

Связанные списки
Вторым элементарным типом данных, который мы рассмотрим, будут связанные списки, которые определены как примитивы в некоторых языках программирования (в частности в Лиспе), но не в Паскале. Однако Паскаль предоставляет некоторые базовые операции, позволяющие легко использовать связанные списки.
Главное преимущество связанных списков перед массивами состоит в том, что они могут уменьшать или увеличивать свои размеры во время выполнения программы. В частности, мы не должны заранее знать его максимальный размер. На практике, это позволяет иметь несколько структур данных, находящихся в одной области памяти, не обращая никакого внимания на их относительные размеры. Второе преимущество состоит в том, что они обеспечивают гибкость при переорганизации их элементов.
Оба преимущества получаются за счет потери скорости доступа к произвольному элементу списка. Это станет более очевидным ниже, после того, как мы познакомимся с некоторыми основными свойствами связанных списков и базовыми операциями, определенными над ними.
Связанный список это, так же как и массив, набор последовательно организованных данных. В массиве последовательная организация обеспечивается непосредственно (согласно индексу). Для связанного же списка, мы используем специальный способ организации данных, согласно которому, его элемент содержится в узле, который кроме элемента содержит такжессылкуна следующий узел. На Error: Reference source not foundпоказан связанный список, на котором элементы изображены буквами, узлы кружочками, и ссылки линями, соединяющими узлы. Ниже, мы более детально рассмотрим, как списки представляются в компьютере; пока же, мы обсудим их в терминах узлов и ссылок.
Выделение Памяти
Паскалевские указатели предоставляют нам удобный способ организации связанных списков, но существуют и другие способы. Как было замечено ранее, массивы являются довольно точным подобием памяти компьютера, поэтому анализ того, каким образом можно реализовать ту или иную структуру данных, используя массивы, даст нам некоторое представление о том, как реализуется подобная структура на низком, машинном уровне. В частности, нас интересует, как можно создать одновременно несколько списков в одном массиве, что является аналогом создания нескольких списков в памяти.
В прямом представлении связанных списков на массивах мы будем использовать индексы вместо указателей. Самым простым подходом к решению этой задачи, было бы завести массив записей, как мы это делали выше, но только использовать индексы массива в качестве ссылки на следующий элемент вместо использования указателей. Однако более удобным во многих случаях является использование “параллельных массивов”: мы храним данныесписка в массиве key[1..N], ассылкина следующий элемент – в массиве next[1..N]. Таким образом, key[next[head]] дает нам первый элемент списка, key[next[next[head]]] – второй, и так далее. Преимущество подобного подхода заключается в том, что вся структура может быть построена поверх данных: массивkeyсодержит только данные, в то время как вся структура списка содержится в массиве next. Во-первых, это позволяет иметь несколько независимых списков на одном массиве данных. Во-вторых, возможно один список применить к нескольким массивам данных.
Нижеследующий программный код показывает, как реализовать некоторые базисные операции, используя параллельные массивы:
varkey, next : array [1..N] of integer; x, head, z : integer;procedurelistInitizlize;beginhead := 0; z := 1; x := 1; next[head] := z; next[z] := z; {голова ссылается на хвост -> список пуст}end;
proceduredeleteNext(t : integer);beginnext[t] := next[next[t]];end;
procedureinsertAfter(v: integer; t : integer);beginx := x+1; key[x] := v; next[x] := netx[t]; next[t] := xend;
Указательx заменяет нам процедуру выделения динамической памятиnew: он указывает на следующую неиспользуемую позицию в массиве.
На Error: Reference source not found показано, как список из нашего примера может быть представлен в виде параллельных массивов, и как это представление связано с тем графическим представлением, которое мы до сих пор использовали. Массивы key и next показаны слева в том виде, в котором они предстали бы, если бы мы вставили в изначально пустой список SLAIT, где S, L и A вставлены после head, I после L, и T после S. Позиция 0 является началом списка, а позиция 1 его концом (это устанавливается при инициализации списка). Поэтому next[0]=4 – первый узел списка со значением key[4] (A); Так, как next[4]=3, то следующим (вторым) элементом будет key[3] (L), и так далее. На второй слева диаграмме индексы массива заменены линиями, вместо написания номера следующего элемента списка мы просто чертим линию, соединяющую его со следующим элементом. На третьей диаграмме мы “выпрямляем” список, и затем в последней, правой диаграмме мы просто используем обычное графическое представление связанного списка.
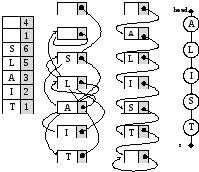
Реализация связанного списка при помощи массивов
Возвращаясь к аналогии с памятью компьютера, построим аналогию для динамического выделения и освобождения памяти. Операционная система поставлена в такое положение, что узлы хранятся в том же массиве (память – массив), что и ссылки. Итак, мы хотим реализовать встроенные процедуры newиdispose, исходя из того, что единственное место для хранения узлов и ссылок – это наши массивы.
Предположим, что нам нужно удалить узел A из примера на Error: Reference source not found, а затем освободить занятую им память. Переставить все указатели в списке так, чтобы узел больше не был частью списка – это одно, но что же нам делать с пространством, используемым этим узлом? И как нам найти место под новый узел, когда мы вызываем процедуру new? Для решения проблемы, мы можем использовать второй связанный список для хранения информации о неиспользуемом пространстве. Мы будем называть егосписок неиспользуемых элементов. Теперь, когда мыудаляем элемент из списка, мы освобождаем используемое им пространство, добавляя его к списку неиспользуемых элементов, а когда мы создаемновыйузел, – получаем место под него посредством удаления его из списка неиспользуемых элементов. Таким образом, речь идет о нескольких списках на одном массиве.
Простой пример с двумя списками (но без списка неиспользуемых элементов) изображен на Error: Reference source not found. В этом примере определены два узла-заголовка списков hd1 = 0 иhd2 = 6, но оба списка имеют один и тот же конечный узелz. (Для создания нескольких списков, процедура инициализацииlistInitializeдолжна быть изменена так, чтобы она могла управлять более чем одним заголовком списка.) Теперь,next[0] = 4, поэтому первый элемент нашего списка – этоkey[4] (O). Так, какnext[6]=7, то первый элемент второго списка –key[7] (T),и так далее. Следующая диаграмма показывает наши списки без использования параллельного массиваnext, заменяя его линиями соединяющими его узлы. На третьей показаны те же самые два списка, но уже «развернутые». Наконец на последней диаграмме изображены списки в привычной для нас графической форме, как на Error: Reference source not found.

Два списка содержащихся в одном массиве
Все описанное ранее предназначено для понимания того, как система управляет выделением ресурсов. На самом деле, проблема, с которой имеет дело система, более сложна. Дело в том, что узлы не обязаны быть одного размера. Некоторые системы освобождают пользователя от необходимости прямого вызова dispose для освобождения памяти посредством использования алгоритмовсборамусорадля удаления «потерянных» узлов. Если управление памятью предоставляется средой программирования, как в Паскале, то обычно не возникает причин создавать свой собственный диспетчер памяти.