

Парная линейная регрессионная модель
Рассмотрим парную линейную регрессионную модель взаимосвязи двух переменных, для которой функция регрессии φ(х)линейна. Обозначим черезyxусловную среднюю признакаYв генеральной совокупности при фиксированном значенииxпеременнойХ. Тогда уравнение регрессии будет иметь вид:
yx = ax + b, гдеa–коэффициент регрессии(показатель наклона линии линейной регрессии). Коэффициент регрессии показывает, на сколько единиц в среднем изменяется переменнаяYпри изменении переменнойХна одну единицу. С помощью метода наименьших квадратов получают формулы, по которым можно вычислять параметры линейной регрессии:
Таблица 1. Формулы для расчета параметров линейной регрессии
|
Свободный член b |
Коэффициент регрессии a |
Коэффициент детерминации |
|
|
|
|
|
Проверка гипотезы о значимости уравнения регрессии | ||
|
Н0:
|
Н1:
|
|
|
| ||

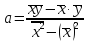




 ,
,
 ,
,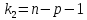 ,
Приложение 7 (для линейной регрессии
р = 1)
,
Приложение 7 (для линейной регрессии
р = 1)Направление связи между переменными определяется на основании знака коэффициента регрессии. Если знак при коэффициенте регрессии положительный, связь зависимой переменной с независимой будет положительной. Если знак при коэффициенте регрессии отрицательный, связь зависимой переменной с независимой является отрицательной (обратной).
|
|
|
|
Рис. 2. Понятие отклонения (линейная регрессия) |
Рис. 3. Графическая интерпретация коэффициента детерминации (линейная регрессия) |


Для анализа общего качества уравнения регрессии используют коэффициент детерминации R2, называемый также квадратом коэффициента множественной корреляции. Коэффициент детерминации (мера определенности) всегда находится в пределах интервала [0;1]. Если значениеR2близко к единице, это означает, что построенная модель объясняет почти всю изменчивость соответствующих переменных. И наоборот, значениеR2 близкое к нулю, означает плохое качество построенной модели.
Коэффициент детерминации R2показывает, на сколько процентов найденная функция регрессии описывает
связь между исходными значениямиYиХ. На рис. 3 показана
найденная функция регрессии описывает
связь между исходными значениямиYиХ. На рис. 3 показана – объясненная регрессионной моделью
вариация и
– объясненная регрессионной моделью
вариация и - общая вариация. Соответственно, величина
- общая вариация. Соответственно, величина показывает, сколько процентов вариации
параметраYобусловлены факторами,
не включенными в регрессионную модель.
показывает, сколько процентов вариации
параметраYобусловлены факторами,
не включенными в регрессионную модель.
При высоком значении коэффициента
детерминации
 75%)
можно делать прогноз
75%)
можно делать прогноз для конкретного значения
для конкретного значения в пределах диапазона исходных данных.
При прогнозах значений, не входящих в
диапазон исходных данных, справедливость
полученной модели гарантировать нельзя.
Это объясняется тем, что может проявиться
влияние новых факторов, которые модель
не учитывает.
в пределах диапазона исходных данных.
При прогнозах значений, не входящих в
диапазон исходных данных, справедливость
полученной модели гарантировать нельзя.
Это объясняется тем, что может проявиться
влияние новых факторов, которые модель
не учитывает.
Оценка значимости уравнения регрессии
осуществляется с помощью критерия
Фишера (см. табл. 1). При условии
справедливости нулевой гипотезы критерий
имеет распределение Фишера с числом
степеней свободы
 ,
,
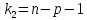 (для парной линейной регрессиир =
1). Если нулевая гипотеза отклоняется,
то уравнение регрессии считается
статистически значимым. Если нулевая
гипотеза не отклоняется, то признается
статистическая незначимость или
ненадежность уравнения регрессии.
(для парной линейной регрессиир =
1). Если нулевая гипотеза отклоняется,
то уравнение регрессии считается
статистически значимым. Если нулевая
гипотеза не отклоняется, то признается
статистическая незначимость или
ненадежность уравнения регрессии.
Пример 1. В механическом цехе анализируется структура себестоимости продукции и доля покупных комплектующих. Было отмечено, что стоимость комплектующих зависит от времени их поставки. В качестве наиболее важного фактора, влияющего на время поставки, выбрано пройденное расстояние. Провести регрессионный анализ данных о поставках:
|
Расстояние, миль |
3,5 |
2,4 |
4,9 |
4,2 |
3,0 |
1,3 |
1,0 |
3,0 |
1,5 |
4,1 |
|
Время, мин |
16 |
13 |
19 |
18 |
12 |
11 |
8 |
14 |
9 |
16 |
Для проведения регрессионного анализа:
построить график исходных данных, приближенно определить характер зависимости;
выбрать вид функции регрессии и определить численные коэффициенты модели методом наименьших квадратов и направление связи;
оценить силу регрессионной зависимости с помощью коэффициента детерминации;
оценить значимость уравнения регрессии;
сделать прогноз (или вывод о невозможности прогнозирования) по принятой модели для расстояния 2 мили.
|
|
1. Построенные точки не находятся точно на линии: помимо расстояния на время поставки влияют пробки на дорогах, время суток, дорожные работы, погода, квалификация водителя, вид транспорта. Но эти точки собраны вдоль прямой линии, поэтому можно предположить линейную положительную связь между параметрами. |

2. Вычислим суммы, необходимые для расчета коэффициентов уравнения линейной регрессии и коэффициента детерминации R2:
|
№ |
|
|
|
|
|
|
|
|
|
|
1 |
3,5 |
16 |
|
12,25 |
56,00 |
|
15,22 |
2,63 |
5,76 |
|
2 |
2,4 |
13 |
|
5,76 |
31,20 |
|
12,30 |
1,70 |
0,36 |
|
3 |
4,9 |
19 |
|
24,01 |
93,10 |
|
18,95 |
28,59 |
29,16 |
|
4 |
4,2 |
18 |
|
17,64 |
75,60 |
|
17,09 |
12,15 |
19,36 |
|
5 |
3,0 |
12 |
|
9,00 |
36,00 |
|
13,89 |
0,08 |
2,56 |
|
6 |
1,3 |
11 |
|
1,69 |
14,30 |
|
9,37 |
17,88 |
6,76 |
|
7 |
1,0 |
8 |
|
1,00 |
8,00 |
|
8,57 |
25,27 |
31,36 |
|
8 |
3,0 |
14 |
|
9,00 |
42,00 |
|
13,89 |
0,09 |
0,16 |
|
9 |
1,5 |
9 |
|
2,25 |
13,50 |
|
9,90 |
13,67 |
21,16 |
|
10 |
4,1 |
16 |
|
16,81 |
65,60 |
|
16,82 |
10,36 |
5,76 |
|
Σ |
28,9 |
136 |
|
99,41 |
435,30 |
|
– |
112,42 |
122,40 |

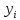

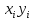

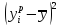
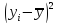
 ;
;
 ;
; ;
; .
.
Искомая
регрессионная зависимость имеет вид:
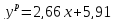 .
Определяем направление связи между
переменными: знак коэффициента регрессии
положительный, следовательно, связь
также является положительной, что
подтверждает графическое предположение.
.
Определяем направление связи между
переменными: знак коэффициента регрессии
положительный, следовательно, связь
также является положительной, что
подтверждает графическое предположение.
3. Вычислим
коэффициент детерминации:
 или 92%. Таким образом, линейная модель
объясняет 92% вариации времени поставки,
что означает правильность выбора фактора
(расстояния). Не объясняется 8% вариации
времени, которые обусловлены остальными
факторами, влияющими на время поставки,
но не включенными в линейную модель
регрессии.
или 92%. Таким образом, линейная модель
объясняет 92% вариации времени поставки,
что означает правильность выбора фактора
(расстояния). Не объясняется 8% вариации
времени, которые обусловлены остальными
факторами, влияющими на время поставки,
но не включенными в линейную модель
регрессии.
4. Проверим
значимость уравнения регрессии:

Т.к.
 – уравнение
регрессии (линейной модели) статистически
значимо.
– уравнение
регрессии (линейной модели) статистически
значимо.
5. Решим задачу прогнозирования. Поскольку коэффициент детерминации R2 имеет достаточно высокое значение и расстояние 2 мили, для которого надо сделать прогноз, находится в пределах диапазона исходных данных, то можно сделать прогноз:
 мин.
мин.
Регрессионный анализ удобно проводить с помощью возможностей Exel.Режим работы "Регрессия" служит для расчета параметров уравнения линейной регрессии и проверки его адекватности исследуемому процессу. В диалоговом окне следует заполнить следующие параметры:
Входной интервал Y- это диапазон данных по результативному признаку, он должен состоять из одного столбца.
Входной интервал X- это диапазон ячеек, содержащих значения факторов (независимых переменных). Число входных диапазонов (столбцов)
 16.
16.Флажок Метки, устанавливается в том случае, если в первой строке диапазона стоит заголовок.
Флажок Уровень надежности активизируется, если в поле, находящееся рядом с ним необходимо ввести уровень надежности, отличный от установленного по умолчанию (95%).
Константа ноль.Данный флажок необходимо установить, если линия регрессии должна пройти через начало координат (b = 0).
Флажки в группе ОстаткииГрафик остатковустанавливаются, если необходимо включить в выходной диапазон соответствующие столбцы или графики.
Пример 2. Выполнить задание примера 1 с помощью режима "Регрессия" Exel.
|
ВЫВОД ИТОГОВ |
| ||||
|
|
| ||||
|
Регрессионная статистика | |||||
|
Множественный R |
0,958275757 | ||||
|
R-квадрат |
0,918292427 | ||||
|
Нормированный R-квадрат |
0,90807898 | ||||
|
Стандартная ошибка |
1,11809028 | ||||
|
Наблюдения |
10 | ||||
|
|
Коэффициенты |
Стандартная ошибка |
t-статистика |
P-Значение | |
|
Y-пересечение |
5,913462144 |
0,884389599 |
6,686489927 |
0,00015485 | |
|
Переменная X 1 |
2,65970168 |
0,280497238 |
9,482095791 |
1,26072E-05 | |
Рассмотрим представленные в таблице результаты регрессионного анализа.
Величина R-квадрат, называемая также мерой определенности, характеризует качество полученной регрессионной прямой. Это качество выражается степенью соответствия между исходными данными и регрессионной моделью (расчетными данными). В нашем примере мера определенности равна 0,91829, что говорит об очень хорошей подгонке регрессионной прямой к исходным данным и совпадает с коэффициентом детерминации R2, вычисленным по формуле.
Множественный R - коэффициент множественной корреляции R - выражает степень зависимости независимых переменных (X) и зависимой переменной (Y) и равен квадратному корню из коэффициента детерминации. В простом линейном регрессионном анализе множественный коэффициент R равен линейному коэффициенту корреляции (r = 0,958).
Коэффициенты линейной модели: Y-пересечение выводит значение свободного члена b, а переменная Х1 – коэффициента регрессии а. Тогда уравнение линейной регрессии:
у = 2,6597x + 5,9135 (что хорошо согласуется с результатами расчета в примере 1).
Далее проверим значимость коэффициентов регрессии: a и b. Сравнивая попарно значения столбцов Коэффициенты и Стандартная ошибка в таблице, видим, что абсолютные значения коэффициентов больше, чем их стандартные ошибки. К тому же эти коэффициенты являются значимыми, о чем можно судить по значениям показателя Р-значение, которые меньше заданного уровня значимости α=0,05.
|
Наблюдение |
Предсказанное Y |
Остатки |
Стандартные остатки |
|
|
1 |
15,22241803 |
0,777581975 |
0,737641894 | |
|
2 |
12,29674618 |
0,703253823 |
0,667131568 | |
|
3 |
18,94600038 |
0,053999622 |
0,051225961 | |
|
4 |
17,0842092 |
0,915790799 |
0,868751695 | |
|
5 |
13,89256718 |
-1,892567185 |
-1,795356486 | |
|
6 |
9,371074328 |
1,628925672 |
1,545256778 | |
|
7 |
8,573163824 |
-0,573163824 |
-0,543723571 | |
|
8 |
13,89256718 |
0,107432815 |
0,101914586 | |
|
9 |
9,903014664 |
-0,903014664 |
-0,8566318 | |
|
10 |
16,81823903 |
-0,818239033 |
-0,776210624 |
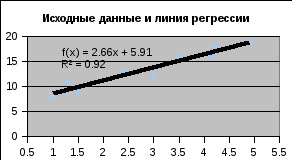
В таблице представлены результаты вывода остатков. При помощи этой части отчета мы можем видеть отклонения каждой точки от построенной линии регрессии. Наибольшее абсолютное значение остатка в данном случае - 1,89256, наименьшее - 0,05399. Для лучшей интерпретации этих данных строят график исходных данных и построенной линией регрессии. Как видно из построения, линия регрессии хорошо "подогнана" под значения исходных данных, а отклонения носят случайный характер.