

2.7.3. Оценка производительности
Цель оценки производительности состоит в предсказании производительности системы. Основная проблема состоит в том, что необходимо иметь наихудшие сведения о системе раньше, чем средние значения о ней. Такая информация необходима для гарантии реализации ограничений реального времени. Для получения информации о производительности уже на ранних стадиях проектирования было предложено два различных класса техник – это предполагаемые и точные значения стоимость и производительности. Техника точного значения использует реальный программный код (в бинарной форме) на близкой к реальной аппаратной платформе. Это возможно только если существуют интерфейсы с инструментами разработки аппаратного и программного (компиляторам) обеспечения. Метод является достаточно точным, но со значительными временными затратами. Для получения точного значения необходимо также рассматривать и коммуникационные компоненты системы. К сожалению, обычно трудно посчитать стоимость коммуникационной составляющей на ранней стадии проектирования.
2.7.3.1. Оценка wcet
Оценивание WCET [37]. Это техники формальной оценки производительности требуют некоторых знаний архитектуры. Они меньше подходят для очень ранней стадии проектирования, но некоторые из них могут быть использованы без знаний всех деталей целевой архитектуры. Эти подходы моделируют реальность, физическое время. Планирование задач требует некоторых знаний о длительности их выполнения, особенно если требуются гарантии удовлетворения временных ограничений, таких как в системах реального времени. WCET (worst case execution time – наихудший случай времени выполнения) является базой для большинства алгоритмов планирования задач. Некоторые определения, относящиеся к WCET, показаны на рис. 95.
Величина WCET является наибольшим временем выполнения программы для некоторых входных данных и начальных состояний. К сожалению WCET чрезвычайно трудно вычислить. В общем случае вычисление является неразрешимой задачей, но в любом случае WCET имеет конечное значение, т.к. работа программы всегда останавливается. Следовательно, WCET может быть вычисленной только для определенных программ, например, для программ без рекурсии, без циклов while и с циклами с заведомо известным числом повторений. Но даже с такими ограничениями обычно практически невозможно вычислить WCET. Препятствиями для точного
Распределение
времени
выполнения
Рис. 95. Терминология WCET
прогнозирования на этапе проектирования являются эффект от конвейеров в архитектурах современных процессоров с различными видами рисков и иерархия памяти с ограниченной предсказуемостью частоты успешных обращений. Вычисление WCET для систем содержащих кэш, конвейеры, прерывания и виртуальную память является еще большим испытанием. В результате счастьем является возможность получения хороших верхних границ величины WCET. Такие верхние границы обычно называют ожидаемой WCET или WCETEST. Они должны иметь два свойства:
– должны быть надежными (WCETEST ≥ WCET);
– должны быть впритирку (WCETEST-WCET << WCET).
Заметим, что термин «ожидаемый» не означает, что результирующее время ненадежно.
Иногда архитектурные особенности уменьшающие среднее время выполнения, но не гарантирующие уменьшение WCET полностью исключаются из проектов реального времени. Вычисление впритирку верхних границ времени выполнения все еще может быть трудным. Рассмотренные выше архитектурные особенности также представляют проблему для вычисления WCETEST.
Величина BCET (best -case execution time – наилучший случай времени выполнения) и соответственная ожидаемая BCETEST определяются в аналогичной манере. Величина BCETEST является надежной нижней границей впритирку времени выполнения.
Невозможно вычисление границ впритирку из программы, написанной на языке высокого уровня таком как Си без знания сгенерированного ассемблерного кода и лежащей в основании архитектурной платформы.
На рис. 96 представлена архитектура инструмента aiT [42]. aiT начинает с исполнительного объектного файла, содержащего требуемый для анализа кода. На основании этого кода строится граф потока управления (CFG -Control Flow Graph ) – представление в виде графа всех путей, по которым может пройти программа во время своего выполнения. Затем выполняется преобразование циклов. Оно включает преобразование вызовов рекурсивных функций в циклы, а также виртуальное разворачивания цикла. Разворачивание называют виртуальным, так как оно выполняется без реального модифицирования кода. Результат представляется в CRL формате (control flow representation language – язык представления потока управления). На следующем этапе выполняется различный статический анализ. В процессе статического анализа читается AIP-файл, содержащий пояснения разработчика. Эти пояснения включают информацию, которую трудно или невозможно извлечь из программы автоматически (например, границы сложных циклов). Статический анализ включает анализ значений, стека и конвейера.

Рис. 96. Архитектура aiT инструмента для анализа времени
Анализ значений вычисляет границы интервалов содержимого регистров и локальных переменных. Полученная информация может быть использована для анализа потока управления и анализа данных в кэш. Часто точно известны значения адресов, так что это помогает предсказуемому анализу доступа к памяти.
Следующий шаг это анализ кэш и конвейера. Предположим, что используется n-входовая ассоциативная по множеству кэш (рис. 97). Рассмотрим часть (строку) кэш соответствующую отдельному индексу (выделена жирной линией). Предположим, что замещение этой части кэш выполняется по алгоритму LRU (замещения наиболее давней по использованию страницы). Это означает, что среди всех ссылок на ячейки памяти для отдельного индекса в адресе последние n из них отсылали к блокам памяти, запомненным в этой части кэш. Блок памяти ‘b’, получивший доступ перемещается в позицию кэш, становящуюся самой «молодой», а все остальные блоки кэш «стареют» на 1.
Предположим, что необходимые для LRU действия аппаратуры выполняются для каждого индекса, и что каждый индекс управляется независимо от других. При таком предположении все замещения для определенного индекса полностью независимы от решения для других индексов. Эта независимость крайне важна, т.к. позволяет рассматривать каждый из индексов независимо.


Рис. 97. Ассоциативная по множеству кэш (n=4)
Представим часть кэш и отдельный индекс. Предположим, что имеется информация о возможных записях для каждого из n входов (колонок) кэш. Кроме того рассмотрим сходящийся поток управления. Что известно о содержимом части кэш в точке схождения путей? Необходимо сделать различие между анализом возможной и обязательной информацией. Анализ обязательности показывает записи, которые должны быть в кэш. Эта информация полезна для вычисления WCET. Анализ возможности идентифицирует записи, которые могут быть в кэш. Эта информация обычно используется для заключения о том, что определенная информация точно не будет в кэш, а это необходимо для вычисления BCET. В качестве примера анализа обязательности и возможности рассмотрим обязательную информацию в сходящемся потоке управления. Рис. 98 показывает соответствующую ситуацию: содержимое строки 4-входовой кэш для одного и другого пути в CFG до схождения. Элементы, расположенные слева, предполагаются «моложе» элементов, расположенных правее.
Результат:
пересечение
+ максимальный возраст

Рис. 98. Анализ обязательности в программе соединения данных для LRUкэш
Объект памяти ‘c’ предполагается самым «молодым» для одного сходящегося пути, а объект ‘a’ – для другого. «Возраст» остальных элементов определяется таким же образом. Что известно о наихудшем случае в точке схождения путей? Определенный элемент гарантированно будет в кэш, только если он гарантированно был в обоих путях. Это означает, что пересечение объектов памяти определяет результат анализа обязательности после схождения. За наихудший случай необходимо принять максимальный возраст среди двух путей. Очевидно, что этот анализ должен использовать множества элементов для каждого входа кэш.
Рис. 99 показывает анализ возможности для сходящегося потока управления. Множество объектов, которые может содержать кэш в точке схождения путей, состоит из объединения объектов, которые были в кэш перед схождением путей. В качестве наилучшего случая используется минимальный возраст перед схождением.
Результат:
объединение
+ минимальный возраст
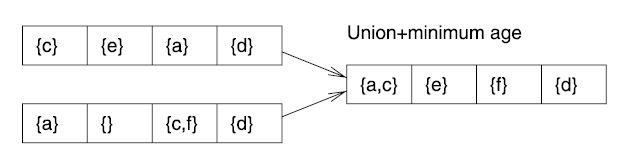
Рис. 99. Анализ возможности в программе соединения данных для LRUкэш
Статический анализ также включает анализ конвейера. При анализе конвейера необходимо получить верные границы количества циклов необходимых для выполнения машинного кода в конвейерном процессоре.
Суммарный результат статического анализа содержит границы времени выполнения для каждого из базовых блоков программы. Результаты записываются в PER-файл (рис. 91).
На следующем этапе aiT использует эти границы для получения WCET для всей программы. Этот шаг базируется на модели целочисленного линейного программирования (ILP). В этой модели суммарное время выполнения используется как целевая функция. Суммарное время выполнения вычисляется как сумма по всем оценкам базовых блоков умноженных на их частоту выполнения. Время выполнения базовых блоков определяется как время WCET однократного выполнения блока (как вычислено при статическом анализе) умноженное на количество наихудших случаев выполнения. Только некоторое количество выполнений блоков может быть определено автоматически. Поэтому построение ILP модели полагается на дополнительную информацию разработчика, например о границах цикла. Эта информация считается из AIP-файла. Ограничения моделируют отношения между блоками. Эту технику для моделирования времени выполнения называют нумерацией подразумеваемого пути. Так удается избежать нумерации потенциально большего числа путей вычислений. Оговоренная задача ILP может быть решена стандартной программой ILP для максимизации, целевой функции. Полученный максимум дает верную верхнюю границу суммарного времени выполнения. aiT также обеспечивает визуализацию результатов в форме аннотированных графов потока управления. Эти графы анализируются разработчиками для оптимизации проектов.
.