

Organizatsionno-upravlencheskie_reshenia / Управленческие решения_Балдин К.В, Воробьев С.Н, Уткин В.Б_Учебник_2006 -496с
.PDFб)
Рис. 5.4.19. Внешняя интеллектуализация: а) универсальная; б) специализированная
Различают внутреннюю локализованную интеллектуа лизацию, когда в разрабатываемой АИС наряду с традицион ными можно выделить так называемые типовые интеллек туальные блоки (см. рис. 5.4.20), и внутреннюю распределен ную интеллектуализацию, предусматривающую применение интеллектуальных вычислительных и логических процедур практически во всех блоках.
Понятно, что реализация способа внутренней интеллек туализации дорогостояща, она требует от разработчиков ис ключительно высокой квалификации в различных предмет ных областях и длительного времени создания системы.
Важно отметить, что современные интеллектуальные системы выполняют не только основные (целевые) функции, но и все большее число дополнительных, ранее либо вооб ще не предусматриваемых, либо выполняемых другими сис темами. Так, например, практически все интеллектуальные
440
АИС содержат подсистемы обучения работы с ними, интел лектуальной поддержки работы пользователя по основному назначению системы, интеллектуальной многоуровневой по мощи, модификации базы знаний и т. п.
В заключение следует еще раз отметить, что на совре менном этапе развития общества магистральным путем авто матизации профессиональной (в том числе управленческой) деятельности является ее интеллектуализация, проводимая одним из рассмотренных способов. Следует ожидать, что в будущем каждая АИС станет в полном смысле средством интеллектуальной поддержки деятельности конкретного дол жностного лица, и без применения таких средств предста вить технологию разработки решений в любой сфере челове ческой деятельности будет невозможно.
Рис. 5.4.20. Внутренняя локализованная интеллектуализация
441
5.5. Анализ зарубежного опыта применения современных информационных технологий при создании систем поддержки принятия решений
5.5.1. Этапы развития современных информационных технологий
Системы поддержки принятия решений ориентированы на руководство и поставляют важную для управления ин формацию. Системы интенсивно используют информацион ные технологии и обеспечивают быструю и эффективную об ратную связь в процессах управления.
Как таковые СППР начали создаваться в 60-х гг. XX в. и работали на суперкомпьютерах тех лет (mainframe). Каждая такая система была исключительна, требовала больших тру довых и стоимостных затрат, но в конечном счете работала в многопользовательском режиме и была многофункциональной.
С появлением персональных компьютеров для консоли дации данных начали повсеместно использоваться широко форматные таблицы. Они обрабатывают табличные данные (например, проводят вычисления по формулам или вычисля ют итоговые), но являются прежде всего персональным ин струментом и не предназначены для коллективной работы, совершения сложных вычислений, обработки больших мас сивов данных, проведения аналитических исследований.
Наконец, появились информационные системы руковод ства (Executive Information Systems). Они выполняют опре деленный набор функций: представляют агрегированные дан ные в различных формах (таблицы, графики, карты), полу чают разнообразную отчетность, позволяют просматривать результаты в режиме реального времени. Системы работают по технологии клиент-сервер и могут быть очень быстро ре ализованы практически без написания кода. Системы ограни чены в функциональности и не решают более трудные зада442
чи, связанные, например, с составлением сложных запросов или обнаружением новых зависимостей в данных [68].
Современным триумфом в области поддержки принятия решений являются системы делового интеллекта (Business Intelligence Systems). Появление систем такого рода связано с последними достижениями научно-технической мысли, когда стало возможным быстро создавать промышленные анали тические системы корпоративного масштаба с расчетом на неограниченное наращивание ресурсов и функциональности. Системы завоевывают мир, и в начале третьего тысячелетия до 30% всех применяемых автоматизированных систем бу дут СППР.
Информационная структура крупной организации, как правило, разнородна и включает в себя богатый набор обору дования и сетей, операционных систем и протоколов взаимо действия, распределенных прикладных систем и локальных задач, старых и новых технологий.
Новый корпоративный ресурс — "данные". Прикладные системы создаются соответственно требованиям той или иной области человеческой деятельности. Они должны работать с понятиями конкретной предметной области, иметь специаль ные для предметной области свойства и функциональность, поддерживать конкретные деловые процессы и помогать ре шать конкретные деловые задачи. Каждая подобная система "настроена" для работы только в определенной прикладной области и часто только для решения какой-либо частной де ловой задачи в этой области (например, бухучет для страхо вой компании).
В процессе эксплуатации прикладная система накапли вает данные о деловой области, для которой она была спро ектирована. Эти данные вводятся в систему конечными пользо вателями и, в зависимости от применяемой технологии, хра нятся в том или ином электронном формате (файлах реляци онных или нереляционных баз данных или в таблицах, тек стовых файлах и др.). С течением времени объем данных рас тет, формируются временные ряды данных. Так возникает
443
новый ресурс — "данные", появление которого целиком обя зано внедрению информационных технологий. Это ресурс корпоративного уровня. Он особенно ценен тем, что отража ет текущее состояние работ многих направлений, находится в стадии постоянного накопления, непосредственно годен для дальнейшей обработки и, в принципе, бесконечно тиражи руем и возобновляем. Чем разнообразнее данные, создавае мые в организации, тем более полную картину ее деятель ности представляют, тем на большее число вопросов они по тенциально могут ответить.
Новый ресурс открывает новые возможности использо вания старых инвестиций. Теперь ценность прикладной сис темы уже не ограничена тем, что она позволяет убыстрить ввод и передачу информации, оптимизировать деловые про цессы, поддержать новую технологию работы. Система спо собна предложить людям некоторую дополнительную возмож ность, которая могла изначально не планироваться, а предо ставлять на основе накопленных данных информацию о со стоянии дел в предметной области и качестве работы персо нала. Другими словами, в то время как персонал оперативно вводит данные, они могут быть использованы в том же опе ративном режиме для поддержки принятия решений, в час тности для предоставления отчетности и проведения анали тических исследований.
Особенности информационной среды на корпоративном уровне. В крупной организации разные виды деятельности имеют разную информационную поддержку. Персонал орга низации может одновременно работать с разными приклад ными системами и настольными программами, а отдельные структурные подразделения могут иметь несколько приклад ных систем или быть охваченными одной системой или вооб ще не иметь масштабной автоматизации своей работы.
Данные в разных подразделениях могут дублировать друг друга, храниться в разных форматах, данные могут допол нять друг друга в какой-то прикладной области и при этом одновременно быть недоступными специалистам и т. п. В ре-
444
зультате корпорация (например, при составлении отчетов, получении ответов на сложные запросы и др.) постоянно стал кивается с невозможностью в полной мере использования этого ресурса.
В результате обычной картиной является следующее:
•корпоративные данные рассредоточены по разным местам ("острова информации");
•данные об одном и том же предметном объекте (на пример, об организациях или о персональных данных) могут иметь разное представление в разных структур ных подразделениях и не соответствовать друг другу;
•генерация отчетов производится в разных местах, для каждой прикладной системы независимо от другой, строго по предопределенным шаблонам;
•затруднено быстрое получение информации по нестан дартному запросу, особенно при работе нескольких под разделений;
•получение интегральной и аналитической отчетности о деятельности всей организации представляет собой не тривиальную задачу;
•трудноосуществим процесс сбора информации о дея тельности организации в режиме реального времени.
Как следствие, критичная для дела информация, пока еще скрытая в распределенных по организации данных, не достигает управленческого штата, и последний сталкивается с серьезными проблемами по своевременной консолидации всего многообразия отчетов из всех подразделений.
Прикладные системы нового класса. Объективное раз витие ситуации приводит к тому, что высший управленчес кий состав становится заинтересованным в переработке мас сы разнообразных данных в информацию, корректно осве щающую состояние дел в организации с разных точек зре ния, и в ее оперативном получении "в нужном месте в нуж ное время" [69].
Инструментом достижения этих целей являются высоко специализированные автоматизированные системы, спроек-
445

тированные исключительно для работы с данными и для по лучения из них информации для поддержки принятия реше ний. Системы имеют прикладной характер, но отличаются от транзакционных прикладных тем, что предназначены для работы в среде уже накопленных данных и в этом смысле они "вторичны".
Автоматизированные системы, специально созданные для получения реальных выгод от накопленных другими сис темами данных и умеющие перерабатывать их в ценную для руководства информацию, получили название систем поддер жки принятия решений (Decision Support Systems — DSS).
На рис. 5.5.1 представлена технология функционирования та ких систем.
На вход системы с определенной периодичностью "зака чивают" новые данные организации. Система отбирает их представительную часть, создает производные данные, со храняет в собственной базе (технология Data Warehouse) и, проводя то или иное агрегирование, производит значимую информацию (технология корпоративной отчетности, тех нология "гиперкубов" OLAP). Последняя в виде отчетов, гра фиков, навигации по многомерным базам данных поставля ется лицам, участвующим в процессах принятия решений.
Над содержанием базы может совершаться иной тип об работки — обнаружение новой информации (технология Data Mining). Это имеет смысл при наличии большого объема дан ных (и/или очень разнородных данных) и удовлетворяет нуж дам специальной категории пользователей — аналитикам-ис следователям. В этом случае система способна в накопленных данных находить новые знания о деятельности организации, о внешнем по отношению к ней мире, о конкурентах и о всем остальном, что отражают данные базы. При этом ис пользуется специальный инструментарий, высокоинтеллек туальный и требующий очень искусной настройки. Получае мые здесь результаты также являются ценной информацией для лиц, ответственных за стратегические решения.
446
Рис. 5.5.1. Технологии в системах поддержки принятия решений
Обработка данных, конечно, может быть произвольной, в зависимости от задач, решаемых системой. Например, в ситуационных центрах велика доля компьютерного модели рования определенных явлений (физических, социально-эко номических и др.), работы с геоинформационными представ лениями и т. д.
Итак, системы поддержки принятия решений использу ют следующие современные информационные технологии:
•механизм прямого доступа к данным, хранящимся в любом месте в любом формате;
•механизм составления отчетов по данным, берущимся из фазных корпоративных источников;
•оптимизацию работы с огромным количеством данных (объемом до десятков терабайтов);
•построение хранилищ данных Data Warehouse (соглас но терминологии IBM, хранилищ информации) и спе циализированных хранилищ данных— витрин данных
Data Mart;
447
•аналитическую обработку данных в режиме реального времени OLAP, ассоциируемую с многомерным пред ставлением информации (в обиходе — "кубами", "ги перкубами") на основе:
•форматов, являющихся частной собственностью фирмизготогителей — MDDB (MOLAP);
•реляционных СУБД — ROLAP;
•гибридного исполнения — HOLAP;
•доставку информации по ИНТЕРНЕТУ/ИНТРАНЕТУ;
•так называемую добычу информации или разработку данных, Data Mining, что позволяет в автоматическом режиме выявлять скрытые закономерности в огром ных массивах данных.
Два класса прикладных систем. Системы ППР выполня ют особую роль — поставляют уполномоченным лицам ин тегральную информацию о деятельности организации. В этом они по сути отличаются от систем, автоматизирующих ка кой-то определенный вид ее деятельности. Если последние решают оперативные деловые задачи и технически исполне ны в транзакционной среде, то СППР имеют аналитическую ориентацию, способствуют решению стратегических задач и должны надежно обрабатывать очень большие массивы дан ных. Оперативные системы создают данные, стратегические системы очищают и согласуют эти данные, интенсивно с ними работают и получают ценную информацию. Пользователи опе ративных систем — специалисты в конкретной области, а стратегических систем — высший круг управляющих и ана литические службы.
Отношение СППР к другим автоматизированным систе мам (АС). В общей информационной структуре организации СППР занимают высшее иерархическое положение, так как используют массивы данных из уже существующих приклад ных задач и систем (рис. 5.5.2). Существует мнение, что по этой причине внедрять СППР имеет смысл только в случае развитой вычислительной инфраструктуры организации, когда уже сложились устойчивые процессы накопления электрон-
448
иных данных, а их разнообразие достаточно для описания и |
|
• последующего анализа деловой области. |
|
Но можно посмотреть на этот |
вопрос с другой стороны. |
I Системы ППР используют другие системы. Внедрение СППР |
|
Вне требует обязательных изменений |
в существующую среду |
I автоматизации и не накладывает |
обязательных требований |
I; к внедряемым или планируемым к внедрению системам. |
|
Внедрение СППР позволяет объединить накопленные в |
|
I "островах" данные и работать с ними в своих целях. При этом |
|
I перевооружение (и интеграция) существующих систем мо- |
|
В-жет идти на местах своим путем и по своему плану. В "остро вах" (отделах, департаментах, предприятиях и т. д.) могут I выбираться лучшие на рынке транзакционные системы, вне-
• |
дряться и поддерживаться. Система ППР, стоящая над этим, |
[ просто начнет брать данные из нового источника. |
|
I |
В этом отношении внедрение системы ППР и ее исполь- |
зование может начаться в любой момент развития информа- |
|
| |
ционной среды. По мере появления новых источников дан- |
I ных (внутренних и внешних) СППР расширяет свои возмож- |
|
I ности (см. рис. 5.5.2.). Здесь хранилище данных является цент- |
|
, |
рольным, что является классическим вариантом архитекту- |
[ |
ры. Наличие единого места хранения всех данных организа |
|
ции дает гарантию, что процесс дальнейшей обработки дан |
|
ных может строго контролироваться и в конечном счете все |
|
пользователи СППР будут работать с одной версией данных. |
|
Хранилище развязывает ППР от оперативной приклад |
|
ной части информационной системы организации. Обработка |
|
данных в ППР осуществляется аналитиками; результирую |
|
щая информация в конечном счете поставляется руковод |
|
ству [70]. |
|
Интеграционные качества систем ППР. Использование |
|
технологии Data Warehouse в ППР особенно эффективно, когда |
i |
организация одновременно работает с разными моделями и |
|
форматами данных, разными автоматизированными система |
|
ми, может быть, разработанными разными фирмами. Приме- |
|
449 |

Рис. 5.5.2. Место СППР в информационной системе организации
ром может служить (рис. 5.5.3.) информационная среда, состо ящая из разных прикладных систем и программных пакетов от разных производителей и, скажем, клубной платежной
450
Рис. 5.5.3. Интеграция прикладных систем на основе ППР
системы на основе магнитных карт и, дополнительно, авто матизированной системы делопроизводства [57, 70].
Непосредственная интеграция таких систем в режиме реального времени вряд ли возможна, но они могут быть проинтегрированы на верхнем — аналитическом уровне. Как результат, персонал работает с привычными интерфейсами,
451
а руководство владеет всей управляющей информацией, при чем более богатой и многогранной, так как она собирается из разных систем.
Наконец, интегрирующие качества СППР позволяют по купать на рынке лучшую (в конкретной предметной области) автоматизированную систему. В результате организация, ис пользуя разные системы, никогда не встретится с труднодо ступными "островами информации".
Оценки стоимости системы. Любая СППР создается на основе требований дела и должна предоставлять информацию, имеющую для дела реальную цену. Так как создание и внедре ние полнофункциональной СППР — всегда значительные ин вестиции, то, исходя из мировой практики, экономическая целесообразность этого шага всегда должна быть обоснована.
В целом, можно выделить следующие проблемы, реша емые внедрением этих систем:
•получение доступа ко всем данным организации, ко всем "островам информации";
•получение содержательной информации (коммерчес кой экономической, политической, по окружающей среде);
•создание новых'специализированных систем аналити ческой направленности (прогнозирование, управление парком оборудования, управление размещением отхо дов, управление вопросами здоровья персонала, оцен
ки рисков и многое др.).
Стоимость создания СППР высока: одно рабочее место составляет порядка нескольких тысяч долларов США, сер верная часть — от десятков тысяч долларов, цена СППР ма лого масштаба — порядка 60—100 тыс. долл., стоимость пол нофункциональной системы корпорации может достигать мил лионов долларов США.
Обзор компании МЕТА Group показал, что крупная орга низация, внедряя у себя Data Warehouse в полном объеме, в среднем тратит 1,8 млн долл. США на оборудование и 1,4 млн долл. на соответствующее программное обеспечение. Неуди вительно, что это позволяют себе делать в основном компа нии, входящие в "список 1000" журнала "Fortune".
452
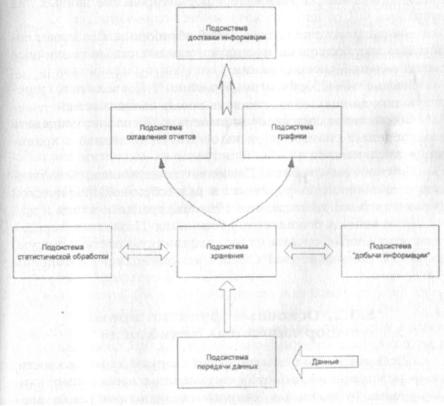
Система ППР интенсивно работает с данными, которые постоянно создают различные оперативные прикладные си стемы. Хранилище данных — основа СППР. Оно накапливает как все исходные транзакционные данные, так и результа ты их статистической и аналитической обработки. Хранили ще данных управляется по концепции метаданных.
Результаты функционирования СППР, включая отчеты и графики, передаются пользователям — исследователям аналитикам и руководящему составу. Общая структура сис темы ППР может быть представлена подсистемами, отобра женными на рис. 5.5.4.
Рис. 5.5.4. Типичная структура СППР
453