

40.Алгоритмы выполнения селекции с одним условием сравнения: размер селекции, использование первичного индекса, использование вторичного индекса.
Селекция, включающая сравнение.
До этого рассматривалась селекция, условие которой предусматривало равенство. Однако, часто селекция имеет вид s(А)<=v(r). При этом в статистике будет храниться следующая информация min(A, r) и max(A, r).
В общем случае можно утверждать, что число записей, удовлетворяющих условию А<=v, будет равно.
0, если v<min(A, r).
nr, если v>=max(A, r).
иначе
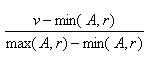
А6. Использование первичного индекса. Если условие селекции имеет вид A>v, то в индексе ищем первую запись, удовлетворяющую условию, а затем извлекаем из файла отношения все блоки, начиная с блока, включающего найденную запись и до конца файла. При условии A<v индекс не используется, а просматривается сразу файл отношения, из него извлекаются блоки до тех пор, пока записи блока соответствуют условию. Как только найдена запись, не удовлетворяющая условию, поиск прекращается. Эффективность этого алгоритма
![]()
где с – число записей, удовлетворяющих условию.
(или без первого слагаемого).
В случае, если в статистике не хранятся данные для расчета с, то вместо него используют Br (число блоков в отношении r.)
А7. Использование вторичного индекса. При этом производится просмотр самого нижнего уровня индекса с минимального значения до v при условии A<v или с v до максимального значения в противном случае.
![]()
второе слагаемое – среднее число блоков индекса, которые нужно просмотреть, третье – число блоков основного файла, так как нужно извлекать каждый блок, адрес которого встречается в индексе, то есть, сколько записей, столько и блоков.
41.Размер комплексной селекции при конъюнкции и дизъюнкции условий.
Ранее рассматривались селекции с одним условием. На практике часто встречаются более сложные условия.
Конъюнкция условий. Будем рассматривать селекцию вида S( q1&q2&…&qn(r)),где qn - условия селекции.& - конъюнкция.
Для каждого условия qi можно рассчитать размер селекции Sqi, то есть количество записей, возвращаемых селекцией. Обозначим размер i-ой селекции как si. Тогда вероятность того, что какой-либо кортеж отношения соответствует условию qi, равна si/nr по классическому определению вероятности. /*Вероятность события равна числу успехов, деленное на общее число испытаний */. Вероятность того, что кортеж соответствует всем условиям, равна произведению вероятностей соответствия кортежа каждому из условий. Тогда число кортежей, соответствующих всем условиям, будет равно произведению числа кортежей в отношении и вероятности соответствия кортежа всем условиям.
![]() Получено
из классического определения вероятности
Получено
из классического определения вероятности
Дизъюнкция условий. Рассматриваем селекцию вида Sq1 or q2 or…or qn(r). Вероятность того, что запись не соответствует условию qi, равна 1-si/nr. Вероятность того, что запись не соответствует ни одному из условий, равна произведению вероятностей. Вероятность того, что запись соответствует хотя бы одному условию, равна 1 минус полученная ранее величина. Количество записей, соответствующее дизъюнкции селекций равно.
![]()
Отрицание. S not q(r). Количество кортежей, возвращаемое такой селекцией равно разности между общим числом кортежей в отношении и количеством кортежей, возвращаемых селекцией вида sq(r).
42.Алгоритмы обработки комплексной селекции: конъюнкция с использованием простого индекса, конъюнкция с использованием составного индекса, конъюнкция на основе пересечения идентификаторов, дизъюнкция на основе объединения идентификаторов.
Рассмотрим алгоритмы обработки комплексной селекции.
А8. Конъюнкция с использованием одного индекса. При таком подходе первоначально производится выборка записей согласно одному условию, то есть используется единственный индекс (алгоритмы А2, А7). После первоначальной выборки полученные кортежи еще раз тестируются на соответствие остальным условиям. Очевидно, что важной задачей является выбор первого условия, так именно оно определяет количество считанных блоков. Первым должно быть выбрано условие, отсеивающее большинство кортежей.
А9. Конъюнкция с использованием составных индексов. Если индекс включает два или более полей, то это составной индекс. Такой индекс повышает эффективность выполнения селекций, представляющих собой конъюнкцию условий для нескольких атрибутов из составного индекса. В этом случае все сравнения производятся на индексе, а извлекаются только необходимые кортежи основного файла.
А10. Конъюнкция на основе пересечения идентификаторов. В этом случае под идентификатором понимается адрес кортежа. Такой подход требует, что бы существовали индексы по всем, полям, участвующим в условиях селекции. Алгоритм предполагает сканирование индекса для каждого из условий. В результате каждого сканирования получается множество адресов кортежей, соответствующее одному из условий. Пересечение этих множеств дает адреса кортежей, соответствующих всем условиям. Затем происходит извлечение блоков основного файла, содержащих найденные кортежи.
А11. Дизъюнкция на основе объединения идентификаторов. Аналогичен предыдущему алгоритму, но найденные после сканирования индексов множества объединяются. Затем также производится извлечение блоков основного файла.