

Нахождение уравнения регрессии
Регрессия [regression] – зависимость среднего значения какой-либо случайной величины от некоторой другой величины (парная регрессия) или нескольких величин (множественная регрессия).
Уравнение
линейной парной регрессии имеет вид:
 .
.
Для оценки параметров a, b методом наименьших квадратов (МНК) необходимо решить систему нормальных уравнений:
|
|
(1.1) |

private int CalculateEquation()
{
double sumX = x.Sum();
double sumY = y.Sum();
double sumXY = 0;
for (int i = 0; i < count; i++)
{
sumXY = sumXY + x[i] * y[i];
}
double sumX2 = 0;
for (int i = 0; i < count; i++)
{
sumX2 = sumX2 + x[i] * x[i];
}
//Slope(b) = (NΣXY - (ΣX)(ΣY)) / (NΣX2 - (ΣX)^2)
slope = (count * sumXY - sumX * sumY) / (count * sumX2 - Math.Pow(sumX, 2));
//Intercept(a) = (ΣY - b(ΣX)) / N
intercept = (sumY - slope * sumX) / count;
return 0;
}
Проверка адекватности модели регрессии
Для оценки тесноты линейной связи между переменными используют линейный коэффициент парной корреляции:
|
|
(1.3) |
 ,
,
где  – среднеквадратическое отклонение
(СКО) переменной Х;
– среднеквадратическое отклонение
(СКО) переменной Х;
 – среднеквадратическое отклонение
(СКО) переменной Y.
– среднеквадратическое отклонение
(СКО) переменной Y.
Можно считать, что:
1)
если
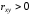 ,
то имеетсяпрямая
линейная связь между переменными Х и
Y;
,
то имеетсяпрямая
линейная связь между переменными Х и
Y;
2)
если
 ,
то имеетсяобратная
линейная связь между переменными Х и
Y;
,
то имеетсяобратная
линейная связь между переменными Х и
Y;
3)
если
 (
( ),
то линейная связь между переменными Х
и Yотсутствует.
),
то линейная связь между переменными Х
и Yотсутствует.
Качественная оценка тесноты связи величин Х и Y может быть выявлена на основе шкалы Чеддока:
|
Тестона связи |
Значение коэффициента корреляции |
|
Слабая |
0,1-0,3 |
|
Умеренная |
0,3-0,5 |
|
Заметная |
0,5-0,7 |
|
Высокая |
0,7-0,9 |
|
Весьма высокая |
0,9-0,99 |
private int CalculateCorrelationCoefficient()
{
double sumX = x.Sum();
double sumY = y.Sum();
double sumXY = 0;
for (int i = 0; i < count; i++)
{
sumXY = sumXY + x[i] * y[i];
}
double sumX2 = 0;
for (int i = 0; i < count; i++)
{
sumX2 = sumX2 + x[i] * x[i];
}
double sumY2 = 0;
for (int i = 0; i < count; i++)
{
sumY2 = sumY2 + y[i] * y[i];
}
// Correlation(r) =[ NΣXY - (ΣX)(ΣY) / Sqrt([NΣX2 - (ΣX)2][NΣY2 - (ΣY)2])]
correlationCoefficient =
( count * sumXY - sumX * sumY ) /
( Math.Sqrt(
(count * sumX2 - Math.Pow(sumX,2) ) * ( count * sumY2 - Math.Pow(sumY,2) )
) );
return 0; }
Для
оценки качества уравнения регрессии
использую коэффициент
детерминации
 .
.
Коэффициент детерминации характеризует долю дисперсии, объясняемую регрессией, в общей дисперсии результативного признака (квадрат коэффициента корреляции):
|
|
(1.4) |
 .
.
Коэффициент
детерминации показывает, какую часть
вариации (изменения) результативной
переменной Y объясняет вариация
(изменение) фактора X. Чем ближе
 к единице, тем лучше регрессионная
модель.
к единице, тем лучше регрессионная
модель.
private double getR()
{
return Math.Pow(correlationCoefficient, 2);
}
Оценка статистической значимости уравнения регрессии в целом осуществляется с помощью F-критерия Фишера. Проверяется гипотеза Н0 о статистической незначимости уравнения регрессии. Для этого рассчитывается фактическое значение критерия по формуле:
|
|
(1.5) |
 ,
,где n – число единиц совокупности;
m – число параметров при переменных х.
Если применяется линейное уравнение регрессии, то расчет Fфакт упрощается:
|
|
(1.6) |
 .
.private double getFFactual()
{
double SQR_R = Math.Pow( getR(), 2 );
return SQR_R * (count - 2) / ( 1 - SQR_R );
}
Fтабл
– это максимально возможное значение
критерия, которое могло сформироваться
под влиянием случайных факторов при
данных степенях свободы и уровне
значимости .
Уровень значимости
– вероятность отвергнуть правильную
гипотезу при условии, что она верна.
Имеются таблицы критических (табличных)
значений F-критерия: F(;
k1;
k2),
где
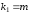 ,
, .
Для линейного уравнения парной регрессии
с уровнем значимости = 0,05
необходимо в таблице значений
(приложение №4) найти значение F(0,05;
1; n – 2).
.
Для линейного уравнения парной регрессии
с уровнем значимости = 0,05
необходимо в таблице значений
(приложение №4) найти значение F(0,05;
1; n – 2).
Если Fтабл < Fфакт, то гипотеза Н0 о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность.
private double getFTable()
{
double retVal = 0;
for (int i = 0; i < fTable.GetLength(0) - 1; i++)
{
if (count >= fTable[i, 0] && count < fTable[i + 1, 0])
{
retVal = fTable[i, 1];
}
}
if (retVal == 0) throw new System.ArgumentOutOfRangeException("GetFtableError");
return retVal;
}
public bool isModelSignificant()
{
if ( getFTable() <= getFFactual() )
return true;
else return false;
}
Для оценки статистической значимости коэффициентов регрессии и коэффициента корреляции рассчитывается t-критерий Стьюдента. Выдвигается гипотеза H0 о случайной природе показателей, т.е. о незначимом их отличии от нуля. Наблюдаемые значения t-критерия рассчитываются по формулам:
|
|
(1.7) |
 ,
,
 ,
, ,
,
где  – случайные ошибки параметров линейной
регрессии и коэффициента корреляции.
– случайные ошибки параметров линейной
регрессии и коэффициента корреляции.
Для
линейной парной регрессии выполняется
равенство
 ,
поэтому проверки гипотез о значимости
коэффициента регрессии при факторе и
коэффициента корреляции равносильны
проверке гипотезы о статистической
значимости уравнения регрессии в целом.
,
поэтому проверки гипотез о значимости
коэффициента регрессии при факторе и
коэффициента корреляции равносильны
проверке гипотезы о статистической
значимости уравнения регрессии в целом.
При проверке независимости значений ei определяется отсутствие в остаточном ряду автокорреляции, под которой понимается корреляция между элементами одного и того же числового ряда. В нашем случае автокорреляция - это корреляция ряда e1, e2, e3 ... с рядом eL+1, eL+2, eL+3 ... Число L характеризует запаздывание (лаг). Корреляция между соседними членами ряда (т.е. когда L = 1) называется автокорреляцией первого порядка. Далее для остаточного ряда будем рассматривать зависимость между соседними элементами ei.
Значительная автокорреляция говорит о том, что спецификация регрессии выполнена неправильно (неправильно определен тип зависимости).
Наличие автокорреляции может быть выявлено при помощи d-критерия Дарбина-Уотсона. Значение критерия вычисляется по формуле:
|
|
(6.15) |
 .
.Эта величина сравнивается с двумя табличными уровнями: нижним - d1 и верхним - d2. Соответствующая статистическая таблица приведена в приложении. Если полученное значение d больше двух, то перед сопоставлением его нужно преобразовать:
|
d' = 4 - d. |
|
Если d (или d') находится в интервале от нуля до d1 , то значения остаточного ряда сильно автокоррелированы.
Если значение d-критерия попадает в интервал от d2 до 2, то автокорреляция отсутствует.
Если d1 < d< d2 - однозначного вывода об отсутствии или наличии автокорреляции сделать нельзя.
private List<double> getResidual()
{
List<double> residual = new List<double>();
for (int i = 0; i < count; i++)
{
residual.Add(intercept + (slope * x[i]) - y[i]);
}
return residual;
}
public int isAutoCorrelated()
{
List<double> residual = getResidual();
double sumresvar = 0;
for (int i = 1; i < count; i++)
{
sumresvar = sumresvar + Math.Pow(residual[i] - residual[i - 1], 2);
}
for ( int i = 0; i < count; i++ )
residual[i] = residual[i] * residual[i];
double sumres2 = residual.Sum();
double d = sumresvar / sumres2;
if ( d > 2 ) d = 4 - d;
if (getDTable()[1] <= d && d <= 2)
return 0;//not autocorrelated
if (0 <= d && d <= getDTable()[0])
return 1;//autocorrelated
return -1; //not enough data
}
Соответствие остаточного ряда нормальному распределению проще всего проверить при помощи RS-критерия:
|
|
(6.17) |
где emax - максимальное значение ряда остатков;
emin - минимальное значение ряда остатков;
 -
среднеквадратическое отклонение
значений остаточного ряда.
-
среднеквадратическое отклонение
значений остаточного ряда.
Если рассчитанное значение попадает между табулированными границами с заданным уровнем вероятности, то гипотеза о нормальном распределении принимается. Соответствующая статистическая таблица приведена в приложении.
public bool isNormalResidualDispersion()
{
List<double> residual = getResidual();
double resmax = residual.Max();
double resmin = residual.Min();
double sumresvar = 0;
for (int i = 1; i < count; i++)
{
sumresvar = sumresvar + Math.Pow(residual[i] - residual[i - 1], 2);
}
double RS = (resmax - resmin) / Math.Sqrt(sumresvar / (count - 1));
if (getRSTable()[0] <= RS && RS <= getRSTable()[1])
return true;
else
return false;
}