

ВОПРОСЫ ГОСУДАРСТВЕННОГО ЭКЗАМЕНА
.pdf111
К оглавлению ↑
Наконец, KA(y) = KA(y|1) можно считать просто «сложностью объекта y» и определить «количество информации в x относительно y» формулой
Легко доказать (Выбирая в виде функции сравнения φ(p,x)=A(p,1), получим KA(y|x)≤Kφ(y|x)+Cφ=KA(y)+Cφ), что величина эта всегда в существенном положительна:
что понимается в том смысле, что IA(x:y) не меньше некоторой отрицательной константы C, зависящей лишь от условностей избранного метода программирования. Как уже говорилось, вся теория рассчитана на применение к большим количествам информации, по сравнению с которым |C| будет пренебрежимо мал.
Наконец, KA(x|x)≈0, IA(x:x)≈0;KA(x).
Конечно, можно избегнуть неопределенностей, связанных с константами Cφ и т. д., остановившись на определенных областях объектов X, их нумерации и функции A, но сомнительно, чтобы это можно было сделать без явного произвола. Следует, однако, думать, что различные представляющиеся здесь «разумные» варианты будут приводить к оценкам «сложностей», расходящимся на сотни, а не на десятки тысяч бит. Поэтому такие величины, как «сложность» текста романа «Война и мир», можно считать определенными с практической однозначностью. Эксперименты по угадыванию продолжений литературных текстов позволяют оценить сверху условную сложность при заданном запасе «априорной информации» (о языке, стиле, содержании текста), которой располагает угадывающий. В опытах, проводившихся на кафедре теории вероятностей Московского государственного университета, такие оценки сверху колебались между 0,9 и 1,4. Оценки порядка 0,9-1,1, получившиеся у Н. Г. Рычковой, вызвали у менее удачливых угадчиков разговоры о ее телепатической связи с авторами текстов.
Я думаю, что для «количества наследственной информации» предполагаемый подход дает в принципе правильное определение самого понятия, как бы ни была трудна фактическая оценка этого количества.
Количество информации, приходящиеся на одно сообщение.
1 Количество информации в сообщении (элементе сообщения) определяется по формуле
I = - log2 P,
где Р - вероятность появления сообщения (элемента сообщения). Из этой формулы следует, что единица измерения количества информации есть количество информации, содержащееся в одном бите двоичного кода при условии равной вероятности появления в нем 1 и 0. В то же время один разряд десятичного кода содержит I = - log2Р = 3,32 единицы информации (при том же условии равновероятности появления десятичных символов, т.е. при Р = 0,1).
Энтропия источника информации с независимыми сообщениями есть среднее арифметическое количеств информации сообщений
N
H = - е Pk log2 Pk k=1
где Pk - вероятность появления k-го сообщения. Другими словами, энтропия есть мера неопределенности ожидаемой информации.

112
К оглавлению ↑
П р и м е р. Пусть имеем два источника информации, один передает двоичный код с равновероятным появлением в нем 1 и 0, другой имеет вероятность 1, равную 2-10, и вероятность 0, равную 1-2-10. Очевидно, что неопределенность в получении в очередном такте символа 1 или 0 от первого источника выше, чем от второго. Это подтверждается количественно оценкой энтропии: у первого источника H = 1, у второго приблизительно H = -2-10 log22-10 , т.е. значительно меньше.
Коэффициент избыточности сообщения А определяется по формуле
r = (Imax - I)/Imax,
где I - количество информации в сообщении А, Imax - максимально возможное количество информации в сообщении той же длины, что и А.
Пример избыточности дают сообщения на естественных языках, так, у русского языка r находится в пределах 0,3...0,5.
Наличие избыточности позволяет ставить вопрос о сжатии информации без ее потери в передаваемых сообщениях.
2
Бит. Байт.
1 БИТ – такое кол-во информации, которое содержит сообщение, уменьшающее неопределенность знаний в два раза. БИТэто наименьшая единица измерения информации.
Бит — это очень маленькая единица, поэтому часто используется величина в 8 раз большая — байт (byte), состоящая из двух 4-битных полубайт или тетрад. Байт обычно обозначают заглавной буквой B или Б. Как и для прочих стандартных единиц измерения для бита и байта существуют производные от них единицы, образуемые при помощи приставок кило (K), мега (M), гига (G или Г), тера (T), пета (P или П) и других. Но для битов и байтов они означают не степени 10, а степени двойки: кило — 210 = 1024 _ 103, мега — 220 _ 106, гига — 230 _ 109, тера — 240 _ 1012, пета — 250 _ 1015. Например, 1 KB = 8 Кbit = 1024 B = 8192 bit, 1 МБ = 1024 КБ = 1 048 576 Б = 8192 Кбит.
Применение к русскому алфавиту.

113
К оглавлению ↑
Широко используются двоичные коды:
EBCDIC (Extended Binary Coded Decimal Interchange Code) - символы кодируются восемью битами;
популярен благодаря его использованию в IBM;
ASCII (American Standards Committee for Information Interchange) - семибитовый двоичный код.
Оба этих кода включают битовые комбинации для печатаемых символов и некоторых распространенных командных слов типа NUL, CR, ACK, NAK и др.
Для кодировки русского текста нужно вводить дополнительные битовые комбинации. Семибитовая кодировка здесь уже недостаточна. В восьмибитовой кодировке нужно под русские символы отводить двоичные комбинации, не занятые в общепринятом коде, чтобы сохранять неизменной кодировку латинских букв и других символов. Так возникли кодировка КОИ-8, затем при появлении персональных ЭВМ - альтернативная кодировка и при переходе к Windows - кодировка 1251. Множество используемых кодировок существенно усложняет проблему согласования почтовых программ в глобальных сетях.
Литература: [2], [3].
4. Кодирование
Алфавитное кодирование.
В общем случае задачу кодирования можно представить следующим образом. Пусть заданы два алфавита А и В, состоящие из конечного числа символов:
 и
и  . Элементы алфавита называются буквами. Упорядоченный набор в
. Элементы алфавита называются буквами. Упорядоченный набор в
алфавите А назовем словом |
,где |
, число п показывает |
количество букв в слове и называется длиной слова |
, обозначается п =l( )=| |.Пустое |
|
слово обозначается: |
|
|
Для слова |
|
буква a1, называется началом, или префиксом, слова |
, а буква an — |
окончанием, или постфиксом, слова  .
.
Неравенство Макмиллана.
Пусть заданы кодируемый и кодирующий алфавиты, состоящие из n и d символов,
соответственно, и заданы желаемые длины кодовых слов:  . Тогда необходимым и достаточным условием существования разделимого и префиксного кодов, обладающих заданным набором длин кодовых слов, является выполнение неравенства:
. Тогда необходимым и достаточным условием существования разделимого и префиксного кодов, обладающих заданным набором длин кодовых слов, является выполнение неравенства:
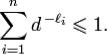
114
К оглавлению ↑
Пусть заданы два произвольных конечных множества, которые называются, соответственно, кодируемым алфавитом и кодирующим алфавитом. Их элементы называются символами, а строки символов — словами. Длина слова — это число символов, из которого оно состоит.
В качестве кодирующего алфавита часто рассматривается множество {0,1} — так называемый двоичный или бинарный алфавит.
конкатенацию кодовых слов, соответствующих каждому символу этого слова.
Код называется разделимым, если никаким двум словам кодируемого алфавита не может быть сопоставлен один и тот же код.
Префиксным кодом называется алфавитный код, в котором ни одно из кодовых слов не является префиксом никакого другого кодового слова. Любой префиксный код является разделимым.
Теоремы Шеннона (первая, обратная).
Если источник сообщения имеет энтропию Н бит/букву, а канал связи обладает пропускной способностью Сбит/сек, то всегда можно найти такой способ кодирования, который обеспечивает передачу букв по каналу со средней скоростью,
V ср=(С/Н-Е) букв /сек
Е – сколь угодно малая величина.
Обратная теорема. Передача букв по каналу со средней скоростью больше, чем С/Н невозможна, следовательно Vmax=С/Н
Минимизация длины кода сообщений.
Если задана разделимая схема алфавитного кодирования а — (а* —> i> т о любая схема а' = (а* -н• Р/)™=1, где последовательность (Р\,...,Р'п) является перестановкой последовательности (Pi,..., /5П), также будет разделимой. Если длины элементарных кодов равны, то перестановка элементарных кодов в схеме не влияет на длину кода сообщения. Но если длины элементарных кодов различны, то длииа кода сообщения зависит от состава букв в сообщении и от того, какие элементарные коды каким буквам назначены. Если заданы конкретное сообщение и конкретная схема кодирования, то нетрудно подобрать такую перестановку элементарных кодов, при которой длина кода сообщения будет минимальна. Пусть ki,..., kn — количества вхождений букв ai,..., ап в сообщение 6.2. Кодирование с минимальной избыточностью 215
s £ S, a li,... ,1п — длины элементарных кодов (3\,... ,0п соответственно. Тогда, если к{ ^ kj и li^ lj, то kiU + kjlj ^ kilj + kjU. Действительно, пусть kj = к + a, ki = к и lj = I, k = / + b, где a, b ^ 0.
Тогда (kilj + kjli) - (kih + kjlj) = (kl + (k + a)(l + b)) - (k(l + b) + l(k + a)) = = (kl + al + bk + ab + kl) - (kl + al + kl + bk) = ab ^ 0.
Отсюда вытекает алгоритм назначения элементарных кодов, при котором длина кода конкретного сообщения s е S будет минимальна: нужно отсортировать буквы сообщения s в порядке убывания количества вхождений, элементарные коды отсортировать в порядке возрастания длины и назначить коды буквам в этом порядке.
Алгоритмы Фено и Хаффмена.
Алгоритм Хаффмана — алгоритм оптимального префиксного кодирования алфавита. Это один из классических алгоритмов, известных с 60-х годов. Использует только частоту появления одинаковых байт в изображении. Сопоставляет символам входного потока, которые встречаются большее число раз, цепочку бит меньшей длины. И, напротив, встречающимся редко — цепочку большей длины.

115
|
|
|
|
К оглавлению ↑ |
|
|
|
|
|
|
|
|
Определение: |
|
|
|
|
|
|
|
|
|
|
|
Пусть |
— алфавит из n различных символов, |
— |
|
|
|
|
||||
|
соответствующий ему набор положительных целых весов. Тогда набор бинарных |
|
|
||
|
кодов |
, такой, что: |
|
|
|
|
1. не является префиксом для , при |
|
|
|
|
|
2. Сумма |
минимальна. ( |
— длина кода ) |
|
|
|
называется кодом Хаффмана. |
|
|
|
|
|
|
|
|
|
|
Алгоритм Построение кода Хаффмана сводится к построению соответствующего бинарного дерева по
следующему алгоритму:
1.Составим список кодируемых символов, при этом будем рассматривать один символ как дерево, состоящее из одного элемента, весом, равным частоте появления символа в тексте.
2.Из списка выберем два узла с наименьшим весом.
3.Сформируем новый узел с весом, равным сумме весов выбранных узлов, и присоединим к нему два выбранных узла в качестве дочерних.
4.Добавим к списку только что сформированный узел.
5.Если в списке больше одного узла, то повторить пункты со второго по пятый.
Алгоритм Хаффмена:
1.Выписываем в ряд все символы алфавита в порядке возрастания или убывания вероятности их появления в тексте.
2.Последовательно объединяем два символа с наименьшими вероятностями появления в новый составной символ, вероятность появления которого полагаем равной сумме вероятностей составляющих его символов. В конце концов построим дерево, каждый узел которого имеет суммарную вероятность всех узлов, находящихся ниже него.
3.Прослеживаем путь к каждому листу дерева, помечая направление к каждому узлу
(например, направо - 1, налево - 0) . Полученная последовательность дает кодовое слово, соответствующее каждому символу
Алгоритм Шенона-Фено
— один из первых алгоритмов сжатия, который впервые сформулировали американские учёные Шеннон и Фано (англ. Robert Fano). Данный метод сжатия имеет большое сходство
с алгоритмом Хаффмана, который появился на несколько лет позже. Алгоритм использует коды переменной длины: часто встречающийся символ кодируется кодом меньшей длины, редко встречающийся — кодом большей длины. Коды Шеннона — Фано префиксные, то есть никакое кодовое слово не является префиксом любого другого. Это свойство позволяет однозначно декодировать любую последовательность кодовых слов.
Основные сведения
Кодирование Шеннона — Фано (англ. Shannon-Fano coding) — алгоритм префиксного неоднородного кодирования. Относится к вероятностным методам сжатия (точнее, методам контекстного моделирования нулевого порядка). Подобно алгоритму Хаффмана, алгоритм Шеннона — Фано использует избыточность сообщения, заключённую в неоднородном
распределении частот символов его (первичного) алфавита, то есть заменяет коды более частых символов короткими двоичными последовательностями, а коды более редких символов — более длинными двоичными последовательностями.
Алгоритм был независимо друг от друга разработан Шенноном (публикация «Математическая теория связи», 1948 год) и, позже, Фано (опубликовано как технический отчёт).
Основные этапы
1. Символы первичного алфавита m1 выписывают в порядке убывания вероятностей.
116
К оглавлению ↑
2.Символы полученного алфавита делят на две части, суммарные вероятности символов которых максимально близки друг другу.
3.В префиксном коде для первой части алфавита присваивается двоичная цифра «0», второй части — «1».
4.Полученные части рекурсивно делятся и их частям назначаются соответствующие двоичные цифры в префиксном коде.
Когда размер подалфавита становится равен нулю или единице, то дальнейшего удлинения
префиксного кода для соответствующих ему символов первичного алфавита не происходит, таким образом, алгоритм присваивает различным символам префиксные коды разной длины. На шаге деления алфавита существует неоднозначность, так как разность суммарных вероятностей  может быть одинакова для двух вариантов разделения (учитывая, что все символы первичного алфавита имеют вероятность больше нуля).
может быть одинакова для двух вариантов разделения (учитывая, что все символы первичного алфавита имеют вероятность больше нуля).
Алгоритм вычисления кодов Шеннона — Фано Код Шеннона — Фано строится с помощью дерева. Построение этого дерева начинается от
корня. Всё множество кодируемых элементов соответствует корню дерева (вершине первого уровня). Оно разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Эти подмножества соответствуют двум вершинам второго уровня, которые соединяются с корнем. Далее каждое из этих подмножеств разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Им соответствуют вершины третьего уровня. Если подмножество содержит единственный элемент, то ему соответствует концевая вершина кодового дерева; такое подмножество разбиению не подлежит. Подобным образом поступаем до тех пор, пока не получим все концевые вершины. Ветви кодового дерева размечаем символами 1 и 0, как в случае кода Хаффмана.
При построении кода Шеннона — Фано разбиение множества элементов может быть произведено, вообще говоря, несколькими способами. Выбор разбиения на уровне n может ухудшить варианты разбиения на следующем уровне (n + 1) и привести к неоптимальности кода в целом. Другими словами, оптимальное поведение на каждом шаге пути ещё не гарантирует оптимальности всей совокупности действий. Поэтому код Шеннона — Фано не является оптимальным в общем смысле, хотя и дает оптимальные результаты при некоторых распределениях вероятностей. Для одного и того же распределения вероятностей можно построить, вообще говоря, несколько кодов Шеннона — Фано, и все они могут дать различные результаты. Если построить все возможные коды Шеннона — Фано для данного распределения вероятностей, то среди них будут находиться и все коды Хаффмана, то есть оптимальные коды.
Пример кодового дерева
Исходные символы:
A (частота встречаемости 50)
B (частота встречаемости 39)
C (частота встречаемости 18)
D (частота встречаемости 49)
E (частота встречаемости 35)
F (частота встречаемости 24)
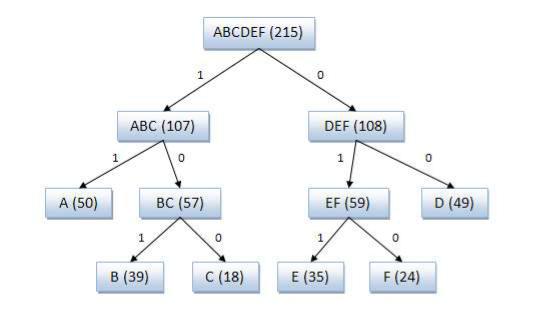
117
К оглавлению ↑
Кодовое дерево
Полученный код: A — 11, B — 101, C — 100, D — 00, E — 011, F — 010.
Кодирование Шеннона — Фано является достаточно старым методом сжатия, и на сегодняшний день оно не представляет особого практического интереса. В большинстве случаев, длина последовательности, сжатой по данному методу, равна длине сжатой последовательности с использованием кодирования Хаффмана. Но на некоторых последовательностях могут сформироваться неоптимальные коды Шеннона — Фано, поэтому более эффективным считается сжатие методом Хаффмана.
Литература: [1], [3], [5].
5. Сжатие данных
Два типа сжатия данных.
Все методы сжатия данных делятся на два основных класса:
Сжатие без потерь
Сжатие с потерями При использовании сжатия без потерь возможно полное восстановление исходных данных,
сжатие с потерями позволяет восстановить данные с искажениями, обычно несущественными с точки зрения дальнейшего использования восстановленных данных. Сжатие без потерь обычно используется для передачи и хранения текстовых данных, компьютерных программ, реже — для сокращения объёма аудио- и видеоданных, цифровых фотографий и т. п., в случаях, когда искажения недопустимы или нежелательны. Сжатие с потерями, обладающее значительно большей, чем сжатие без потерь, эффективностью, обычно применяется для сокращения объёма аудио- и видеоданных и цифровых фотографий в тех случаях, когда такое сокращение является приоритетным, а полное соответствие исходных и восстановленных данных не требуется.
Классификация алгоритмов сжатия данных.
Методы сжатия данных можно разделить на два типа:
1.Неискажающие (loseless) методы сжатия (называемые также методами сжатия без потерь) гарантируют, что декодированные данные будут в точности совпадать с исходными;
118
К оглавлению ↑
2.Искажающие (lossy) методы сжатия (называемые также методами сжатия с потерями) могут искажать исходные данные, например за счет удаления несущественной части данных, после
чего полное восстановление невозможно.
Первый тип сжатия применяют, когда данные важно восстановить после сжатия в неискаженном виде, это важно для текстов, числовых данных и т. п. Полностью обратимое сжатие, по определению, ничего не удаляет из исходных данных. Сжатие достигается только за счет иного, более экономичного, представления данных.
Второй тип сжатия применяют, в основном, для видео изображений и звука. За счет потерь может быть достигнута более высокая степень сжатия. В этом случае потери при сжатии означают несущественное искажение изображения (звука) которые не препятствуют нормальному восприятию, но при сличении оригинала и восстановленной после сжатия копии могут быть замечены.
Кроме того, можно выделить:
методы сжатия общего назначения (general-purpose), которые не зависят от физической природы входных данных и, как правило, ориентированы на сжатие текстов, исполняемых программ, объектных модулей и библиотек и т. д., т. е. данных, которые в основном и хранятся в ЭВМ;
специальные (special) методы сжатия, которые ориентированы на сжатие данных известной природы, например, звука, изображений и т. д. И за счет знания специфических особенностей сжимаемых данных достигают существенно лучшего качества и/или скорости сжатия, чем при
использовании методов общего назначения.
По определению, методы сжатия общего назначения – неискажающие; искажающими могут быть только специальные методы сжатия. Как правило, искажения допустимы только при обработке всевозможных сигналов (звука, изображения, данных с физических датчиков), когда известно, каким образом и до какой степени можно изменить данные без потери их потребительских качеств.
Алгоритм Лемпеля-Зива.
В 1977 году Абрахам Лемпель и Якоб Зив предложили алгоритм сжатия данных, названный позднее LZ77. Этот алгоритм используется в программах архивирования
текстов compress, lha, pkzip и arj. Модификация алгоритма LZ78 применяется для сжатия двоичных данных. Эти модификации алгоритма защищены патентами США. Алгоритм предполагает кодирование последовательности бит путем разбивки ее на фразы с последующим кодированием этих фраз. Позднее появилась модификация алгоритма LZ78 – Lempel-Ziv Welsh (использует словарь для байтов для потоков октетов).
Суть алгоритма заключается в следующем:
Если в тексте встретится повторение строк символов, то повторные строки заменяются ссылками (указателями) на исходную строку. Ссылка имеет формат <префикс, расстояние, длина>. Префикс в этом случае равен 1. Поле расстояние идентифицирует слово в словаре строк. Если строки в словаре нет, генерируется код символ вида <префикс, символ>, где поле префикс =0, а полесимвол соответствует текущему символу исходного текста. Отсюда видно, что префикс служит для разделения кодов указателя от кодов символ. Введение кодов символ, позволяет оптимизировать словарь и поднять эффективность сжатия. Главная алгоритмическая проблема здесь заключатся в оптимальном выборе строк, так как это предполагает значительный объем переборов.
Рассмотрим пример с исходной последовательностью (см.
также http://geeignetra.chat.ru/lempel/lempelziv.htm)
U=0010001101 (без надежды получить реальное сжатие для столь ограниченного объема исходного материала).
Введем обозначения: P[n] - фраза с номером n. C - результат сжатия.
Разложение исходной последовательности бит на фразы представлено в таблице ниже.

119
|
|
|
|
|
|
|
|
|
|
К оглавлению ↑ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
N |
|
|
Значе |
|
|
Формула |
|
|
Исходная последовательность U |
|
|
фразы |
|
|
ние |
|
|
|
|
|
|
|
0 |
|
- |
|
|
P[0] |
0010001101 |
|
||||
|
|
|
|
|
|
|
|
||||
1 |
|
0 |
|
|
P[1]=P[0]. |
0. 010001101 |
|
||||
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
2 |
|
01 |
|
|
P[2]=P[1]. |
0.01.0001101 |
|
||||
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
3 |
|
010 |
|
|
P[3]=P[1]. |
0. 01.00.01101 |
|
||||
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
4 |
|
00 |
|
|
P[4]=P[2]. |
0. 01.00.011.01 |
|
||||
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
||||
5 |
|
011 |
|
|
P[5]=P[1]. |
0. 01.00. 011.01 |
|
||||
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
P[0] - пустая строка. Символом . (точка) обозначается операция объединения (конкатенации). Формируем пары строк, каждая из которых имеет вид (A.B). Каждая пара образует новую
фразу и содержит идентификатор предыдущей фразы и бит, присоединяемый к этой фразе. Объединение всех этих пар представляет окончательный результат сжатия С. P[1]=P[0].0 дает (00.0), P[2]=P[1].0 дает (01.0) и т.д. Схема преобразования отражена в таблице ниже.
|
Форм |
|
P[1]=P[ |
P[2]=P[ |
P[3]=P[ |
|
P[4]=P[ |
P[5]=P[ |
|
улы |
|
0].0 |
|
1].1 |
1].0 |
2].1 |
|
1].1 |
|
|
|
|
|
|
|
|
|
|
|
|
Пары |
|
00.0=00 |
01.1=01 |
01.0=01 |
|
10.1=10 |
01.1=01 |
|
|
|
0 |
|
1 |
0 |
1 |
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
000.011.010.101.011 = 000011010101011 |
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Все формулы, содержащие P[0] вовсе не дают сжатия. Очевидно, что С длиннее U, но это получается для короткой исходной последовательности. В случае материала большего объема будет получено реальное сжатие исходной последовательности.
Литература: [1], [3], [5].
6. Помехоустойчивое кодирование
Помехоустойчивое кодирование (на простом примере).
Под помехой понимается любое воздействие, накладывающееся на полезный сигнал и затрудняющее его прием. Ниже приведена классификация помех и их источников.

120
К оглавлению ↑
Внешние источники помех вызывают в основном импульсные помехи, а внутренние флуктуационные. Помехи, накладываясь на видеосигнал, приводят к двум типам искажений: краевые и дробления. Краевые искажения связаны со смещением переднего или заднего фронта импульса. Дробление связано с дроблением единого видеосигнала на некоторое количество более коротких сигналов.
Приведем классификацию помехоустойчивых кодов.
Построение помехоустойчивых кодов в основном связано с добавлением к исходной омбинации (kсимволов) контрольных (rсимволов) см.на рис.5.1. Закодированная комбинация
будет составлять nсимволов. Эти коды часто называют (n,k) коды. k—число символов в исходной комбинации
r—число контрольных символов Рис.5.1. Получение(n,k)-кодов.
Надёжность электронных устройств по мере их совершенствования всё время возрастает, по, тем не менее, в их работе возможны ошибки, как систематические, так и случайные. Сигнал в канале связи может быть искажён помехой, поверхность магнитного носителя может быть повреждена, в разъёме может быть потерян контакт. Ошибки аппаратуры ведут к искажению или потере передаваемых или хранимых данных. При определённых условиях, некоторые из которых рассматриваются в этом разделе, можно применять методы кодирования, позволяющие правильно декодировать исходное сообщение, несмотря па ошибки в данных кода. В качестве исследуемой модели достаточно рассмотреть канал связи с помехами, потому что к этому