы анализа данных.
Очень часто данные, с которыми сталкивается аналитик, имеют следующие важные особенности:
•высокая размерность (объем может характеризоваться 1000 признаками);
•большой объем (сотни тысяч и миллионы записей) таблиц баз данных и хранилищ данных (сверхбольшие базы данных);
•наборы данных содержат большое количество числовых и категорийных атрибутов.
Большинство алгоритмов кластеризации предполагают сравнение объектов между собой на основе некоторой меры близости (сходства).
Мерой близости называется величина, имеющая предел и возрастающая с увеличением близости объектов.
В качестве меры близости для числовых атрибутов очень часто используется евклидово расстояние, вычисляемое по формуле:
Для категорийных атрибутов распространена мера сходства Чекановско- го-Серенсена и Жаккара
По способу разбиения на кластеры алгоритмы бывают двух типов: иерархические и неиерархические. Классические иерархические алгоритмы работают только с категорийными атрибутами, когда строится полное дерево вложенных кластеров. Здесь распространены агломеративные методы построения иерархий кластеров – в них производится последовательное объединение исходных объектов и соответствующее уменьшение числа кластеров. Иерархические алгоритмы обеспечивают сравнительно высокое качество кластеризации и не требуют предварительного задания количества кластеров. Большинство из них имеют сложность O(n2).
Неиерархические алгоритмы основаны на оптимизации некоторой целевой функции, определяющей оптимальное в определенном смысле разбиение мно-
 237
237
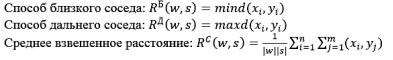
жества объектов на кластеры. В этой группе популярны алгоритмы семейства k-средних (k-means, fuzzy c-means, Густафсон-Кесселя), которые в качестве целевой функции используют сумму квадратов взвешенных отклонений координат объектов от центров искомых кластеров. Кластеры ищутся сферической либо эл-
липсоидной формы.
Иерархическая кластеризация
Результат работы иерархического алгоритма обычно представляется в виде дендрограммы.
При выполнении ИК каждый объект анализируемой выборки считается отдельным кластером, затем происходит последовательное слияние кластеров и заканчивается алгоритм тем, что все объекты образуют один кластер. После того как каждый объект представлен отдельным кластером, определяется функция расстояния между ними.
Затем запускается процесс слияния – это процесс итерационный. На каждом шаге итерации вместо пары самих близких кластеров образуется новый кластер. Расстояние от нового кластера до любого другого кластера может вычисляться различными способами:
w – первый кластер {x1, x2,…,xn} |
s – второй кластер {y1,y2,…,ym} |
Выбор меры расстояния между кластерами зависит от вида пространства анализируемого группирования данных.
Так, алгоритмы, основанные на расстоянии ближайшего соседа, хорошо работают в случае группировок, имеющих сложную, в частности, цепочечную структуру. Расстояние дальнего соседа применяется, когда искомые группировки образуют в пространстве признаков шаровидные облака. И промежуточное место занимают алгоритмы, использующие расстояния центров тяжести и средней связи, которые лучше всего работают в случае группировок эллипсоидной формы.
На рисунке ниже видно, что первоначально были объединены в кластер объ-
екты N6 и N7 поскольку расстояние между ними минимальное. На следующей итерации объединены объекты N2 и N3. Далее N4 и N5. На вертикальной оси правого рисунка откладываем вычисленные расстояния между объектами до тех пор пока не произошло слияние всех кластеров в один. На предпоследнем шаге данные разбиты в два кластера: в первом – N1; во втором – N1 N2 N3 N4 N5 N6
N7.
После построения дендрограммы исследователю необходимо произвести от-
 238
238
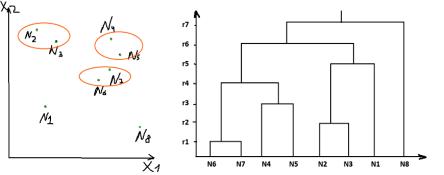
сечение ветвей дерева таким образом, чтобы получить необходимое/ искомое количество кластеров.
Алгоритм к-средних
Называется быстрым кластерным анализом. Полное описание алгоритма опубликовано в 1978 году, основной особенность от иерархического алгоритма является необходимость определить число искомых кластеров. Число к.
Алгоритм строит к кластеров, расположенных на возможно больших расстояниях друг от друга. Выбор числа к может базироваться на результате исследований теории , соображений или интуиции.
При использовании метода, кластеры представлены в виде центроидов, являющихся центром масс всех объектов в кластере.
На вход алгоритма попадает множество S и число k. S - множество всех объектов, на выходе получается разделение множества S на k подмножеств.
Смысл алгоритма в том, чтобы минимизировать сумму квадратов расстояний между элементами, входящих в кластер.
В общем виде алгоритм включает следующие итерации:
1)Случайным образом выбираем в пространстве объектов k центроидов.
2)Начинаем итерационный процесс вычисления кластеров в цикле.
2.1) Каждый объект «прикрепляется» к тому центроиду, к которому он ближе.
2.2) Когда все объекты привязаны, происходит пересчет координат центроидов, т.е. выбирается центр из объектов привязанных к соответствующим кластерам.
2.3.) Расчет повторяется с 2.1, пока А) Центроиды не перестанут менять своего положения или
Б) Объекты остаются в своих кластерах.
 239
239
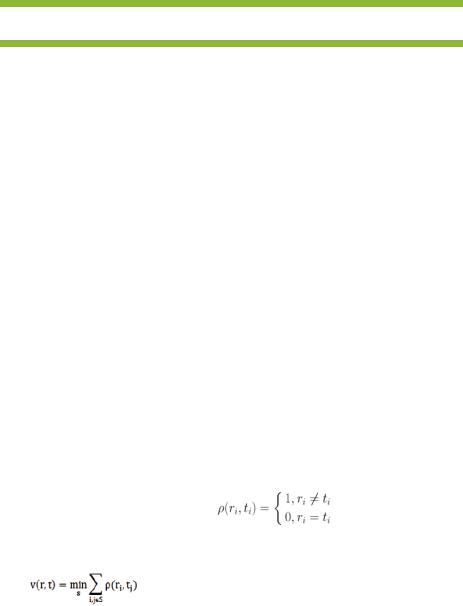
9. Классификация на основе сравнения с эталоном.
Пусть задано множество образов (эталонов). Задача состоит в том, чтобы для тестируемого объекта выяснить, какой эталон ближе на основе меры сходства (расстояния между объектами). Данная задача и получила название "сравнение с эталонами".
В качестве эталонов могут рассматриваться следующие объекты:
1. Буквы в словах рукописного текста (применительно к распознаванию рукописного текста);
2. Силуэты объектов в сцене (применительно к машинному зрению);
3. Слова (команды), произносимые человеком (применительно к распознаванию речи).
В этих примерах признаки не выделены, но можно измерить сходство. Например, сравнение слов: кошка ~ мошка ~ кора ~ норка и. т.д. Или силуэт объекта в сцене, чье положение и ориентация заранее не известны (применительно к машинному зрению, робототехнике).
Рассмотрим строчный образ (слово). В данном случае можно выделить два критерия, на основе которых можно строить меру близости:
•совпадение букв,
•монотонность (совпадение порядка букв)
Пусть r1,r2…ri– эталон, t1,t2…tj– пробный образ, причем i≠j. Построим соответствие между эталоном и пробным образом по следующему правилу: каждому символу в первом слове должен соответствовать хотя бы один символ во втором слове и каждому символу во втором слове должен соответствовать хотя бы один символ в первом слове.
Введем меру следующим образом:
В качестве меры сходства двух слов принимаем соответствие, при котором суммарный вес всех дуг минимален:
Расстояние Левенштейна
Расстояние Левенштейна - это минимальное количество правок одной строки (под правками подразумеваются три возможные операции: стирание символа, замена символа и вставка символа), чтобы превратить ее во вторую.
 240
240