

Можно транслировать в выражение
sсумма<2500(pсумма(счет)) или pсумма(sсумма<2500(счет)).
Для выполнения каждого оператора реляционной алгебры могут использоваться различные алгоритмы. Например, для вычисления селекции нужно пересмотреть все кортежи отношения. Если же построен индекс, по атрибуту «сумма», то можно использовать индекс для проверки условия, а затем извлекать найденные кортежи, используя адрес в индексе. Таким образом, недостаточно оттранслировать запрос в операторы реляционной алгебры, необходимо еще определить, как будет выполняться каждый из этих операторов. Инструкция для выполнения оператора реляционной алгебры называется вычислительным примитивом. Последовательность примитивов, которая будет использована для выполнения запроса, называется планом выполнения запроса. Пример такого плана
pсумма ------ sсумма<2500; используя индекс 1 ------- отношение счет
/* Рисовать деревом сверху вниз (вычисляться будет снизу вверх ) */
В общем случае работа оптимизатора состоит из двух частей. Первая – выбор выражений, эквивалентных полученным в результате трансляции, но выполняемых быстрее. Второй – выбор стратегии выполнения запроса, а именно выбора последовательности выполнения операторов или применения индексов. Выбор стратегии осуществляется на основе сравнения цены выполнения. Основным параметром в этом случае является число обращений к диску. Для определения этого параметра оптимизатор использует статистику БД. Такая статистика включает информацию о размерах отношений и индексов.
3 На третьем шаге используя выбранный план осуществляется выбор данных.
38.Статистика бд.
Статистика БД, используемая оптимизатором, хранится СУБД в специальном каталоге. Обычно статистика содержит:
1 nr – число записей в отношении r.
2 br – число блоков в отношении r.
3 sr – размер записи отношения в байтах.
4 fr – число записей в одном блоке отношения. (fit)
5 V(A,r) – число значений атрибута A в отношении r. При расчете этой характеристики не учитывают дубликаты, то есть если атрибут имеет значения 1,1,2,3,3, то характеристика = 3. Этот параметр используется для оценки стоимости выполнения операции проекции по атрибуту А.
6 SC(A, r) – кардинальность селекции. Эта характеристика указывает, сколько в среднем записей будут удовлетворять условию равенства на атрибут А. Если А – уникален, то характеристика = 1. В обще случае SC(A, r)= nr\ V(A,r).
Два последних вида статистик при необходимости могут содержать информацию не для отдельных атрибутов, а для множества атрибутов. например, для множества атрибутов А статистика содержит V(A, r), которая используется для оценки выполнения проекции по этому множеству.
Кроме информации об отношениях файл статистики хранит информацию об индексах.
1 HTi – число уровней индекса. /*Отлично от единицы для b-деревьев */
2 LBi – число блоков нижнего уровня индекса, то есть количество листьев.
/*Эти характеристики будем использовать для оценки выполнения запроса. Эффективность алгоритма обработки запроса А будем обозначать ЕА*/
При модификации данных в отношениях изменяется статистика. Возникает вопрос, когда необходимо записывать изменения в статистику. Если изменять статистику каждый раз при изменении основного отношения, то процесс записи или удаления кортежей будет занимать много времени. Если же в базе произошло множество изменений, не отразившихся в статистике, то оценка стратегий выполнения запросов может стать неверной, вследствие чего возрастает время выполнения запросов. Большинство систем обновляют статистику при каждой загрузке.
39.Алгоритмы выполнения селекции с одним условием равенства: линейный поиск, двоичный поиск, использование первичного индекса при поиске по ключу, использование первичного индекса при поиске по не ключевому атрибуту, использование вторичного индекса.
Существует несколько алгоритмов для выполнения селекции, характеризующиеся разной стоимостью выполнения.
А1. Линейный поиск. При этом читаются все блоки отношения, и проверяется каждая запись. Стоимость алгоритма рассчитывается ЕА1=br. /*Остальные варианты стоимости по этому алгоритму рассчитываются на основании эффективности поиска в файле, организованном в виде кучи. */
А2. Двоичный поиск. Этот поиск возможен при упорядочении записей в отношении. В этом случае стоимость выполнения запроса будет вычисляться по формуле

Первая часть (до плюса) представляет собой поиск блока с первой записью, удовлетворяющей заданному условию. Вторая часть: числитель количество записей, удовлетворяющих условию, вся вторая часть – число блоков, которые нужно считать для извлечения всех записей, - 1, так как один из этих блоков уже считан при нахождении первой записи.
Селекция с использование индекса.
Индексы можно рассматривать как путь к записи. Различают первичный и вторичный индексы. Первичный индекс соответствует порядку физического размещения записей. /*Разреженный или кластерный индекс */. Все остальные – вторичные индексы. /*Плотные индексы */.
А3. Селекция при использовании первичного индекса и условия равенства ключа. В этом случае нужно считать на один блок больше, чем число уровней в индексе, то есть весь путь по индексу + один блок отношения. Таким образом, эффективность поиска EA3=HTi+1.
А4. Селекция при использовании первичного индекса и условия равенства не ключа. В этом случае результатом селекции будет являться множество кортежей, то есть возникает необходимость считать более одного блока файла отношения
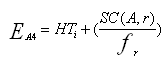
A5. Использование вторичного индекса при селекции. Основное отличие от предыдущих алгоритмов состоит в том, что записи, отвечающие условию, не располагаются подряд, поэтому эффективность будет равна ЕА5=HTi+SC(A,r).