25.Сравнение эффективности хешированных файлов и файлов, организованных в виде кучи. Причины снижения эффективности хешированных файлов.
Эффективность работы хешированных файлов снижается по мере увеличения числа блоков в бакетах. Наиболее эффективным был бы вариант, когда в каждом бакете находится только один блок, т.е. эф-ть поиска равна единице (+ поиск по каталогу бакетов).
Кроме роста объема данных на снижение эффективности влияет изменение статистики распределения записи по бакетам, т.е. бакеты становятся разной длины. В любом случае причина снижения эф-ти заключается в неэф-ной hash-ф-ции.
Эффективность файла представленного в виде кучи.
Пусть в файле существует n записей. Каждый блок вмещает R записей, тогда в файле n/R блоков.
Просматриваем каждый блок и по указателю перемещаемся на следующий. Два варианта поиска:
1. Либо просматриваем n/R блоков, если поля не уникальны.
2. Либо n/2R блоков (в среднем).
При вставке также 2 варианта:
1. В этом случае читаем последний блок файла (можно получить из нулевого блока) помещаем запись в этот блок и записываем блок на диск.
2. Если уникальность, то либо n/R+2, либо n/2R
Удаление. Требуется найти запись, считать блок, в котором она находится и записать этот блок. Аналогично вставке. Часто для последующего использования освободившегося пространства, последняя запись последнего блока перемещается на место удаленной записи. Это замедляет процесс удаления, но ускоряет другие операции.
Время выполнения модификации аналогично времени удаления.
Т.о. время при выполнении операции затрачивается на поиск записей, т.е. для повышения эффективности необходимо ускорить именно поиск. Это может быть достигнуто за счет другой организации файла.
Эффективность хешированных файлов.
Все операции на хешированных файлах производятся в В-раз быстрее, чем на файлах организованных в виде кучи, где В – число бакетов. Это объясняется тем, что все операции основаны на поиске, а поиск в хешированных файла производится в В-раз быстрее.
Пусть n-число записей, тогда n/B – число записей в бакете.
n/2BR и n/BR для тех же случаев, что и в куче.
Эффективность работы ХФ снижается по мере увеличения числа блоков бакетов. Наиболее эффективным был бы вариант по 1 блоку в каждом бакете. Кроме роста объема данных на снижение эффективности оказывает влияние изменение статического распределения ключевых значений.
Причиной обоих факторов снижения эффективности является не верный выбор хеш-функции. Обычно хеш-функция выбирается исходя из знаний о количестве и распределении данных на момент создания файлов, поэтому в процессе эксплуатации она может становиться менее эффективной.
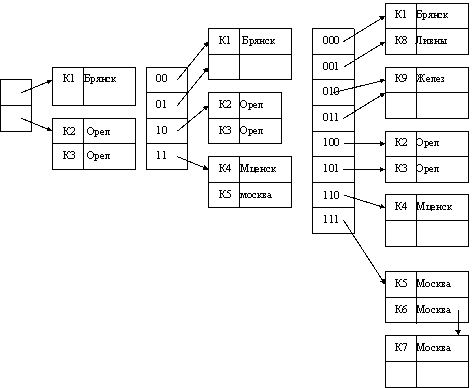
26.Динамическое хеширование. Операции над динамически хешированными файлами.
Причиной снижения эфф-ти ХФ является не верный выбор хеш-ф-ии. Обычно хеш-ф-ия выбирается исходя из знаний о кол-ве и распределении данных на момент создания файлов, поэтому в процессе эксплуатации она может становиться менее эффективной. Решением данной проблемы является замена статич-кого хеширования динамическим хеш-нием. Такой подход позволяет изменить хеш-ф-ию по мере роста или уменьшения файла. В этом случае изменение размера файла сопровождается соединением или делением бакетов. Такие изменения касаются только одного или двух бакетов, что позволяет мини-вать снижение работоспособности системы в момент ее реорганизации. При динам. хешировании хеш-ф-ия представляет ключ в двоичном виде. Эта функция генерирует значения до 2в, где b, как правило, равно 32. При создании такого файла не создаются бакеты для всех значений хеш-ф-ии. Они будут создаваться по мере занесения данных. Более того, в начале не исп-тся b-бит ключа. Кол-во бит ключа используемого в данный момент времени обозначим за i, где 0<=i<=b. Значение i увел-тся или умен-тся по мере увел-ия или умен-ия файла. Каждый блок j имеет хар-ку ij она назыв префикс бакета и указывает ск-ко бит ключей этого бакета необх-мо просмотреть (исп-вать) при работе
Для поиска записи рассматривают i бит рез-та значения hash-ф-ции, выч-ного на основе ключа записи. На основе этих бит определяем эл-т массива бакета и извлекаем необх-мый блок главного файла. В большинстве случаев остальные блоки файлов не прочит-тся, т.к. динам хеширование стремится чтобы в каждом бакете было по 1 блоку.
При вставке записи производится поиск бакета, в к-ом будет нах-ся новая запись. Если блок, находящийся по полученному адресу, имеет свободное место, то запись размещается в нем. В противном случае возникает необходимость разделения бакета и распределения записей между двумя бакетами. В этом случае возможны две ситуации:
1. i = ij. В этом случае в каталоге бакетов сущ-ет только один эл-т, указывающий на блок j. При вставке необходимо увеличить i на единицу (i=i+1), это приведет к увеличению вдвое эл-тов каталога бакетов, т.к. каждая ячейка разделится пополам. Оба указателя каждой такой пары будут иметь одинаковые значения. Исключением будет ячейка, содержавшая адрес блока j. При ее разделении одна часть будет продолжать указывать на j, а вторая будет содержать адрес нового блока, напр., z. Префиксы ij и iz устанавливают в значение i. Префиксы остальных бакетов остаются без изменений. Записи, содержавшиеся в блоке j, делятся между блоками j и z на основе i бит результата. Мы можем попасть в ситуацию, когда все такие записи, а также новая запись должны принад-ть одному из бакетов, т.е. все i бит одинаковы. В этом случае необх-о продолжить деление бакетов. Однако необх-о спрогнозировать даст ли эффект дальнейшее деление, т.к. все b бит рез-та м.б. одинаковыми. В этом случае деление бакетов производить не надо, а необх-о в бакет добавить еще один блок как при статистическом хешировании.
2. i > ij. Это означает, что более одного эл-та каталога бакетов содержит адрес блока j. В этом случае деление бакета не приводит к увеличению числа эл-тов каталога. Выделяется новый блок z и на единицу увеличиваются префиксы блоков ij. Эл-ты каталога бакетов, ранее указывавшие на j, делим пополам. Одна часть продолжает указ-ть на j, 2ая – на z. Записи распределяются между 2мя блоками на основании ij бит результата. При этом также возможно появление блока переполнения.
При удалении записей из динам хешированных файлов пустые бакеты нужно удалять. Эл-т каталога, к-ый указывал на удаляемый бакет, после удаления должен содержать тот же адрес, что и соседний эл-т. В качестве соседа рассм-ся эл-т, у к-ого с удаляемым совпадает ij – 1 бит. Префикс рассматриваемого бакета уменьшается на единицу. Если в рез-те удаления префиксы всех бакетов стали меньше i, i должно уменьшиться на единицу, что приведет к сокращению вдвое числа эл-тов каталога.
|
|
|
|
|
|