

Лекции / Vortex
.docxТема 5. Особливості обробки соціологічної інформації за допомогою програми Vortex 8.0
Створення словника: різновиди змінних та способів їх побудови. Введення даних. Вторинні змінні. Описова статистика в Vortex 8.0. Розрахунок об’єму вибірки та визначення похибки репрезентативності. Екстраполяція даних на генеральну сукупність. Обробка різного роду запитань. Опрацювання табличних запитань, рангових методик та полярних профілів. Одновимірний, двовимірний та багатовимірний частковий аналіз. Регресивний, кластерний, детермінаційний та інші види багатовимірного аналізу. Особливості обробки обмежених та необмежених змінних. Аналіз статистичних взаємозв’язків.
Для розрахунки вибірки потрібно відкрити діалогове вікно «Дослідження» («Исследование») та з контекстного меню вибрати «Розрахунок вибірки» («Расчет выборки»)
-
Сторінка «Загальні розрахунки» («Общие расчеты») тут Ви можете розрахувати обсяг вибірки, помилку репрезентативності або бюджет. При цьому передбачається використання випадкової (власне випадковою, механічної, стратифікованої або кластерної вибірки).
-
Відомі величини (Известные величины): величини, які потрібні для розрахунків.
-
• Об’єм генеральної сукупності (Объем генеральной совокупности) - якщо невідомий, введіть 0.
• Дисперсія (Дисперсия) - показник варіації тієї ознаки, яка Вас цікавить. Якщо Вас цікавлять якісні ознаки (заміряні за номінальною або порядковою шкалою), то Ви можете встановити максимальну дисперсію для якісного ознаки - 0,25 Якщо ж Вас цікавить та чи інша кількісна ознака, то її дисперсію можна визначити:
а) за результатами вже наявних аналогічних досліджень.
б) вже після проведення дослідження.
• Ймовірність того, що значення дійсно знаходиться всередині вказаного інтервалу: при визначенні граничної помилки репрезентативності, середня помилка множиться на Т-критерій Стьюдента, що гарантує, з певною часткою ймовірності, що значення буде знаходиться в інтервалі ± гранична помилка.
• Ціна за одиницю спостереження або кластер - сума, яку Ви платите за опитування 1 людини або за опитування цілого кластера (наприклад шкільного класу, бригади або сім'ї).
-
Величини, які потрібно розрахувати (Рассчитываемые величины): треба вказати одну з них, а інші залишити нульовими.
-
Сторінка «Розрахунок дисперсії» («Расчет дисперсии») тут Ви можете за наявними даними розрахувати або уточнити дисперсію, щоб потім її використовувати в розрахунках на попередній сторінці.
-
Основний досліджуваний показник (Основной изучаемый показатель) – ознака, що Вас цікавить. Він може бути як кількісним (тоді - «розглядати як число»), так і якісним, тоді треба вибрати зі списку значення, що цікавить.
-
Групуюча ознака (Группирующий признак) - ознака, що визначає приналежність до страти або кластеру.
-
Сторінка «Страти, шари, райони» («Страты, слои, районы») дозволяє перевірити правильність стратифікованої вибірки за наявними даними. Для цього треба вибрати Змінну, яка містить страти і ввести дані по генеральній сукупності.
-
Дані по генеральної сукупності у вигляді % Ви можете ввести прямо в таблицю або вставити через буфер обміну (таблиця, що вставляється повинна містити дві колонки - назва страти і значення в генеральній сукупності, зрозуміло, значення повинні йти в тому ж порядку, а назви колонок копіювати не треба). Так само дані по генеральній сукупності можна було ввести і при визначенні відповідної змінної, в кожному значенні є розділ «Якщо змінна є контрольною».
-
«Запам'ятати генеральну»(«Запомнить генеральную») - програма запам'ятовує для цієї змінної дані по генеральній сукупності, і змінна стає контрольною.
-
Дані по вибірці програма бере з змінної.
-
Помилка і Вага / Коеф розраховуються кнопкою «Розрахувати».
-
«Помилка %» («Ошибка%») - це різниця між відсотком у генеральній і часткою в вибіркової сукупності.
-
«Вага / Коеф» («Вес/Коеф») - це відношення між відсотком у генеральній і відсотком в вибіркової сукупності. Якщо структура вибірки повністю відповідає структурі генеральної сукупності, то Вага складе 1. Однак, якщо вага не дорівнює 1, і вибірка не повністю відповідає генеральної сукупності, то Ви можете це легко виправити прямо на цій сторінці.
-
«Вага в змінну» («Веса в переменную») - формує нову змінну «Вага» і встановлює її як Вагової змінної. При цьому пропорції у генеральній і вибіркової сукупності стають приблизно однаковими.
-
Сторінка «Оцінка фактичної помилки» («Оценка фактической ошибки») дозволяє визначити максимальну фактичну помилку репрезентативності за сукупністю контрольних змінних.
-
«Контрольні змінні» («Контрольные переменные») - виберіть список контрольних змінних (по ним має бути введені значення для генеральної сукупності). Програма проведе порівняння по кожній з контрольних змінних між генеральної і вибіркової сукупностями і визначить максимальну і середню фактичну помилку, причому, якщо Ви вже скористалися зважуванням, то Ви зможете порівняти, як зменшилися помилки в результаті використання вагової змінної.
-
Поправочний коефіцієнт («Поправочный коэффициент») - відношення між максимальною фактичною помилкою і теоретичної помилкою випадкової вибірки. Чим більше максимальна фактична помилка в порівнянні з теоретичної, тим більше Ваша вибірка відхиляється від випадкової. Щоб програма враховувала це в подальших розрахунках, Вам потрібно буде вказати «Поправочний коефіцієнт для розрахунку помилки» на сторінці «Дослідження» головного вікна програми.
-
Уточнений поправочний коефіцієнт (Уточненный поправочный коэффициент) - використовуйте це значення до якості «Поправочний коефіцієнт для розрахунку помилки» на сторінці «Дослідження» головного вікна програми, якщо Ви використовуєте вагову змінну.
-
«Надіслати розподіл в Word»(«Отправить распределения в Word») - відправляє в Word таблиці з розподілом по контрольних змінним, щоб Ви наочно могли побачити по яким змінним більша або менша фактична помилка
-
«Копіювати розподіл в буфер обміну»( «Копировать распределения в буфер обмена»)- те саме для буфера обміну, щоб вставити в іншу програму.
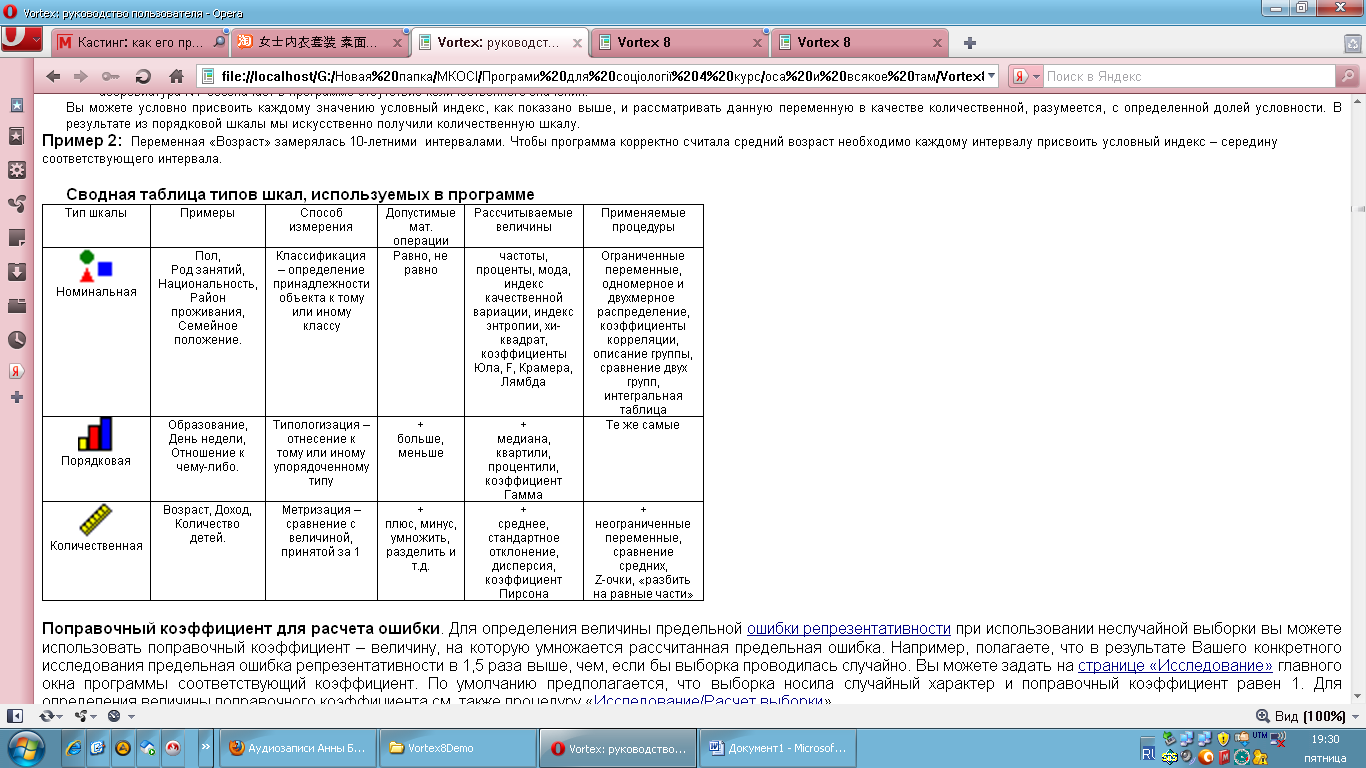
Тип змінної - основна властивість змінної в VORTEX. Впливає на особливості введення, зберігання та аналізу даних.
Версія 8.0. підтримує наступну структуру типів змінних:
- Альтернативна
-
Поліваріантна
-
Числова
-
Строкова
Альтернативна змінна передбачає можливість вибору тільки одного значення з обмеженого списку.
Приклад:
1. Змінна «Стать»: значення «чоловічий», «жіночий»
2. Змінна «Освіта»: значення «початкове», «неповну середню», «середню загальну» і т.д.
3. Змінна «Вік»: значення «до 20 років», «20-29», «30-39», «40-49» і т.д.
Оскільки у відповіді на альтернативний питання одна людина може дати тільки одну відповідь, то число відповідей і число відповідачив збігається.
Максимально можлива кількість значень, які може приймати альтернативна змінна - 255.
Поліваріантна змінна передбачає можливість вибору з обмеженого списку декількох значень одночасно. Вона застосовується в програмі для опрацювання питань «типу меню», які передбачають можливість вибору декількох варіантів відповіді одночасно.
Приклад:
1. Змінна «Домашня тварина»: значення «кішка», «собака», «рибки», «пташки», «гризуни», «плазуни» і т.д.
2. Змінна «Відомі марки пива»: значення «Балтика», «Бочкарьов», «Старий мельник», «Невське», «Золота бочка» і т.д.
Тут опитаний може мати одночасно кілька домашніх тварин, знати кілька марок пива.
Числова змінна як значення має числа. Такими будуть, наприклад, змінні «Дохід» та «Вік» якщо їх значеннями виступають конкретні числа. Проте якщо Ви плануєте, наприклад, «Вік» вимірювати інтервалами, то Вам краще використовувати альтернативну змінну. Числова змінна завжди має кількісну шкалу і допускає найрізноманітніші статистичні розрахунки.
Строкова змінна як значення має текстові рядки - унікальні набори символів. Використання строкових змінних має сенс лише в тому випадку, якщо кожне значення дійсно унікальне і не має повторення в інших об'єктах. Такими, наприклад, будуть змінні «ПІБ» і «Домашній телефон респондента». Якщо ж значення мають тенденцію повторюватися, то більш ефективно буде використання змінної альтернативного або поліваріантного типу.
Приклад: В анкеті задається питання: «Які марки автомобілів Вам подобаються?». Передбачається, що відповідь респондент дасть у відкритій формі (немає стандартних варіантів). Оформити таке питання строкової змінної буде неправильно, оскільки респонденти будуть повторюватися. Краще використовувати в цьому випадку змінну поліваріантного типу.
При запуску програми або відкриття нового файлу програма переносить Вас на сторінку «Дослідження» головного вікна програми. Ви можете переключиться на дану сторінку, вибравши відповідний пункт меню. Сторінка містить загальну інформацію по вибраному дослідженню:
-
Розділ «Опис дослідження»: тут Ви можете вказати розгорнуту формулювання назви дослідження, ПІБ авторів, терміни проведення, метод збору інформації, об'єкт і предмет дослідження, тип вибірки і т.п.
-
За допомогою кнопки «Word» Ви можете надіслати загальну інформацію з дослідження в Microsoft Word.
-
Кнопка «Копировать» відправить інформацію з дослідження в буфер обміну, звідки Ви можете її вставити в будь-яку іншу програму.
-
Кнопка «Шрифт» - вибір шрифту для виділеного фрагмента тексту.
-
Кнопка «Параграф» - визначення вигляду параграфів для виділеного фрагмента тексту.
-
Кнопка «Паролі (доступ)» дозволяє встановити або змінити пароль на дослідження або обмежити доступ до інформації. Для того, щоб змінити пароль Вам буде потрібно ввести попередній пароль адміністратора і вказати нові паролі. Якщо ви встановите на дослідження паролі, то наступного разу, при спробі відкрити дослідження, програма зажадає вказати пароль і дозволить скористатися тільки тими процедурами, які цей пароль дозволяє. Зрозуміло, паролі необхідно запам'ятати, тому не рекомендується зайвий раз встановлювати пароль без необхідності.
-
Розділ «Структурні змінні» служить для того, щоб можна було вказати програмі на кілька важливих змінних, які відображають внутрішній устрій бази даних. До їх числа відносяться:
Ø Ідентифікатор об'єктів - змінна, в якій містяться номери об'єктів або їх коди, наприклад «Прізвище, Ім'я, По батькові» або «Номер анкети» і т.п. Така змінна може бути необмеженого - строкового або числового типу;
Ø Регіон (структура) - це змінна, в якій містяться назви регіонів (будь-яких територіальних одиниць - областей, міст, районів і т.п.) або назви структурних підрозділів організації (цехи, відділи, і т.п.). Така змінна повинна бути альтернативного типу;
Ø Період часу - це змінна, в якій можуть міститися назви періодів часу. Така змінна повинна бути альтернативного типу;
Ø Сегменти - це змінна, в якій можуть міститися назви цільових груп або сегментів. Така змінна повинна бути альтернативного типу;
Ø Вагова змінна - це змінна, в якій для кожного об'єкта вказано його вага в масиві. Вагова змінна використовується в тому випадку, коли об'єкти мають різну вагу, наприклад, для ремонту вибірки. Така змінна повинна бути числового типу.
Якщо у Вашому дослідженні є подібні змінні, то рекомендується їх вказати. Для того, щоб встановити або змінити відповідну структурну змінну треба двічі клацнути мишею по відповідній рядку або натиснути кнопку «Вибрати». Для того, щоб відмовитися від визначення структурних змінних натисніть кнопку «Очистити».
Кластерний аналіз
За допомогою даної процедури Ви можете провести багатовимірну класифікацію об'єктів, тобто класифікацію об'єктів одночасно по декількох змінним. Під кластером розуміється група об'єктів, які розташовані в багатовимірному просторі змінних максимально близько один до одного і при цьому максимально віддалені від об'єктів з інших груп. Центр кластера - найбільш типовий представник даного кластера (його геометричний центр). За характеристиками центру кластера можна судити про все кластері.
Існує багато методів розділення об'єктів на кластери. В даний час в програмі реалізована тільки одна процедура «К - середні», що представляє собою найбільш швидкий алгоритм кластерного аналізу. У загальних словах алгоритм полягає в наступному:
1. У багатовимірному просторі як початкових центрів кластерів вибираються випадкові об'єкти (або об'єкти, найбільш віддалені один від одного).
2. Кожен об'єкт відноситься до того кластеру, до центру якого він ближче всього.
3. Коли всі об'єкти віднесені до того чи іншого кластеру їх центри перераховуються: розраховується геометричний центр кластера.
4. Знову повторюються етапи 2 і 3: кожен об'єкт належить до того чи іншого кластеру та центри кластерів знову перераховуються, цей процес називається «ітерація» (наближення).
5. Процес повторюється, поки зміни в центрах кластерів не стануть рівні 0 (досягнуто оптимальне рішення) або не буде перевищено допустиму кількість ітерацій. Сторінка «Змінні» дозволяє вибрати змінні, які будуть брати участь в кластерному аналізі та задати основні параметри.
Регресійний аналіз.
Сторінка «Змінні» дозволяє вибрати зі списку «Змінні дослідження» ті змінні, які будуть входити до складу регресійного рівняння.
«Залежна змінна Y»: вивчалася змінна, повинна бути кількісної і нормально розподіленої (більшість об'єктів групуються навколо середнього).
«Незалежні змінні Х»: фактори, які гіпотетично впливають на Y. До незалежним змінним X зазвичай застосовуються такі вимоги:
· Вони повинні бути кількісні, але так само допустимі дихотомічні (2 значення) і псевдо-кількісні змінні.
· Вони повинні бути нормально розподіленими.
· Вони повинні бути незалежними один від одного, тобто слабо корелювати між собою.
· Їх вплив на Y повинно носити прямо або обернено пропорційний характер. Тобто зі зростанням X, значення Y повинне постійно пропорційно збільшуватися, або, навпаки, зменшуватися. Якщо ж зв'язок носить криволінійний характер, тобто, наприклад, спочатку з ростом X значення Y збільшується, а потім зменшується, то використання подібної змінної буде неадекватно.
· З ростом X ступінь варіації Y повинна залишатися постійною.
· Мінлива Y не повинна бути лінійної комбінацією змінних X.
· Зв'язок між змінними X і Y не повинна бути занадто очевидною.
Для вибору перетягніть мишею змінні з лівого загального списку в правий. Після відбору змінних натисніть кнопку «Розрахувати»
Рекомендується зберігати результати регресії у вигляді нових змінних і проводити розрахунки тільки коли Ви задоволені якістю регресійного рівняння за всіма параметрами. Якщо Ви не задоволені якістю рівняння, то спробуйте використовувати інші незалежні змінні X, для чого поверніться на сторінку «Змінні».
Середні: розрахунок або прогноз ведеться для середнього по сукупності. І Індивідуальні: розрахунок або прогноз ведеться для індивідуального об'єкта. У рядку «Формула» Ви можете взяти готову формулу для копіювання. Будь-які результати регресійного аналізу у вигляді таблиць або графіків Ви завжди можете надіслати в Word або копіювати в буфер обміну