

1.5.1 Пзу микропроцессора
Посмотрим еще раз на формулу коэффициентов WN:
![]() .
Для нашей бабочкиNпринимает значения {2,4,8,16,32,64} на первом
проходе и {128,256,512,1024,2048,4096} на втором. Как
следует из формулы, каждый набор значенийWNна
уровне преобразованияt,
является подмножеством значенийWNна уровне (t+1). Т.е. нам надо
хранить только значения последнего
уровня -W4096. Учитывая
то, формулаWNсимметрична, можно хранить лишь половину
значений (это также видно и из схемы
бабочки), т.е. 2048.
.
Для нашей бабочкиNпринимает значения {2,4,8,16,32,64} на первом
проходе и {128,256,512,1024,2048,4096} на втором. Как
следует из формулы, каждый набор значенийWNна
уровне преобразованияt,
является подмножеством значенийWNна уровне (t+1). Т.е. нам надо
хранить только значения последнего
уровня -W4096. Учитывая
то, формулаWNсимметрична, можно хранить лишь половину
значений (это также видно и из схемы
бабочки), т.е. 2048.
Можно поступить
иначе: из набора коэффициентов
![]() можно получить все остальные
последовательным умножением на
поворачивающие множители
можно получить все остальные
последовательным умножением на
поворачивающие множители![]() .
В этом случае эффективность немного
упадет, зато размер ПЗУ получится очень
небольшим (68x16). Величина
разрядной сетки значений – 16 бит. ПЗУ
также размещается на кристалле
микропроцессора.
.
В этом случае эффективность немного
упадет, зато размер ПЗУ получится очень
небольшим (68x16). Величина
разрядной сетки значений – 16 бит. ПЗУ
также размещается на кристалле
микропроцессора.
1.6 Взаимодействие с внешним озу
Теоретически, внешнее ОЗУ может быть любым. Возьмем для простоты в качестве внешнего статическое асинхронное ОЗУ. Конструктивно оно выполнено в виде единой микросхемы. В настоящее время можно найти множество различных вариантов от разных производителей, особенно учитывая небольшую емкость ОЗУ – 4Кx16 (уже существуют и выпускаются микросхемы статического ОЗУ на 4Мбита).
Рассмотрим взаимодействие между микропроцессором и ОЗУ на уровне временных диаграмм. В качестве ОЗУ возьмем 16-ти разрядную микросхему памяти SamsungсерииK6R1016C1C. Соответствующие временные диаграммы фаз чтения и записи тогда будут выглядеть следующим образом:
1.6.1 Цикл чтения из озу:
Цикл чтения
из ОЗУ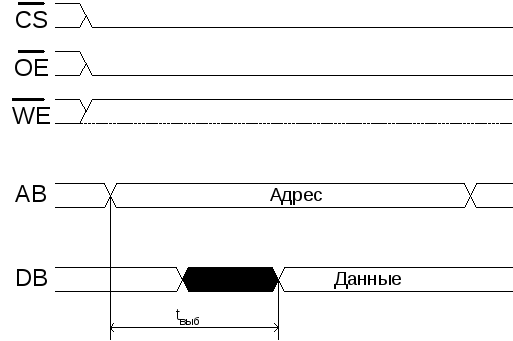
На линии WEвыставляется высокий уровень (чтение). Выставляются сигналыCSиOE.
На шине адреса(AB) выставляется адрес требуемого слова.
Через время tвыб, необходимое для того, чтобы извлечь слово по нужному адресу из памяти, результат можно снимать с шины данных(DB).
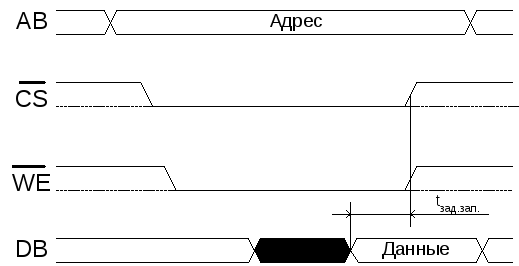
1.6.2 Цикл записи в озу:
На шине адреса(AB) выставляется адрес ячейки памяти для записи.
Выставляются сигналы CS и WE.
На шине данных(DB) выставляются данные, которые необходимо записать в память. Выдерживается время для гарантированной записи данных в память, по прошествии которого сигналыCSиWEснимаются.
Ц
Для микросхем этой
серии длительности циклов чтения и
записи слова по определенному адресу
лежат в диапазоне 1020
нс. Учитывая то, что данные на вход
бабочки подаются блоками по 64 слова,
получаем, что полная длительность цикла
чтения и записи не менее 6401280
нс. Учитывая то, что время работы одного
умножителя в среднем 17нс, время работы
бабочки на 64 входа составляет никак не
меньше![]() (и
это еще без учета сложений). Следовательно
за время преобразования вполне можно
успеть выкачать из внешнего ОЗУ новую
порцию данных и сбросить старую. Так
что «простоев» бабочки из-за медленных
внешних каналов не будет
(и
это еще без учета сложений). Следовательно
за время преобразования вполне можно
успеть выкачать из внешнего ОЗУ новую
порцию данных и сбросить старую. Так
что «простоев» бабочки из-за медленных
внешних каналов не будет
1.7 Устройство, вычисляющее бпф
Рассмотрим на уровне эскиза устройство, выполняющее БПФ. В качестве интерфейсной шины выбрана шину PCI. Действительно, шинаISAне является удачным выбором по двум причинам:
Гораздо более низкая производительность, чем у шины PCI(8Мгц против 33Мгц, 16 разрядов против 32).
Практическое отсутствие в настоящее время поддержки шины ISAсо стороны производителей материнских плат.
В «общении» ПК с устройством можно рассматривать две фазы. Первая – передача устройству набора исходных данных. Вторая – получение от устройства набора коэффициентов ДПФ.
Вообще говоря, для полноценной поддержки PCIсо стороны устройства удобнее всего поставить готовый контроллер от таких фирм, какAMCC. Он гарантирует, что устройство будет полностью соответствовать спецификацииPCI, а интерфейс, который он предлагает пользователю, гораздо проще в использовании. Тогда устройство для вычисления БПФ будет функционально состоять из трех следующих блоков: микроконтроллераAMCCS5920, микросхемы статического ОЗУ и собственно микропроцессора.