

2_0
.pdf4) Проверяем адекватность модели в целом по F- критерию Фишера. Находим фактическое значение критерия Фишера
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
∑(y − y) |
/ m |
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
= |
|
ˆ |
i |
|
|
|
|
|
= |
|
R |
2 |
|
|
(n − 2) |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
F |
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
∑(yi − |
|
|
)2 |
/ (n − m − 1) |
|
− R2 |
|||||||||||||||
|
|
|
факт |
|
|
|
|
1 |
|
|||||||||||||
|
|
|
|
|
y |
|
||||||||||||||||
F |
= |
|
R2 |
|
(n − 2) = |
|
0,974 |
3 = |
0,974 |
3 = 112,384. |
||||||||||||
|
− R2 |
|
|
|
||||||||||||||||||
фак |
1 |
|
|
|
1− 0,974 |
0,026 |
|
|
|
|||||||||||||
Табличное значение критерия Фишера при степенях свободы k1 = 1, |
||||||||||||||||||||||
k2 = n − 2 = 3 и уровне |
значимости |
|
α = 0,05 |
равно |
Fтабл = 10,13. Так как |
|||||||||||||||||
Fфакт > Fтабл , то признается статистическая значимость уравнения в целом.
5) Оценка статистической значимости коэффициентов регрессии и ко- эффициента корреляции проводится с помощью t -критерий Стьюдента. Для этого вычислим случайные ошибки параметров линейной регрессии и коэф- фициента корреляции:
|
|
|
2 |
|
5,730 |
|
|
|
|
|
|
|
|
|
||||||
Se2 = |
∑(y − yx ) |
|
= |
|
= 1,91 |
, |
Se = |
Se2 =1,382 , |
||||||||||||
n − 2 |
|
|
5 |
− 2 |
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
∑xi2 |
|
|
|
|
|
205 |
|
|||||||||
Saˆ |
= Se |
|
|
|
i=1 |
|
|
|
|
|
|
|
= 1,382 |
= 0,989 , |
||||||
|
n |
|
|
|
|
|
|
|
|
5 80 |
||||||||||
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
n∑(xi − |
x |
)2 |
|
|
|
|
|
|
|
|||||||||
|
|
|
i=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
Saˆ = |
|
|
|
Se |
|
|
|
|
|
|
|
= |
1,382 |
= 0,155. |
|||||
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
∑(xi |
− |
|
)2 |
|
|
|
80 |
|
|
|
|||||||
|
|
|
x |
|
|
|
|
|
||||||||||||
i=1
Фактические значения t - статистик
|
|
ˆ |
|
2,864 |
|
|
|
|
|
aˆ1 |
|
|
|
|
||
taˆ |
= |
a0 |
= |
= 2,896, |
taˆ |
= |
= |
1,631 |
= 10,523 , |
|||||||
Saˆ |
0,989 |
|
|
|
||||||||||||
0 |
|
|
|
1 |
Saˆ |
0,155 |
|
|||||||||
|
|
|
|
|
|
|
|
|
||||||||
|
|
0 |
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
tr = |
R |
n − 2 |
= |
0,987 3 |
= |
0,987 1,732 |
= 10,618. |
||||||||
|
|
|
1− 0,974 |
|
||||||||||||
|
|
|
|
1− R2 |
|
|
0,161 |
|
|
|
||||||
70
|
|
|
Табличное значение t -критерия Стьюдента при |
уровне значимости |
||||||||||
α = 0,05 |
и числе степеней свободы k = n − 2 = 3 есть |
tтабл = 3,183 . Так как |
||||||||||||
|
taˆ |
|
> tтабл , |
|
taˆ |
|
> tтабл и |
|
tr |
|
> tтабл , то признаем статистическую значимость па- |
|||
|
|
|
|
|
|
|||||||||
|
1 |
|
|
|
0 |
|
|
|
|
|
|
|
|
|
раметров регрессии и коэффициента корреляции. |
|
|||||||||||||
|
|
|
6) Для расчёта доверительных интервалов параметров регрессии опре- |
|||||||||||
деляем предельную ошибку |
для каждого показателя: |
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
a |
= tтабл Saˆ , |
a = tтабл Saˆ . |
|
|
|
|
|
0 |
0 |
1 |
1 |
|||||||
Формулы для расчёта доверительных интервалов имеют следующий
вид:
ˆ |
< a0 |
ˆ |
+ a |
, |
|
ˆ |
− |
a < a1 |
ˆ |
+ |
a . |
|
a0 − a |
< a0 |
|
a1 |
< a1 |
||||||||
0 |
|
|
0 |
|
|
|
|
1 |
|
|
|
1 |
|
|
|
ˆ |
− |
ˆ |
+ |
a |
), |
ˆ |
− a |
ˆ |
+ a ) с на- |
Это означает, что интервалы (a0 |
a ;a0 |
(a1 |
;a1 |
|||||||||
|
|
|
|
|
0 |
|
0 |
|
|
1 |
1 |
|
дёжностью α покрывают определяемые параметры a0 |
, a1 . |
|
|
|||||||||
Замечание. Если в границы доверительного интервала попадает ноль, т.е. нижняя граница отрицательна, а верхняя положительна, то оцениваемый параметр принимается нулевым, так как он не может одновременно прини- мать и положительное, и отрицательное значения.
Рассчитаем доверительные интервалы для параметров регрессии a0 , a1
a0 |
± tтабл Saˆ |
и a1 ± tтабл Saˆ . |
|
ˆ |
0 |
ˆ |
1 |
|
|
||
Получаем, что |
|
|
|
a0 (2,864 − 3,1825 0,989; |
2,864+3,1825 0,989), |
a0 (−0,283; 6,011) |
|
и
a1 (1,631− 3,1825 0,155; 1,631+3,1825 0,155) , a1 (1,138; 2.124) .
7) Ошибка аппроксимации
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
= |
1 |
n |
|
yi |
− yx |
|
100% = |
1 |
n |
|
e |
|
100% = |
0,122 |
100%=2,44% |
Eотн |
|
∑ |
|
|
i |
|
|
∑ |
|
i |
|
|
||||
|
|
yi |
|
yi |
5 |
|||||||||||
|
|
n i=1 |
|
|
|
|
n i=1 |
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
говорит о хорошем подборе модели для исходных данных.
71

8) Прогнозное значение yпр ≈ yˆпр определяется путём подстановки в уравнение регрессии yˆx = yˆ = aˆ0 + aˆ1 x соответствующего (прогнозного) зна- чения xпр .
Рассчитаем прогнозное значение результативного фактора |
|
при зна- |
yпр |
чении признака-фактора, который по условию составляет 110% от среднего уровня xпр = 1,1 x = 1,1 5 = 5,5 .
|
= 2,864+1,631 5,5 = 11,835 |
yпр |
9) Ошибка прогноза. Доверительный интервал прогноза.
Средняя стандартная ошибка прогноза
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
(xp − |
|
|
)2 |
|
|
|
|
|
|
|
|
|
|
|
y |
|
|
= tтабл Se |
1+ |
x |
, |
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
+ n |
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
пр |
|
n |
|
∑(xi − |
|
)2 |
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
x |
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i=1 |
|
|
|
|
||||
|
|
|
|
|
1 |
|
|
|
(xp − |
|
|
)2 |
|
|
|
|
|
|
|
|
|
1 |
|
|
(5,5 − 5)2 |
|
y = tтабл Se |
1+ |
+ |
x |
= 3,183 1,382 1+ |
+ |
|||||||||||||||||||||
|
|
n |
|
|
= 4,824 . |
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
пр |
|
|
|
n ∑(xi − |
|
)2 |
|
|
|
|
|
|
|
|
|
5 |
|
|
80 |
||||||
|
|
|
|
x |
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
i=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
Доверительный интервал для прогнозных значений имеет вид |
|||||||||||||||||||||||||
|
ˆ |
− |
|
ˆ |
+ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
y |
|
; y |
|
|
|
= (11,835 − 4,824; 11,835 + 4,824) = (7,011; 16,659). |
|||||||||||||||||||
|
пр |
|
yпр |
пр |
|
|
|
yпр |
|
|
|
|
|
|
|
|
|
|
|
|
||||||
Доверительный интервал математическое ожидание прогноза имеет вид:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
M ( yпр ) |
|
|
|
|
|
|
|
|
1 |
|
(xp − x ) |
|
|
|
|
|
|
1 |
|
(xp − x ) |
|
||||||||||||||
|
ˆ |
|
− tтабл Se |
+ |
|
; |
ˆ |
|
|
+ |
|
|
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
yпр |
|
|
n |
|
|
|
|
|
yпр + tтабл Se |
|
n |
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
∑ |
(x − x)2 |
|
|
|
|
|
n |
|
∑ |
(x − x)2 |
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i |
|
|
|
|
|
|
|
|
i |
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i=1 |
|
|
|
|
|
|
|
|
|
|
|
|
i=1 |
|
|
|
|
|
|
|
|
|
|
1 |
|
|
(xp − |
|
|
)2 |
|
|
|
|
|
|
|
|
|
1 |
|
(5,5 − 5)2 |
|
|
|
|
|
|
|
|
|
|
||||
tтабл S |
|
|
|
+ |
x |
= 3,183 1,382 |
+ |
= 1,983 |
|
|
|
|
|
|
|
||||||||||||||||||||
e |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
n |
|
∑(xi − |
|
)2 |
|
|
|
|
|
|
|
|
|
5 |
|
80 |
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
x |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
i=1
72
M ( yпр ) (11,835 − 1,983; 11,835 + 1,983) = (9,852; 13,818) .
10) На одном графике строим корреляционное поле и линию регрессии
(Рис.2.6.3).
Рассмотрим третий, основной, способ построения и анализа регрес- сионной модели с помощью компьютера
Открыть Excel; копировать или набрать массив данных (если массив данных расположен строками, то транспонированием располагают их столб- цами):
Y |
X |
4,1 |
0 |
6 |
2 |
8 |
4 |
15 |
8 |
22 |
11 |
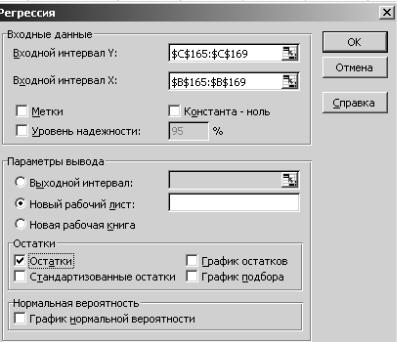
«Сервис»; «Анализ данных»; «Регрессия»; «ОК»; внести входные интерва-
лы, выделяя их последовательно курсором (Рис. 2.6.4.);
Рис. 2.6.4
«ОК». Появится протокол выполнения регрессивного анализа
73
Протокол выполнения регрессивного анализа
Регрессионная статистика
Множественный R |
|
0,9868 |
|
|
|
R-квадрат |
|
|
0,9738 |
|
|
Нормированный R-квадрат |
0,9651 |
|
|
||
Стандартная ошибка |
|
1,3820 |
|
|
|
Наблюдения |
|
|
5 |
|
|
Дисперсионный анализ |
|
|
|
||
|
df |
SS |
MS |
F |
Значимость F |
Регрессия |
1 |
212,8781 |
212,8781 |
111,4569 |
0,0018 |
Остаток |
3 |
5,7299 |
1,9100 |
|
|
Итого |
4 |
218,6080 |
|
|
|
|
Коэффи- |
Стандар- |
t-стати- |
P – Знач- |
Нижние |
Верхние |
|
циенты |
тная ошибка |
стика |
ение |
95% |
95% |
Y-пересечение |
2,8638 |
0,9894 |
2,8945 |
0,0628 |
-0,2849 |
6,0124 |
Переменная X 1 |
1,6313 |
0,1545 |
10,5573 |
0,0018 |
1,1395 |
2,1230 |
Вывод остатка |
|
|
|
|
|
|
Наблюдение |
Предсказанное Y |
Остатки |
|
|
||
1 |
2,8638 |
1,2363 |
|
|
||
2 |
6,1263 |
− 0,1263 |
|
|
||
3 |
9,3888 |
− 1,3888 |
|
|
||
4 |
15,9138 |
− 0,9138 |
|
|
||
5 |
20,8075 |
1,1925 |
|
|
||
Надо заметить, что некоторые числа в протоколе отличаются от чисел, полученных непосредственно. Это вызвано тем, что после запятой брали три знака.
Замечание 1. Если надо только значения чисел из протокола, то его лучше делать рисунком. Если же надо использовать числа из протокола при дальнейших расчетах, то его лучше копировать таблицами, что здесь и пред- ставлено.
Рассмотрим содержание протокола регрессивного анализа, в котором отражены основные итоги расчётов.
Замечание 2. При составлении уравнений регрессии надо обязательно проверять выполнение предпосылок применения метода наименьших квадра- тов. Основными из них являются: отсутствие автокорреляции остатков, на- личие гомоскедастичности и отсутствие мультиколлинеарности для много- факторной регрессии. Эти вопросы в пособии не рассматриваются.
74

ВЫВОД ИТОГОВ
Регрессионная статистика
Наименование показателя |
Принятые |
Наименование показателя |
|
|
|
|
|
|
Формула |
|
|
||||||||||||
в отчёте Excel |
обозначения |
в отчёте Excel |
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
Множественный R |
|
R |
Коэффициент множественной корреляции, |
|
|
|
|
|
|
R = |
R2 |
|
|
||||||||||
|
индекс корреляции |
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
n |
|
|
2 |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
∑ei |
|
|
|
∑( yi − y) |
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
ˆ |
|
|
|||
R-квадрат |
2 |
|
2 |
|
|
2 |
|
|
|
i=1 |
|
|
|
i=1 |
|
|
|||||||
R |
Коэффициент детерминации R |
|
R |
|
= 1 − |
|
n |
|
= |
|
n |
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
∑( yi − |
|
)2 |
|
|
∑( yi − |
|
)2 |
|
||||
|
|
|
|
|
|
|
|
|
|
y |
y |
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
i=1 |
|
|
|
i=1 |
|
|
|||||
Нормированный R - квадрат |
|
|
2 |
Скорректированный R -квадрат |
|
|
|
2 |
= 1 |
− (1 − R2 ) |
|
n − 1 |
|
|
|||||||||
|
|
|
R |
|
|
|
|||||||||||||||||
|
R |
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
n − m − 1 |
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
Стандартная ошибка |
|
Se |
Среднеквадратическое отклонение от модели |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Наблюдения |
|
n |
Количество наблюдений |
|
|
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|||
Дисперсионный анализ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
df |
|
|
|
SS |
|
|
|
MS |
|
|
|
F |
|
|
|
|
Значимость F |
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
SSR / m |
|
|
R2 n − m − 1 |
|
|
|
|
|
|
||||||
|
Регрессия |
|
m |
|
|
|
∑( yi − y) |
= SSR |
SSR / df |
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
ˆ |
|
|
|
|
|
|
|
|
F = |
|
|
= |
|
|
|
|
|
|
|
|
|
F распр (F; |
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SSE / (n − m − 1) |
(1 − R2 ) |
|
m |
|
|
|
|||||||||
|
Остаток |
n − m − 1 |
|
|
|
ˆ |
) |
2 |
= SSE |
SSE / df |
|
|
||||||||||||||||||||||||
|
|
|
∑( yi − yi |
|
|
|
Статистика |
|
|
|
|
|
|
df (регр.); |
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
df (ост.)) |
|||||||
|
|
|
n − 1 |
|
|
∑( yi − yi ) |
|
= SST |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
Итого |
|
|
|
|
|
|
|
|
|
F= MS(регр) / MS(ост) |
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
Коэф. |
|
Станд. ошибка |
t-статистика |
P-значение |
|
|
Нижние 95% |
|
Верхние 95% |
||||||||||||||||||||||
|
y-пересечение |
|
aˆ |
|
|
|
|
|
Saˆ |
ta |
ˆ |
/ Saˆ |
P-значение = |
|
Нижние и верхние границы 95% |
|||||||||||||||||||||
|
|
|
|
|
|
|
= a0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
0 |
|
0 |
СТЬЮДРАСПРЕДЕЛЕНИЕ |
доверительных интервалов |
||||||||||||||||
|
x1 |
|
|
|
aˆ1 |
|
|
|
|
|
Saˆ1 |
ta1 |
= aˆ1 / Saˆ1 |
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
(t-статистика; n-m-1) |
|
коэффициентов регрессии |
|||||||||||||||||||||||||
|
x2 |
|
|
|
aˆ2 |
|
|
|
|
|
Saˆ2 |
ta2 |
= aˆ2 / Saˆ2 |
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
Вывод остатка |
|
|
|
|
|
|
|
|
|
|
|
|
|
Дополнительные |
расчёты с остатками |
ei , yˆi , yi |
и т. д. |
|
|
||||||||||||||||
|
Наблюдение |
Предсказанное Y |
|
|
|
|
Остатки |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
Номер |
|
|
|
|
ˆ |
|
|
|
|
|
|
|
|
|
ei |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
yi |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
75 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2.7. Многофакторная регрессия
Пример 2. 7. Изучается влияние стоимости основных фондов и оборот- ных активов на величину валового дохода торговых предприятий. Для этого по восьми предприятиям были получены данные, приведенные в табл. 2.7.1.
|
|
|
Таблица 2.7.1 |
|
|
|
|
|
|
Номер |
Валовой доход за год, |
Среднегодовая стоимость, млн. грн. |
||
предприятия |
млн. грн. |
|
|
|
Основных |
Оборотных |
|||
|
|
|||
|
|
фондов |
средств |
|
|
|
|
|
|
№ |
Y |
X1 |
X 2 |
|
1 |
12 |
6 |
6 |
|
2 |
9 |
3 |
4 |
|
3 |
16 |
10 |
8 |
|
4 |
11 |
5 |
5 |
|
5 |
16 |
11 |
8 |
|
6 |
20 |
14 |
10 |
|
7 |
15 |
10 |
7 |
|
8 |
16 |
10 |
8 |
|
Предполагая, что между переменными Y, X1, X2 существует линейная зависимость, требуется: 1) найти уравнение регрессии Y на Х1 и Х2 ; 2) оп- ределить коэффициент детерминации, коэффициент множественной корре- ляции, скорректированный (нормированный) коэффициент множественный детерминации; 3) проверить значимость модели регрессии, проверить значи- мость коэффициента множественной корреляции; 4) оценить статистическую значимость коэффициентов регрессии, найти доверительные интервалы ко- эффициентов регрессии; 5) найти среднюю относительную ошибку аппрок- симации; 6) найти прогнозное значения yпр для x1пр = 8 и x2пр = 9 и постро-
ить доверительные интервалы для индивидуального прогнозного значения зависимой переменной и для ее математического ожидания; 7) дать экономи- ческую интерпретацию коэффициентов регрессии, найти эластичность, бета- коэффициенты, дельта коэффициенты, сделать экономические выводы.
Примечание. Вычисления произвести с помощью аналитических фор- мул и с помощью пакета «Анализ данных», значимость α = 0,05
Решение. 1) Составим уравнение линейной регрессии. Теоретическое уравнение линейной регрессии имеет вид
Y = a0 + a1 Х1 + a2 Х2 + ε .
Его покомпонентная запись:
76

yi = a0 + a1 xi1 + a2 xi2 + εi , i =1,8.
Составим корреляционную матрицу
r |
r |
r |
|
1 |
0,992 |
0,995 |
|
|
|
yy |
yx |
yx |
|
||||
|
1 |
2 |
= |
1 |
0,982 |
. |
||
R = r |
r |
r |
|
|||||
|
x1y |
x1x1 |
x1x2 |
|
|
|
|
|
|
r |
r |
|
|
1 |
|
||
r |
|
|
|
|
||||
|
x2 y |
x2x1 |
x2x2 |
|
|
|
|
|
Как видно из матрицы R связь между показателями Y , X1 и X2 доста- точно высокая, что свидетельствует о правильном выборе спецификации мо- дели.
Найдём оценки aˆ0 ,aˆ1,aˆ2 этого уравнения. Коэффициенты aˆ0 ,aˆ1,aˆ2 опре- делим матричным способом. Оценки параметров находятся по формуле
ˆ |
−1 |
X ′ Y . |
A = ( X ′ X ) |
|
Выполняем соответствующие этой формуле действия над матрицами:
|
1 |
6 |
6 |
|
|
|
|
12 |
|
|
|
||||||
|
1 |
3 |
4 |
|
|
|
|
9 |
|
1 |
10 |
8 |
|
|
|
|
16 |
X = |
1 |
5 |
5 |
Y = |
|
|
|
11 |
|
1 |
11 |
8 |
|
|
|
|
16 |
|
1 |
14 |
10 |
|
|
|
|
20 |
|
1 |
10 |
7 |
|
|
|
|
15 |
|
1 |
10 |
8 |
|
|
|
|
16 |
|
|
|
|
|
|
|
|
|
|
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
||||||
X ′ = |
|
6 |
3 |
10 |
5 |
11 |
14 |
10 |
10 |
||||||
|
|
6 |
4 |
8 |
5 |
8 |
10 |
7 |
8 |
||||||
|
|
|
X ′X = |
|
|
|
8 |
|
69 |
56 |
|
|
|
||
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
69 |
|
687 |
531 |
|
|
|
|||
|
|
|
|
|
|
|
|
|
56 |
|
531 |
418 |
|
|
|
( X ′X )−1 = |
|
7,677 |
1,319 |
−2,704 |
|||||||||||
|
|||||||||||||||
|
1,319 |
0,307 |
−0,566 |
||||||||||||
|
|
|
|
|
−2,704 |
−0,566 |
1,084 |
||||||||
77

|
115 |
|
|
= ( X ′X ) |
|
|
3,509 |
X ′Y = |
1080 |
|
ˆ |
−1 |
X ′Y = |
0,416 |
|
|
A |
|
|||||
|
852 |
|
|
|
|
|
1,040 |
Линейное уравнение множественной регрессии имеет вид |
|||||||
|
|
|
= 3,509 + 0,416 x1 +1,040 |
x2 . |
|
|
|
|
|
yx |
|
|
|
||
Оценим качества уравнения регрессии. Качество модели регрессии свя- зывают с её адекватностью наблюдаемым (эмпирическим данным). Проверка адекватности (или соответствия) модели регрессии наблюдаемым данным проводится на основе анализа остатков ei .
Для удобства дальнейших вычислений составим табл. 2.7.2.
Таблица 2.7.2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
№ |
|
|
|
|
|
|
|
|
|
(yi − y) |
|
ˆ |
ei |
|
2 |
Ei = |
|
|
|
/ yi |
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
yi |
|
|
|
xi1 |
|
|
xi2 |
|
|
|
yi |
|
ei |
|
ei |
|
|||||||||||
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
1 |
|
12 |
|
|
|
6 |
11 |
5,641 |
|
|
12,243 |
-0,243 |
|
0,059 |
0,020 |
||||||||||||
2 |
|
9 |
|
|
|
4 |
10 |
28,891 |
|
|
8,916 |
0,084 |
|
0,007 |
0,009 |
||||||||||||
3 |
|
16 |
|
|
|
8 |
10 |
2,641 |
|
|
15,987 |
0,013 |
|
0,000 |
0,001 |
||||||||||||
4 |
|
11 |
|
|
|
6 |
9 |
11,391 |
|
|
10,788 |
0,212 |
|
0,045 |
0,019 |
||||||||||||
5 |
|
16 |
|
|
|
8 |
12 |
2,641 |
|
|
16,403 |
-0,403 |
|
0,162 |
0,025 |
||||||||||||
6 |
|
20 |
|
|
|
10 |
16 |
31,641 |
|
|
19,730 |
0,270 |
|
0,073 |
0,013 |
||||||||||||
7 |
|
15 |
|
|
|
8 |
12 |
0,391 |
|
|
14,947 |
0,053 |
|
0,003 |
0,004 |
||||||||||||
8 |
|
16 |
|
|
|
7 |
13 |
2,641 |
|
|
15,987 |
0,013 |
|
0,000 |
0,001 |
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
Σ=0,093 |
|||||
|
|
|
|
|
|
|
|
|
|
|
SST = ∑ = |
|
|
|
SSE = |
∑ei = |
E =1,2% |
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
y =14,375 |
|
x1 |
= 8,625 |
|
x2 = 7 |
|
- |
|
||||||||||||||||||
|
|
|
= 85,875 |
|
|
= 0,350 |
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
2) Рассчитываем коэффициент детерминации по формуле |
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
R2 = |
SSR |
= 1− |
SSE |
, |
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
SST |
|
SST |
|
|
|
|
|
|
|
|
|||||
где SSR – объяснённая сумма квадратов, а SST – общая сумма квадра-
тов.
Коэффициент детерминации представим в следующем виде:
|
|
ˆ |
|
|
|
|
|
2 |
|
ˆ |
2 |
|
2 |
|
|
|
|
|
|||
2 |
|
− y) |
|
|
|
0,35 |
|
|
|||||||||||||
= |
∑( yx |
|
=1− |
∑( y − yx ) |
|
=1− |
∑ei |
=1− |
|
= 0,996. |
|||||||||||
R |
|
|
|
|
|
|
|
|
|
|
|
||||||||||
∑( y − |
|
|
)2 |
∑( y − |
|
)2 |
∑( y − |
|
)2 |
85,875 |
|||||||||||
|
|
y |
|
y |
|
y |
|
|
|||||||||||||
78

Так как R2 ≈ 1, то качество модели можно считать высоким. Это озна- чает, что 99,6% изменения валового дохода торговых предприятий зависит от стоимости основных и оборотных средств.
Рассчитаем коэффициент множественной корреляции:
|
|
|
|
R = |
R2 = 0,996 = 0,998, 0 ≤ R ≤ 1. |
|
|
||||
Скорректированный (нормированный) множественный коэффициент |
|||||||||||
детерминации |
|
2 рассчитывается так: |
|
|
|
|
|
||||
R |
|
|
|
|
|
||||||
|
|
2 = 1− (1− R2 ) |
n − 1 |
|
= 1− (1− 0,996) |
|
8 − 1 |
|
= 0,994 . |
||
|
R |
||||||||||
|
n − m − 1 |
|
− 2 − |
|
|||||||
|
|
|
|
|
8 |
1 |
|||||
Это означает, что дисперсия результативного признака y , объясняется на 99,4% влиянием переменных X1 и X2 . Оставшаяся доля дисперсии 0,6% вызвана влиянием других, не учтённых в модели факторов. Множественный коэффициент корреляции и его скорректированное значение, соответственно, равны: R = 0,998; R = 0,994 . Близость его к единице говорит о тесной связи результативного признака с исследуемыми факторами.
Далее необходимо проверить значимость построенной модели.
3) Для проверки значимости уравнения регрессии и значимости коэф- фициента детерминации используется F-критерий Фишера, вычисляемый по формуле
F |
= |
|
R2 |
|
|
n − m − 1 |
= |
|
0,996 |
|
8 − 2 − 1 |
=622,5. |
|
− R2 |
|
|
2 |
||||||||
расч |
1 |
|
m |
1 − 0,996 |
|
|||||||
Табличное значение |
F-критерия |
|
Фишера |
при степенях свободы |
||||||||
k1 = m = 2 , k2 = n − m − 1 = 8 − 2 − 1 = 5 и |
уровне значимости α = 0,05 равно |
|||||||||||
Fтабл = 5,79 . |
|
|
|
|
|
|
|
|
|
|
|
|
Так как Fрасч > Fтабл , то признается статистическая значимость уравне-
ния в целом.
Для проверки значимости коэффициента множественной корреляции вычисляем t -критерий Стьюдента
t = |
R |
n − m |
− 1 = |
0,998 |
8 |
− 2 |
− 1 |
= 35,350. |
|
1− R2 |
1− 0,996 |
||||||||
расч |
|
|
|
|
|
|
|||
По таблице находим |
tтабл |
– соответствующее табличное значение t- |
|||||||
распределения Стьюдента с n − m − 1 степенями свободы, и уровнем значимо-
сти α . tтабл = tα ; n-m-1 = t0,05; 5 = 2,571.
79