

Цифровые устройства и микропроцессоры
.pdf140
Рис. 63. Схема каскадирования КПДП
Для уменьшения времени передачи данных предусмотрена возможность выполнения циклов ПДП за два такта. В этом случае из цикла ПДП удаляются такты S1 и S3 на время изменения адреса по восьми младшим разрядам (А7–АО), которые формируются только при смене кода на старших разрядах А15–А8. Использование этой операции в режимах блочной передачи и передачи по требованию позволяет значительно сократить общее время передачи данных. Такая операция называется сжатием во времени.
Таблица 24
Программирование контроллера. Программирование контроллера осуществляется от ЦП командами ввода – вывода и возможно только в пассивном состоянии или при наличии на входе HLDA напряжения низкого уровня, если даже присутствует сигнал HRQ. Начальную инициализацию контроллера необходимо осуществить сразу же после включения напряжения питания по всем каналам, если даже они не используются, загружая команды и константы.

141
Таблица 25
Адреса внутренних регистров контроллера определяются кодом на выводах A3 – А0. В табл. 24 показаны коды на A3 – А0, соответствующие выполняемым командам ЦП, а в табл. 25 – коды на A3 –А0, соответствующие адресам регистров КПДП. Временные диаграммы работы КПДП в режиме взаимодействия с ЦП в цикле записи показаны на рис. 65. Так как константы всегда представлены 16-разрядным словом, их загрузка требует выполнения двух последовательных операций вывода с одинаковым кодом. Внутренний триггер управляет последовательностью ввода. Сначала загружается младший байт, затем старший.
Рис. 65. Временная диаграмма работы КПДП в цикле записи
Подключение контроллера к системной шине. Для уменьшения числа выводов на корпус БИС восемь старших разрядов адреса выдаются в такте S1
142
на выводы шины данных и должны быть «защелкнуты» на внешнем регистре БР, выходы которого подключаются к старшим разрядам шины адреса. Запись во внешний регистр осуществляется сигналом ADSTB. Линия AEN используется для того, чтобы разряды адреса оставались действующими на ША в течение трех тактовых периодов цикла ПДП. Линии А7 – АО подключаются непосредственно к ША. Сигналы MEMR, MEMW, IOR, IOW управляют в циклах ПДП соответственно ОЗУ и буфером внешнего устройства.
5.8. Арбитраж шин в многопроцессорных системах
По мере уменьшения отношения стоимость/производительность однокристальных процессоров становится более экономичным применять несколько процессоров вместо одного сложного многокристального. Кроме улучшения экономических показателей системы, мультипроцессорная конфигурация обеспечивает несколько положительных качеств, которых нет в однопроцессорной системе. Во-первых, несколько процессоров лучше приспосабливаются под требования конкретного применения, исключая расходы на ненужные возможности централизованной системы. Более того, модульность мультипроцессорной системы позволяет по мере необходимости вводить дополнительные процессоры. Во-вторых, в мультипроцессорной системе задачи разделяются между модулями, и при возникновении отказа проще найти и заменить неисправный процессор, чем отыскать неисправный элемент. В мультипроцессорной среде необходимо управлять обращениями к разделённому ресурсу, в ней невозможно непосредственно подключить два или более микропроцессора 8086 или 8088. В такой системе каждый микропроцессор имеет свою логику управления шиной, а арбитраж шины достигается путём расширения этой логики и введения общей для всех ведущих модулей внешней логики. Более подробно этот материал будет рассмотрен в последующих главах.
Лекция № 18
6.РЕАЛИЗАЦИЯ МУЛЬТИПРОЦЕССОРНЫХ СИСТЕМ
6.1.Организация мультипроцессорных систем в сильно связанных и слабо связанных конфигурациях
6.1.1. Общие сведения Мультипроцессорная система содержит два или более процессоров,
поскольку часто экономичнее применение нескольких процессоров вместо одного сложного. Можно отметить ещё ряд положительных факторов:
несколько процессоров лучше приспосабливаются под требования конкретного применения, исключаются расходы на ненужные возможности централизованной системы;
143
в мультипроцессорной системе задачи разделяются между модулями. При возникновении отказа проще и дешевле найти и заменить неисправный процессор, чем отыскивать и заменять отказавший элемент в сложной процессорной системе.
При проектировании мультипроцессорных систем приходится решать две задачи:
состязание за доступ к шине; межпроцессорные взаимодействия.
В связи с тем, что память и устройство ввода-вывода по общей системной шине используют несколько процессоров, потребуется дополнительная логика управления шиной.
Для реализации мультипроцессорных систем используется максимальный режим работы МП, при этом различают три базовые конфигурации: сопроцессор, сильно связанная конфигурация,
слабо связанная конфигурация.
Первые две очень похожи друг на друга, структурная схема сопроцессорной и сильно связанной конфигурации представлена на рис. 66. в этом случае МП 8086/8088 является ведущим, а вспомогательный микропроцессор
Рис. 66. Сильно связанная конфигурация
или сопроцессор – ведомым. Оба процессора разделяют не только всю подсистему памяти и ввода-вывода, но и логику управления шиной и генератор синхронизации. Управление доступом к шине осуществляет центральный процессор. В рассматриваемых конфигурациях не может быть двух микропроцессоров 8086/8088.
Слабо связанные конфигурации применяют в средних и больших системах, в них системные ресурсы разделяют несколько модулей, а проблему состязаний при доступе к шине должна решать логика управления системной шиной. Структурная схема слабо связанной конфигурации представлена на
144
рис 70. Как показано на этом рисунке, каждый потенциальный ведущий шины работает независимо, и прямые связи между ними отсутствуют. Межпроцессорное взаимодействие осуществляется через разделённые ресурсы. Кроме них у каждого модуля могут быть свои память и устройства ввода-вывода. Процессоры в отдельных модулях могут одновременно обращаться к своим локальным подсистемам по локальным шинам и выполнять независимо друг от друга выборки команд и обращения к локальным данным, что повышает степень параллельности обработки.
6.1.2. Сопроцессорные конфигурации
Для эффективного решения некоторых сложных задач вычислительных возможностей МП 8086/8088 недостаточно. Например, микропроцессоры 8086/8088 не имеют команд арифметики с плавающей точкой, а сопроцессор 8087 легко реализует такие вычисления. Далее подробно рассматривается структурная схема арифметического сопроцессора, его взаимодействие с центральным процессором и система команд, поэтому в этом разделе рассмотрим эти вопросы кратко, чтобы иметь общую картину работы МП I8086/8088 и I8087 в сопроцессорной конфигурации.
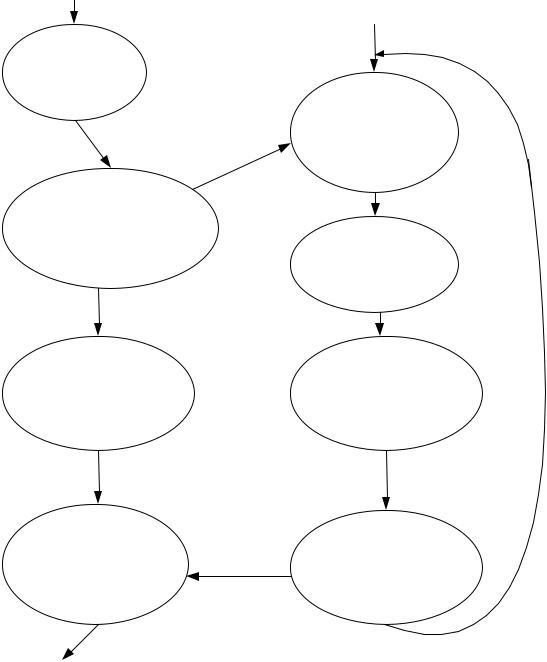
Система с арифметическим сопроцессором не требует никакой дополнительной логики, отличающейся от той, которая необходима в системе с максимальным режимом. Оба процессора выполняют команды из одной и той же программы. Взаимодействие между центральным МП и сопроцессором, когда команда выполняется сопроцессором, показано на рис 67. Центральный МП и сопроцессор выполняют свои команды из одной и той же программы. Если команда выполняется сопроцессором, центральный МП может подключиться для считывания требуемого операнда. Предназначенная для сопроцессора команда определяется появлением в программе одной из команд ESC. Мнемоника команд ESC имеет два формата, показанных на рис. 68, но любая команда сопроцессора содержит в первом байте код 11011.
Сопроцессор постоянно контролирует состояние очереди команд центрального процессора по линиям QS0, QS1, отслеживая комбинацию 01(т. е. «первый байт команды взят из очереди»). При совпадении этих двух факторов сопроцессор приступает к выполнению команды. Команда ESC одновременно дешифрируется сопроцессором и центральным процессором. В этой точке центральный МП может просто перейти к следующей команде или считать первое слово из памяти как операнд для сопроцессора, а затем перейти к следующей команде. Если центральный процессор считывает первое слово операнда, сопроцессор перехватывает слово данных и его 20-битный адрес. Когда операнд источник длиннее одного слова, сопроцессор получает остальные слова посредством запросов циклов шины по линии RQ/GT0 или RQ/GT1. если же определённый в команде ESC операнд является получателем, сопроцессор запоминает результат по перехваченному адресу. Сопроцессор выполняет действия, послав центральному МП на вход TEST сигнал

145
занятости (уровень логической единицы) и освободив шину. В это время центральный МП может выполнять свою программу. Такая параллельная работа продолжается до тех пор, пока центральному МП не понадобится результат текущей операции. При этом центральный МП должен выполнить команду WAIT и ожидать, пока сопроцессор не выдаст активный сигнал (уровень логической единицы) на вход TEST. Команда WAIT периодически проверяет вход TEST и, когда он становится активным, осуществляет передачу управления находящейся за ней команде.
К одному центральному МП допускается подключать два сопроцессора, один из них подсоединяется к линии RQ/GTO, а другой – к RQ/GT1.
При возникновении ошибки в процессе дешифрирования и выполнения команды ESC сопроцессор формирует запрос прерывания INT, который обычно подаётся в контроллер прерывания I8259A.
Когда к центральному МП подключены сопроцессор и независимый процессор ввода-вывода, который выбирает свои команды, сопроцессор должен определить, выбирается команда независимым процессором или центральным МП, иначе сопроцессор может ошибочно модифицировать свою
|
Сопроцессор |
|
|
Активизировать |
|
ESC |
сопроцессор |
Контролировать |
|
8086 или 8088 |
|
|
|
|
|
Подать пассивный сигнал |
Выполнить команды |
на вход TEST главного |
8086 |
процессора и выполнить |
|
указанную команду |
WAIT |
Активизировать |
Выдать активный |
|
сигнал на вход |
|||
|
|||
|
8086 или 8088 |
TEST |
|
|
|
Рис. 67. Синхронизация микропроцессора 8086 с его сопроцессором
очередь команд. Для этого сопроцессор контролирует бит состояния ST6 - микропроцессоры I8086/8088 всегда выводят низкий уровень, а процессор ввода-вывода I8089 – высокий уровень.
146
11011 |
|
|
|
|
MOD |
|
|
|
|
R/M |
|
Младшее |
|
Старшее |
||||||
|
|
|
|
|
|
|
|
|
|
DISP |
|
DISP |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Код внешней операции |
|
|
|
|
Необязательное смещение, |
|||||||||||||
|
|
|
|
|
|
зависящее от полей MOD и R/M |
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
а) |
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
11011 |
|
|
|
|
|
|
|
11 |
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Код внешней операции
Рис.68. Форматы машинного кода команды ESC, когда операнд находится в памяти(а) и не находится (б).
6.1.3.Сильно связанные конфигурации
Всильно связанных конфигурациях в качестве независимого процессора выступает процессор ввода-вывода I8289. независимый процессор в отличие от сопроцессора выполняет свой командный поток. В этой конфигурации, так же как и при работе с сопроцессором, оба процессора разделяют генератор синхронизации и логику управления шиной.
Вместо специальных команд ESC и WAIT взаимодействие между центральным МП и независимым осуществляется через разделённое пространство памяти. На рис. 69 представлен алгоритм межпроцессорного взаимодействия через разделенную память. Центральный МП I8086/88 формирует сообщение
впамяти и активизирует независимый процессор, посылая приказ в один из его портов. Затем процессор ввода-вывода обращается к разделённой памяти, получает оттуда свою задачу и выполняет её параллельно с центральным МП. О завершении задачи независимый процессор сообщает цен тральному МП с помощью бита состояния или запроса прерывания. При выполнении своей программы независимый процессор запрашивает шину по линии RQ/GT. Когда один процессор использует шину, другой переводит свои шины и выходы состояния в высокоимпедансное состояние. Так как микропроцессоры имеют две линии RQ/GT, то к центральному МП можно подключить два независимых процессора.
147
Независимый процессор
Сформировать
сообщение
|
Ожидать запроса |
Активизировать |
|
независимый |
|
процессор командой |
|
OUT |
Считать сообщение |
|
Выполнять |
|
программную |
Выполнить |
последовательность |
указанную задачу |
8086 |
|
Ожидать готовности |
Известить |
ЦП |
|
или запроса |
о завершении |
прерывания |
|
Рис.69. Межпроцессорные взаимодействия через разделённую память
Лекция № 19
6.1.4. Модульная организация в слабо связанных конфигурациях
В слабо связанных конфигурациях используется несколько «равносильных» МП I8086/88. Такая структура представлена на рис. 70. Все процессоры системы, находящиеся в процессорных модулях, взаимодействуют друг с другом и разделяют ресурсы через системную шину. Каждый центральный МП имеет свою логику управления шиной, а арбитраж шины дос-
148
тигается путём расширения этой логики и введения общей для всех ведущих модулей внешней логики. К каждому центральному МП можно подключить независимый процессор или сопроцессор. Слабо связанная конфигурация обладает рядом достоинств: повышенная пропускная способность системы, отдельные модули можно добавлять или удалять, не влияя на работоспособность всей системы, отказавший модуль можно легко заменить, поскольку каждый центральный МП имеет свою локальную шину, достигается высокая степень параллельной обработки, в слабо связанной конфигурации обязательным для каждого МП является наличие в модуле своего контроллера и арбитра шины. В любой момент времени системной шиной управляет только один модуль, поэтому необходима специальная схема арбитража. Одновременные запросы шины учитываются на приоритетной основе. При нескольких одновременных запросах учитываются приоритеты процессоров. Получив разрешение, процессор с наибольшим приоритетом реализует требуемый ему цикл шины и либо освобождает шину, либо ожидает приказа освободить её.
Применение арбитров шины позволяет реализовать или последовательный способ получения приоритета (приоритетная цепочка) или параллельный (независимое запрашивание). Способ приоритетной цепочки прост: если сигнал занятости системной шины пассивен, сигнал разрешения пассивно проходит через все ведущие модули до тех пор, пока не встречается первый модуль, запрашивающий доступ к шине. Этот модуль блокирует распространение сигнала разрешения шины, формируя сигнал занятости шины, и получает управление шиной. В этом случае приоритет определяется физическим размещением модулей. Недостатками такого способа являются большое время арбитража и меньшая надёжность, так как отказ одного модуля приводит к выходу из строя всей системы.
В способе независимых запросов приоритеты учитываются параллельно. Каждый модуль имеет отдельную пару линий запроса и разрешения шины со своим присвоенным приоритетом. Дешифратор приоритетов выбирает запрос с максимальным приоритетом и подаёт соответствующий сигнал разрешения шины. Арбитраж реализуется очень быстро и не зависит от числа модулей.
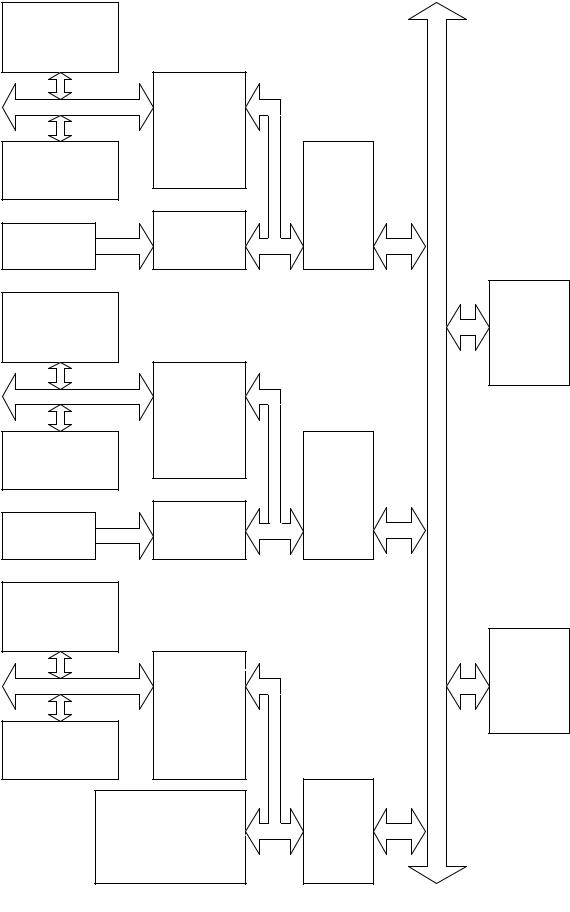
Локальные
устройства ввода-вывода
Локальная шина
Локальная
память
Генератор
синхронизации
Локальные
устройства ввода-вывода
Локальная шина
Локальная
память
Генератор
синхронизации
Локальные
устройства ввода-вывода
Локальная шина
Локальная
память
149
Логика
управления
локальной
шиной
8086/8088
Логика
управления
локальной
шиной
8086/8088
Логика
управления
локальной
шиной
Сильно связанный мультипроцессорный модуль
Логика
управле
ния
системной
шиной
Логика
управле
ния
системной
шиной
Логика
управле
ния
системной
шиной
Системная шина
Системная
память
Системные
устройства вводавывода
Рис.70. Слабо связанные конфигурации