

43.Алгоритм внешней сортировки.
Сортировка играет большую роль в выполнении запросов по двум причинам:
1 Многие запросы требуют упорядочения кортежей и такое требование поддерживается стандартом SQL.
2 Некоторые реляционные операции (объединение, например) выполняются более эффективно, если исходные отношения первоначально отсортированы.
Проблема сортировки появляется в том случае, когда сортируемые кортежи не вмещаются в оперативную память. В этом случае необходимо применять внешнюю сортировку. Наиболее часто используется внешняя сортировка смещением.
Пусть М – число блоков, помещающихся в памяти. Сортировка смещением состоит из двух этапов.
1 Создание сортированных фрагментов.
i:=0;
repeat
Считать M блоков исходного отношения или остаток отношения, если он меньше М;
Отсортировать часть отношения, находящуюся в памяти;
Записать отсортированный фрагмент в файл Ri;
i:=i+1;
until обработано все отношение.
2 Смещение фрагментов. Пусть N – число файлов, полученных на первом этапе. Предположим, что N<M.
Считать первые блоки из всех файлов в память;
repeat
Расположить первые кортежи каждого блока в отсортированном порядке;
Записать отсортированные кортежи в выходной файл и удалить их из памяти.
If i – ый блок пуст and не конец файла Ri
Then считать следующий блок файла Ri в память;
until в памяти не осталось ни одного кортежа.
Обычно каждый кортеж не записывается на диск отдельно. Кортежи формируют блок в памяти, а затем этот блок записывается в файл. /*Поэтому N<M, а неN<=M */.
Реальные отношения могут иметь очень большие размеры, поэтому может сложиться ситуация, когда число файлов, получившихся на первом этапе, больше или равно числу доступных блоков памяти. В этом случае выполняют многошаговое смещение. На первом шаге обрабатывают фрагменты с первого по М-1. В результате этого получается первый фрагмент для второго шага смещения. Затем обрабатывают следующие М-1 файл, получая второй файл для второго шага смещения и так далее. Если файлов, полученных на первом шаге больше, чем М-1, то процесс продолжается, а если нет, то выполняется последнее смещение, результатом которого будет единственный файл.
Пример. Пусть в блок содержит одну запись, память может вмещать только три блока, то есть два обрабатываемых и один результирующий.
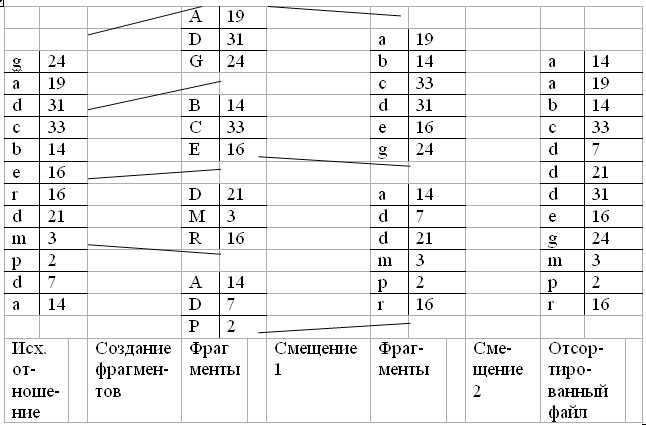
Рассмотрим эффективность внешней сортировки. На первом этапе все блоки отношения читаются и записываются на диск, то есть требуется 2br обращений к диску. После выполнения первого этапа получено br/M фрагментов. Количество фрагментов уменьшается по степени M-1. Таким образом, число смещений определяется как
logm-1(Br/M)
На каждом шаге смещения производится чтение и запись всех блоков, исключение составляет последнее смещение, так как блоки при этом только читаются, но не записываются на диск /*+1 в формуле */, Поэтому число обращений к диску на втором этапе сортировки будет
Br(2*logm-1*(Br/M)+1)
44.Размер операции соединения. Алгоритм соединения, основанный на двух вложенных циклах.
Рассмотрим как реализуются в СУБД операция соединения отношений. Это очень важная операция для СУБД, поскольку большинство запросов именно многотабличные. Поэтому оптимизация этой операции очень важна.
Пусть существуют отношения r(R) и s(S). Декартово произведение rхs включает nr*nsкортежей. Каждый кортеж занимает sr+ss байт. Таким будет размер результата соединения в худшем случае. Размер натурального соединения может быть более компактным.
Рассмотрим варианты:
а) Если пересечение атрибутов R и S = 0, то результат натурального соединения равен результату декартова произведения.
б) Если пересечение атрибутов R и S равно ключу отношения R, то каждая строка отношения s будет соединена максимум с одной строкой отношения r, то есть кортежей в результате соединения будет не больше числа кортежей отношения s.
в) Если пересечение атрибутов = {A}, причем это множество не является ключом ни для одного из отношений. Среднее количество записей в отношении s с некоторым значением атрибутов {A} равно ns\V(A,s). При соединении каждой строки отношения r с отношением s будет равно (nr*ns)\V(A, s ). Если отношения поменять местами, то оценка составит (ns*nr)\V(A, r). Если V(A, r) не равно V(A, s), то выбирают меньшую из оценок.
Простейший алгоритм соединения.
Этот алгоритм основан на использовании вложенных циклов. Рассмотрим работу алгоритма для q-соединения отношений r и s.
Для каждого кортежа tr отношения r выполнить
Для каждого кортежа ts отношения s выполнить
Если пара (ts, tr) соответствует условию
то tr?ts добавить к результату
Отношение r в этом случае называется внешним, а отношение s – внутренним. Через tr?ts обозначена конкатенация значений атрибутов кортежей tr и ts. Вычисление натурального соединения согласно алгоритму выполняется аналогично, но после конкатенации из результирующей строки исключаются повторяющиеся атрибуты.
Приведенный алгоритм неэффективен, так как для каждого кортежа внешнего отношения осуществляется просмотр каждого кортежа внутреннего отношения. В худшем случае в памяти помещается только по одному блоку каждого отношения. Тогда для построения соединения потребуется nr*bs+br доступов к диску. /*Второе слагаемое чтение всех блоков внешнего отношения, первое слагаемое – сколько доступов нужно по внутреннему отношению */. В случае, если оба отношения целиком помещаются в памяти, потребуется bs+br обращений к диску для чтения. Более того, для получения такой же эффективности достаточно, что бы в памяти целиком поместилось внутреннее отношение.