

Теория Информации - Методичка (1 семестр)
.pdf4. Какой код называется оптимальным?
а) код с максимальной средней |
в) код с минимальной средней |
длиной |
длиной |
б) однозначно декодируемый код |
г) однозначно декодируемый |
с максимальной средней длиной |
код с минимальной средней дли- |
|
ной |
Вариант 3
1. Дан трехсимвольный алфавит со следующими вероятностями появления символов: р(а)=0,73; р(b)=0,25; р(с)=0,02. Для дан-
ного алфавита построен следующий код: 00, |
01, 10. Чему равна |
||
средняя длина кодовых слов? |
|
|
|
а) 1/3; |
б) 2; |
в) 0,423; |
г) 1,3 |
2. Дан трехсимвольный алфавит со следующими вероятностями появления символов : р(а)=0,73; р(b)=0,25; р(с)=0,02. Для данного алфавита построены следующие шесть вариантов кодов:
код 1: 00, 00, 01; |
код 2: 00, 01, 10; |
код 3: 0, 1, 11; |
код 4: 1, 10, 100; |
код 5: 1, 00, 01; |
код 6: 1, 01, 11. |
Какие из этих кодов обладают свойством отсутствия пре-
фикса? |
|
|
а) код 1, |
код 2, код 5 |
в) код 2, код 4 |
б) код 2, |
код 5 |
г) таких кодов нет |
3. Выберите верные характеристики кода, заданного множеством кодовых слов {0, 10, 111, 110}.
а) префиксный код фиксирован- |
в) непрефиксный код фиксиро- |
ной длины |
ванной длины |
б) префиксный код переменной |
г) непрефиксный код перемен- |
длины |
ной длины |
4. В чем состоит основная задача кодера источника? |
|
а) сжатие информации |
в) встраивание помехоустойчи- |
|
вой защиты |
б) разархивирование данных |
г) исправление ошибок |
49
3.АЛГОРИТМЫ СЖАТИЯ ДАННЫХ
Вданной главе изложены общие идеи минимизации объема информации, приведены примеры алгоритмов сжатия, а также реальные примеры использования таких алгоритмов на практике и дано представление о критериях подбора алгоритма сжатия в зависимости от параметров исходных данных.
Ключевые слова: сжатие данных; избыточная, несущественная информация; сжатие с потерями и без потерь; коды сжатия; префиксные коды; коды фиксированной и переменной длины; примеры алгоритмов сжатия с потерями и без потерь; алгоритм Хаффмана; алгоритмы Лемпеля–Зива.
У термина «сжатие данных» есть много синонимов, например, упаковка данных, компрессия, сжимающее кодирование, кодирование источника. Обратная процедура называется восстановлением данных, распаковкой или декомпрессией. Согласно классической схеме системы связи (см. гл. 1), сжатие данных, т.е. более компактное их представление производится в кодере источника, а задачей декодера источника является, соответственно, восстановление сжатых данных.
Сжатие данных (англ. data compression) – алгоритмическое преобразование данных, производимое в целях уменьшения их объема.
Архиватор – это специальная программа, при помощи которой можно кодировать кодами сжатия (сжимать, архивировать) файлы (папки с файлами) и доставать их из архива.
3.1. Задача сжатия данных
Рассмотрим неформальное описание задачи сжатия. Представьте, что Вы собираетесь в долгожданный отпуск. И вот перед Вами, с одной стороны, большая куча вещей, которые Вы планируете взять с собой, а с другой – чемодан, размер которого заметно меньше размера кучи вещей. Как сложить все «нужное» в этот чемодан?
50

Есть два основных варианта: можно более критично пересмотреть вещи и отложить ненужные, те которые, скорее всего, Вам не понадобятся. А можно более плотно сложить имеющиеся вещи, так, чтобы они занимали меньше места и поместились бы в чемодан.
Рассмотренная ситуация наглядно описывает принципы организации двух основных классов методов сжатия: сжатие с потерями и сжатие без потерь.
В случае использования алгоритмов сжатия без потерь возможно полное восстановление исходных данных, а сжатие с потерями позволяет восстановить данные с искажениями, с потерей некоторой информации. Эту информацию обычно называют несущественной с точки зрения дальнейшего использования.
Несущественная информация – это информация, которой можно пренебречь при передаче.
Рассмотрим примеры несущественной информации.
Пример 3.1. Человеческий голос состоит из множества гармоник, а телефонная связь использует полосу частот в диапазоне около 4 кГц. Все остальные спектральные составляющие речи отбрасываются, при этом существенная часть информации теряется. Однако оставшегося сигнала вполне достаточно, чтобы сохранить речь разборчивой и оставить голос собеседника узнаваемым. Ясно, что после прохождения по телефонной линии первоначальный сигнал не может быть восстановлен полностью. 
Пример 3.2. Еще одним часто используемым методом сжатия с потерями является преобразование графических файлов формата bmp в формат jpeg. Качество
файла в jpeg хуже качества исходного файла, однако это ухудшение не видно человеческому глазу. 
Пример 3.3. Не так много лет тому назад, в эпоху отсутствия
сотовых телефонов, люди активно общались с помощью телеграфа и отправляли друг другу телеграммы. Сумма оплаты за отправку телеграммы зависела от количества использованных слов. Чтобы сэко-
51
номить, отправители телеграммы выкидывали из текста незначащие слова. Например, вместо фразы «Прилетаю в среду, шестого февраля. Встретьте меня, пожалуйста.», содержащей 12 слов (с учетом знаков препинания), отправитель, скорее всего, написал бы примерно так: «Прилетаю шестого встречайте» (3 слова). Выгода от такого сжатия очевидна. 
Избыточная информация – неоднократное повторение в сообщении необходимой для приемника информации. Избыточность может быть устранена без потери информации. Если алгоритм кодирования отбрасывает только избыточную информацию, то говорят о кодировании без потерь.
Пример 3.4. Все человеческие языки избыточны. В языке есть много элементов, несущих повторную информацию, т.е. информацию уже переданную другими элементами языка. Так, в русском языке избыточными можно назвать большинство сдвоенных букв, повторные указания на род, число, падеж взаимосвязанных слов, в появлении букв, пар последовательных букв, троек и т. д. имеются явные статистические закономерности. Существует несколько гипотез причин избыточности языков. Одна из них – необходимость повышения надежности передачи сообщений, так как люди общаются обычно в зашумленной среде. По сделанным расчетам избыточность основных европейских языков составляет
70–85 %. 
Общая идея сжатия без потерь состоит в том, что в исходных данных находят какую-либо закономерность и с ее учетом генерируют вторую последовательность, которая полностью описывает исходную. Примеры такого кодирования будут рассмотрены ниже.
На рис. 3.1 перечислены некоторые примеры конкретных алгоритмов сжатия. Заметим, что нами будут рассмотрены только алгоритмы кодирования без потерь, так как в случае кодирования с потерями необходимо учитывать формат входных данных, что усложняет изучение конкретных методов. Сжатие с потерями в основном используется для таких данных, как полноцветная графика, звук и видео и обычно проводится в два этапа. На первом из них ис-
52
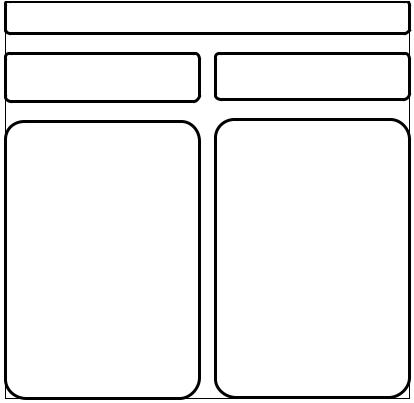
ходная информация приводится (с потерями) к виду, в котором ее можно эффективно сжимать алгоритмами второго этапа – сжатия без потерь.
Алгоритмы сжатия
С потерей |
Без потерь |
(отбрасывается несущественная информация)
Алгоритмы: фрактальный, волновой.
Кодеки
аудио: MP3 , Ogg Vorbis (отличается отсутствием патентных ограничений и высоким качеством), AAC, AAC+ –
существует в нескольких вариантах, используется,
например, в Apple, WMA;
графические: снижение глубины цвета, метод главных компонентов, JPEG, DjVu;
видео: Motion JPEG, Flash, H.261, MPEG-1, MPEG-2, MPEG-4, VC-1 –
открытая спецификация для формата WMV.
(отбрасывается избыточная информация)
Алгоритмы: Хаффмана,
Лемпеля–Зива.
Кодеки
Многоцелевые: LZW –
используется в gif и во многих других, LZMA – используется в 7- zip;
аудио: WavPack, Dolby TrueHD;
графические: GIF – (без потерь только для изображений, содержащих не более 256 цветов), JPEG 2000 – (в режиме сжатия без потерь), PNG;
видео: CamStudio Video Codec, CorePNG, SheerVideo, WMC – Wavelet Media Codec, Motion JPEG 2000. .
Рис. 3.1. Примеры конкретных алгоритмов сжатия
Очевидно, что коды сжатия можно классифицировать и по другим признакам. Так, часто рассматривают коды сжатия фиксированной и переменной длины, префиксные и непрефиксные коды. Рассмотрим конкретные примеры алгоритмов сжатия данных.
53

3.2. Алгоритм Хаффмана
Алгоритм Хаффмана был разработан Дэвидом Хаффманом (David Huffman) в 1952 г. На вход алгоритма поступает алфавит с известными вероятностями появления символов. Алгоритм строит для входных символов кодовые слова из другого алфавита заданной мощности. При этом символам с большей вероятностью ставятся в соответствие короткие кодовые слова, а редко встречающимся символам ставятся в соответствие кодовые слова большей длины. Алгоритм Хаффмана – это алгоритм сжатия без потерь.
Коды, построенные с помощью алгоритма Хаффмана, являются префиксными кодами переменной длины, с минимально возможной средней длиной кодового
Существует понятие иде- |
слова. Заметим, что самая короткая |
|
ального сжатия, т. е. сжатия |
||
средняя длина кода для конкретного |
||
до энтропии. Если вероятно- |
||
сти символов входного ал- |
алфавита может быть значительно |
|
фавита точно равны отрица- |
больше энтропии алфавита источни- |
|
тельным степеням числа 2, то |
||
ка. Алгоритм кодирования Хаффма- |
||
метод Хаффмана производит |
||
идеальное сжатие. |
на может применяться для преобра- |
|
|
зования между двумя любыми алфа- |
витами, чаще всего его используют для преобразования произвольного алфавита в двоичный.
В процедурах кодирования и декодирования кодом Хаффмана можно выделить два этапа. Первый – построение кодовых слов, а второй – кодирование или декодирование. Алгоритм построения кодовых слов основан на построении кодового дерева. Кодирование состоит в последовательной замене символов исходного сообщения на соответствующие им кодовые слова. Декодирование заключается в последовательной замене кодовых слов на соответствующие им символы исходного алфавита.
Рассмотрим алгоритм построения кодовых слов кода Хафф-
мана.
Входные данные: мощность кодового алфавита q, входной алфавит А={a1, a2, …, am} с соответствующими ему вероятностями появления символов p(ai).
Выходные данные: кодовые слова, построенные из алфавита мощности q.
54
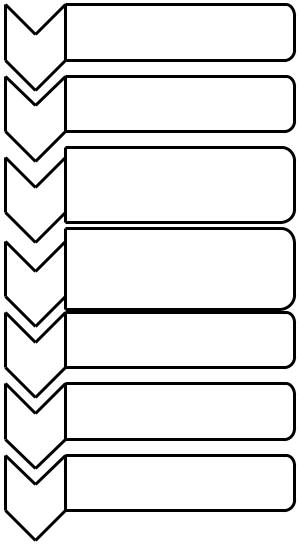
Шаги алгоритма представлены на рис. 3.2.
Шаг 1
Шаг 2
Шаг 3
•Упорядочим символы входного алфавита по убыванию вероятности их появления.
•Поставим в соответствие каждый символ узлу q-ичного дерева.
•Выбираем q узлов (листьев) с наименьшими вероятностями.
•Объединим выбранные элементы в новый узел.
•Поставим в соответствие вновь образованному узлу сумму вероятностей объединенных ветвей.
Шаг 4
Шаг 5
Шаг 6
Шаг 7
•Новый узел добавляем в список свободных узлов, а элементы из которых он образован (q потомков этого узла), удаляем из этого списка.
•Пометим ребра, выходящие из вновь образованного узла символами от 0 до q–1.
•Вновь упорядочим ветви дерева в порядке убывания вероятности их появления.
•Повторим шаги 2–5 до появления корня дерева с соответствующей ему вероятностью, равной единице.
•Двигаясь от корня дерева к каждому листу поочередно будем записывать метки ребер, составляя таким образом кодовые слова.
Рис. 3.2. Алгоритм Хаффмана построения кодовых слов
55

Рассмотрим работу алгоритма Хаффмана на примере. Пример 3.5. Построить двоичный код Хаффмана для пред-
ставленного в таблице алфавита. В таблице использованы следующие обозначения Аi – i-й символ алфавита, Р(Аi) – вероятность появления символа Аi.
Аi |
а |
b |
с |
D |
Р(Аi) |
0,12 |
0,3 |
0,38 |
0,2 |
Упорядочим символы алфавита по убыванию вероятностей их появления и поставим их в соответствие ветвям двоичного дерева (далее при построении дерева расположим его горизонтально, так чтобы листья дерева находились слева, а его корень – справа).
с0,38
b 0,3
d 0,2
a 0,12
Два входа с самой низкой относительной частотой объединим в новую ветвь. Вероятность, соответствующую этой ветви, вычислим как сумму вероятностей объединенных ветвей. После объединения переупорядочим все ветви дерева таким образом, чтобы в дереве сохранялась убывающая вероятность ветвей. В случае, когда необходимо построить выходной алфавит не двоичным, а например q-ичным, то необходимо объединять ветви дерева по q штук, которым соответствуют наименьшие значения вероятностей. Для определенности, далее будем считать, что если вероятность вновь образованной ветви совпадает с вероятностью другой ветви, то новую ветвь будем «поднимать» выше ветви с такой же вероятностью.
с |
0,38 |
|
0,38 |
|
|
|
|||
|
|
|||
b |
0,3 |
|
0,32 |
|
d |
0,2 |
0,3 |
||
a |
0,12 |
|||
|
|
|||
56
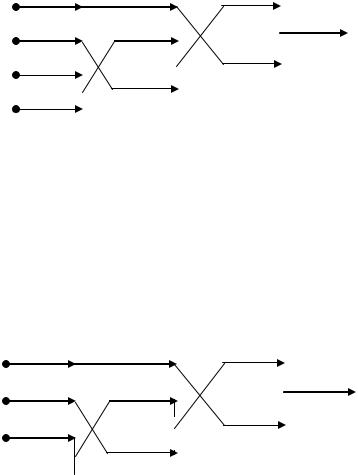
Будем продолжать этот процесс до достижения корня дерева.
с |
0,38 |
|
0,38 |
|
|
|
|
0,62 |
|
||
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
b |
0,3 |
|
0,32 |
|
|
|
|
|
|||
|
|
|
|
||
d |
0,2 |
|
|
|
|
|
|
0,38 |
|
||
|
0,3 |
|
|
||
a |
0,12 |
|
|
|
|
|
|
|
|
||
|
|
|
|
||
|
|
|
|
||
|
|
|
|
||
|
|
|
|
|
|
После формирования (или во время формирования) всего дерева пометим ветви, выходящие из всех вершин символами «0» и «1». Помечать ветви дерева можно произвольным образом: для определенности ветвь, идущую вверх, будем помечать символом «1», а ветвь, идущую вниз – символом «0».
После обозначения вершин, пройдем все возможные пути по дереву от вершины (крайнее правое положение) дерева до его каждой выходной ветви (крайнее левой положение), запоминая встретившиеся двоичные символы. Полученные последовательности будут являться кодами символов входного алфавита.
|
|
0,38 |
|
|
с |
0,38 |
|
0,62 |
1 |
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
b |
0,3 |
0,32 |
|
|
|
|
|||
|
1 |
|
||
|
|
|
|
|
|
|
|
0,38 |
|
|
|
|
|
|
d |
0,2 |
|
|
0 |
|
1 |
0,3 |
|
|
0
a 0,12
 0
0
Значения, характеризующие построенный код Хаффмана, сведем в таблицу следующего вида. В первом столбце перечислим все символы алфавита Аi; во втором столбце расположим соответ-
57

ствующие вероятности появления символов входного алфавита рi; в третьем столбце запишем кодовые слова, соответствующие символам входного алфавита; в последнем – четвертом столбце поместим
значения ni |
ði . |
|
|
|
|
|
|
|
|
|
|
Аi |
|
pi |
Код |
Длина кода ni , бит |
ni ði |
|
|
|
|
|
|
с |
|
0,38 |
0 |
1 |
0,38 |
|
|
|
|
|
|
b |
|
0,30 |
10 |
2 |
0,60 |
|
|
|
|
|
|
d |
|
0,20 |
111 |
3 |
0,60 |
|
|
|
|
|
|
a |
|
0,12 |
110 |
3 |
0,36 |
|
|
|
|
|
|
Среднюю длину кода вычислим по формуле:
4
nni ði .
i1
Заметим, что результирующее значение n =1,94 бит на знак, что не означает, что для передачи одного символа необходимо передавать нецелое число бит, а означает, что для передачи 100 входных символов из алфавита мощностью 4 потребуется примерно 194 бит.
Итак, построен двоичный код Хаффмана и теперь его можно использовать для кодирования или декодирования источника. 
Пример 3.6. Используем код Хаффмана, построенный в примере 3.5, и закодируем последовательность abcd: 110100111 
Алгоритм Хаффмана существует более 60 лет. Является ли он реально используемым или уже перешел в разряд только учебных примеров? Простота этого алгоритма, его эффективность, а также окончившийся срок патентов обеспечили ему широкое распространение. Алгоритм Хаффмана используется по настоящее время, однако не применяется в «чистом» виде, а используется в составе других, более сложных алгоритмов. Так, например, этот алгоритм используется на одной из стадий сжатия в формате jpeg, в архиваторах (PKZIP, ZIP, LZH), в протоколах передачи данных MNP5 и MNP7.
58