

Алгоритм с возвратом при неудачном шаге
Задать начальный шаг h0, число проб s n и точность .
Сгенерировать или задать начальную точку X0 и вычислить в ней функцию f; положить i=1 (i – счетчик проб).
Сгенерировать случайный вектор направления
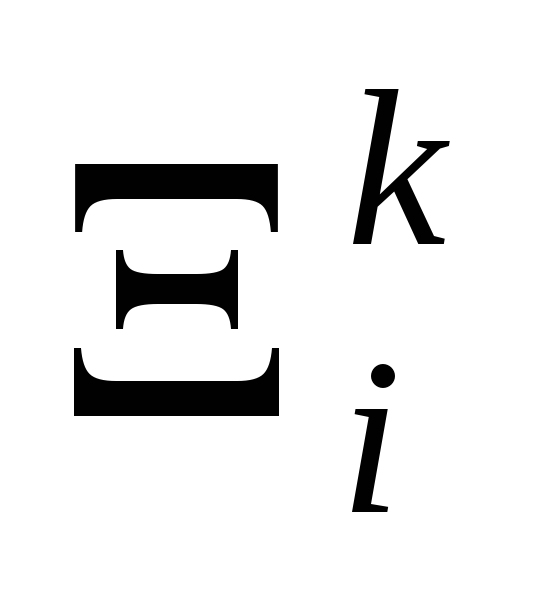 .
.На направлении
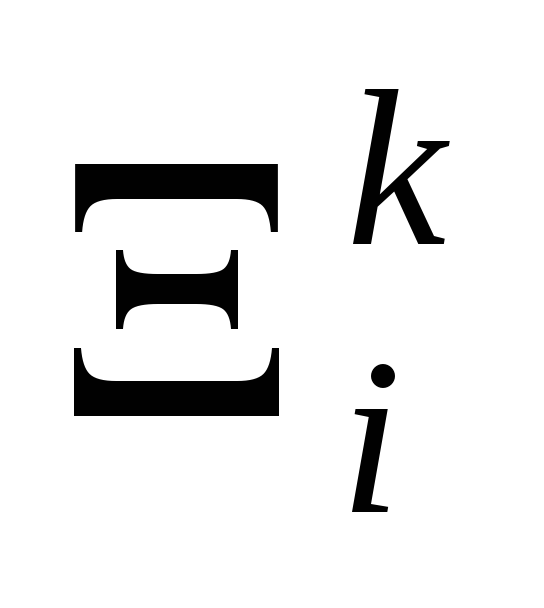 определить точку
Xk+1
= Xk
+ hkk
и вычислить
в ней функцию f.
определить точку
Xk+1
= Xk
+ hkk
и вычислить
в ней функцию f.Проверить: а) если f(Xk+1)<f(Xk), положить k=k+1, i=1 и вернуться на 3; б) если f(Xk+1)f(Xk) и i<s, положить i= i+1 и вернуться на 3; в) если f(Xk+1)f(Xk), i=s и hk >, положить hk= hk/2, i=1 и вернуться на 3. г) если f(Xk+1)f(Xk), i=s и hk, поиск закончить, приняв Xk за точку минимума.▲
Т аким
образом, поиск останавливается, если в
текущей точкеs
направлений, сгенерированных подряд,
оказались неудачными при шаге, меньшем
заданной точности. На рис. 8.38 показан
характер движения при поиске по данному
алгоритму (жирной линией выделены
успешные шаги).
аким
образом, поиск останавливается, если в
текущей точкеs
направлений, сгенерированных подряд,
оказались неудачными при шаге, меньшем
заданной точности. На рис. 8.38 показан
характер движения при поиске по данному
алгоритму (жирной линией выделены
успешные шаги).
Алгоритм с обратным шагом
Он построен путем модификации предыдущего алгоритма с целью уменьшить число розыгрышей направлений. Внесено следующее изменение: если сгенерированное направление неудачное, то после возврата в исходную точку Xk делается шаг в противоположном направлении; если же и оно неудачное, то генерируется новое направление из точки Xk. Логика действия очевидна: если в данном направлении функция ухудшается, то можно ожидать, что в противоположном направлении она улучшится. Понятно, что эффект модернизации алгоритма тем выше, чем ближе функция в текущей области к линейной.
Алгоритм наилучшей пробы
Здесь используются два шага: пробный и рабочий h. Величина пробного шага соответствует необходимой точности. Задается также число пробных шагов m, меньшее числа переменных n, причем разница между m и n увеличивается с ростом n.
В текущей точке генерируются m направлений j и на них делаются пробные шаги. Вычисляются изменения функции
![]() .
.
В направлении с наименьшим (отрицательным) приращением fj выполняется рабочий шаг:
![]() .
.
Поиск
заканчивается, если![]() .
.
По
аналогии с предыдущим алгоритмом можно
рассматривать и неудачные направления:
вычислить
![]() .
Если максимум соответствует положительному
приращениюfj,
то рабочий шаг делается в противоположном
направлении.
.
Если максимум соответствует положительному
приращениюfj,
то рабочий шаг делается в противоположном
направлении.
Алгоритм статистического градиента
Все параметры и начальные действия такие же, как в предыдущем алгоритме. Отличие состоит в выборе направления движения. Оно определяется с учетом всех разыгранных направлений:
![]() . (8.53)
. (8.53)
Направление y называется статистическим градиентом. В пределе (m) он стремится к градиенту f. Но определение y требует меньше вычислений, чем f, и тем в большей степени, чем сильнее неравенство m<n.
Согласно (8.53) каждый компонент вектора увычисляется по формуле
![]() .
.
Новая точка находится перемещением на рабочий шаг h в направлении статистического антиградиента:
![]() .
.
Поиск
завершается при выполнении условия
![]() или
или![]() ▲
▲
Эффективность рассмотренных алгоритмов можно повысить за счет незначительных изменений их отдельных элементов или шагов. Так, при успешном шаге можно продолжать шаги в найденном направлении до тех пор, пока функция улучшается (использование идеи одномерной минимизации).
Другая возможная модификация заключается во введении в алгоритм процедуры самообучения (адаптации). Это касается вероятностных характеристик случайного вектора . Первоначально все направления этого вектора равновероятны. В процессе поиска накапливается информация об эффективности разыгранных направлений, на основе которой корректируется распределение вероятностей направлений случайного вектора. В результате повышается вероятность удачных направлений при одновременном снижении вероятности неудачных.
Как следует из логики алгоритмов случайного поиска, при прочих равных условиях их эффективность выше вдали от экстремума и снижается по мере приближения к нему, так как падает вероятность выпадения удачных направлений.
Целесообразность применения случайного поиска возрастает с увеличением числа переменных, а при средней и большой размерности он становится практически безальтернативным. В отличие от методов, использующих производные, алгоритмы случайного поиска, как и прямые методы, могут применяться в условиях помех (погрешностей вычислений).