

36.Технология сжатия информации в бд.
Такие технологии применяются для сокращения пространства, занимаемого определенным набором данных. Это в свою очередь увеличивает скорость операций с БД за счет снижения количества обращений к диску.
Однако, с другой стороны, извлечение сжатых данных требуются некоторые дополнительные действия. /*Все равно очень полезно сжимать, так как главный тормоз – обращения к диску */.
Технологии сжатия основаны на том, что данные редко имеют беспорядочную структуру и часто их можно предсказать. Например, файл хранит информацию о сотрудниках, упорядоченный по фамилиям. Тогда, если запись содержит фамилию, начинающуюся с R, то следующая фамилия, скорее всего, начинается с той же буквы.
Наиболее распространенной технологией сжатия является сжатие на основе различий. При этом некоторое значение заменяется сведениями о его отличии от предыдущего. Такое сжатие требует упорядоченного хранения данных на диске. Кроме самих данных могут сжиматься и адреса, так как, если данные физически хранятся близко, то их адреса незначительно отличаются друг от друга.
Пример сжатия символьной информации. Список фамилий. Roberton Robertson Robertstone Robinson. Храним в начале каждой записи количество символов = первым символам предыдущей записи. 0Roberton,6Robertson, 7Robertstone, 3Robinson
Второй вид сжатия – иерархическое сжатие. Оно основано на предположении, что сжимаемые файлы подвергнуты кластеризации. Например, если в файле поставщиков выполнена кластеризация на основе поля город, то возможно сжатие, при котором название города будет упомянуто один раз, а за ним будут расположены записи о поставщиках из этого города, поле город уже будет в них отсутствовать.
И вообще:
http://compression.ru/download/articles/db/smirnov_2003_database_compression_review/part2.html
http://kv.fdd5-25.net/data/software/97/974704.htm
37.Основные шаги обработки запросов.
Обработка запросов – последовательность действий, приводящая к извлечению информации из БД. Последовательность действий в этом случае состоит из трансляции запроса с языка высокого уровня в выражения, выполняемые на физическом уровне, преобразования оптимизации и фактическое выполнение запроса.
Наибольший процент времени при выполнении запроса тратится на обращения к диску /* вспомнить физическое хранение */ и сортировку данных. Поэтому при выполнении запроса сначала выявляются стратегии выполнения запроса, сравниваются и производится выполнение согласно лучшей.
Общая схема обработки запроса
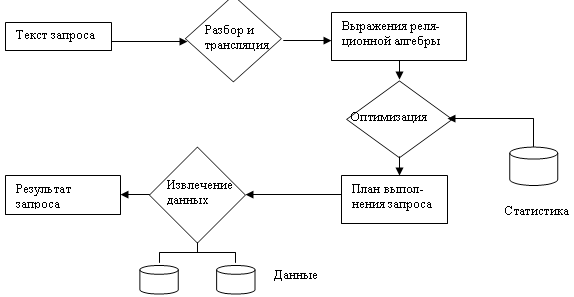
Основные шаги обработки запросов
1 Разбор и трансляция. Язык SQL удобен и понятен пользователю БД, но его невозможно использовать в качестве внутреннего языка БД. В качестве такого языка может выступать расширенная реляционная алгебра. Трансляция при обработке запроса аналогична синтаксическому разбору в трансляторе языка программирования. В процессе трансляции проверяется правильность написания запроса и ассоциация имен, использованных в запросе с именами отношений и атрибутов.
2 Оптимизация. Один и тот же запрос может быть транслирован в различные выражения реляционной алгебры. Например,
Select Сумма from счет where сумма<2500