

1 2 3 4 5 6 7
Здесь также длинная часть подмассива будет равна n-1, поэтому рекурсивный вызов потребуется n раз, что совершенно недопустимо, ввиду ограниченного размера стека. Как это не парадоксально, но алгоритм быстрой сортировки будет плохо работать в данном случае на упорядоченных массивах.
Понятно, что лучшим опорным элементом для массива является медиана, то есть значение, которое разобьет массив на две равные части. Однако поиск медианы может вызвать трудо- и времязатраты, сопоставимые с сортировкой массива.
Хоар предложил два способа улучшить выбор опорного элемента y:
выбирать случайным образом элемент массива,
искать медиану трех случайно взятых элементов массива (средний по величине).
Ахо предлагает выбирать у как наибольшее значение из двух первых элементов массива.
Запишем теперь общий алгоритм, рекурсивно вызывая процедуру сортировки:
procedureQuickSort(varx : vector);procedureSort( l, r : integer);Vari, j : integer; y, z: integer;begini := l; j := r; y := x[(l + r) div 2];repeatwhilex[i] < ydoi := i + 1;whilex[j] > ydoj := j – 1;ifi <= jthenbeginz := x[i]; x[i] := x[j]; x[j] := z; i := i + 1; j := j – 1end;untili > j;ifl < jthenSort (l, j);ifi < rthenSort(i, r)end;
beginSort(1, n)end; {quicksort}
Исключение рекурсии в этом алгоритме достигается использованием стека, в который запоминается запрос на сортировку одной из частей (для простоты – правой).
procedureQuickSort(varx : Vector);vari, j, l, r : integer; y, z: integer; S : Stack;beginPush(s, 1, n);repeatR := Pop(S); L := Pop(S);repeati := l; j := r; y := x[(l + r) div 2];repeatwhilex[i] < ydoi := i + 1;whilex[j] > ydoj := j – 1;ifi<=jthenbeginz := x[i]; x[i] := x[j]; x[j] := z i := i + 1; j := j – 1end;untili > j;ifi < rthenPush( S, i, r) r := j;untill >= r;untilEmpty(S);end; {quicksort}
В стеке было бы рациональнее хранить адрес самой длинной части и продолжать разбиение коротких частей. Этого легко добиться с помощью условия:
ifj – l < r – ithenbeginifi < rthenPush(S, i, r) r := j;endelse beginifl < jthenPush(S, l, j); l := i;end;
Еще один способ улучшения метода, заключается в использовании простых методов для разделенных подмассивов малой длины N. Например, приN= 9, рекомендуется использовать сортировку простой вставкой.
Алгоритм является самым полезным алгоритмом внутренней сортировки, так как требует мало памяти и опережает другие алгоритмы по среднему времени выполнения.
Характеристики
алгоритма «быстрой сортировки» зависят
от удачного выбора элемента Yдля разбиения. В хорошем случае число
сравнений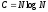 ,
,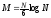 .
Таким образом, быстрая сортировка
эффективна лишь в среднем – время работы
пропорционально
.
Таким образом, быстрая сортировка
эффективна лишь в среднем – время работы
пропорционально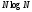 ,
в худшем случае она может работать очень
медленно, пропорционально
,
в худшем случае она может работать очень
медленно, пропорционально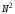 .
Быстрая сортировка не является устойчивой,
в отличии, например от простых вставок,
слияния списков, простого выбора.
.
Быстрая сортировка не является устойчивой,
в отличии, например от простых вставок,
слияния списков, простого выбора.
25. Критерии эффективности алгоритмов (формирование, поиск последовательного масиива)
26. Критерии эффективности алгоритма ступенчетого поиска
27. Сортировка методом Шелла Сортировка Шелла
Сортировка вставкой работает медленно потому, что она обменивает только смежные элементы. Оболочечная сортировка является простейшим расширением сортировки вставкой, которая увеличивает скорость работы алгоритма за счет того, что позволяет обменивать элементы находящиеся далеко друг от друга.
Основная идея алгоритма состоит в том, чтобы отсортировать все группы файла состоящие из элементов файла отстоящих друг от друга на расстояние h. Такие файлы называются h-сортированными. Когда мы h-сортируем файл по некоторому большому h, мы передвигаем его элементы на большие растояния. Это облегчает работу сортировки для меньших значений h. Процесс заканчивается когда h уменьшается до 1.
рисунок 7
Оболочечная Сортировка
На рисунке 7 показано, как сортировка Шелла обрабатывает файл с шагом в ..., 13, 4, 1. Серым фоном обозначается сортируемый на данном шаге подфайл.
Приведенная программа использует последовательность ... 1093, 364, 121, 40, 13, 4, 1. Могут существовать и другие последовательности – одни лучше, другие хуже.
Свойство 6 Оболочечная сортировка никогда не делает более чем N1.5 сравнений для вышеуказанной последовательности h.