

3.6. Факторный анализ
Введение в факторный анализ
В течение последних лет факторный анализ нашел свое применение среди широкого круга исследователей в основном благодаря развитию высокоскоростных компьютеров и пакетов статистических программ (например, DATATEXT, BMD, OSIRIS, SAS и SPSS). Это также коснулось большой группы пользователей, не имеющих соответствующей математической подготовки, но, тем не менее, заинтересованных в использовании потенциальных возможностей факторного анализа в своих исследованиях (Harman, 1976; Horst, 1965; Lawley и Maxswel, 1971; Mulaik, 1972).
Факторный анализ предполагает, что изучаемые переменные представляют собой линейную комбинацию некоторых скрытых (латентных) ненаблюдаемых факторов. Иными словами, существует система факторов и система изучаемых переменных. Определенная зависимость между этими двумя системами позволяет посредством факторного анализа с учетом имеющейся зависимости получать выводы по изучаемым переменным (факторам). Логическая сущность этой зависимости состоит в том, что каузальная система факторов (система независимых и зависимых переменных) всегда имеет уникальную корреляционную систему изучаемых переменных, а не наоборот. Только при жестко ограниченных условиях, налагаемых на факторный анализ, возможна недвусмысленная интерпретация каузальных структур по факторам на наличие корреляции между изучаемыми переменными. Кроме этого, существуют проблемы и другой природы. Например, при сборе эмпирических данных возможно допущение разного рода ошибок и неточностей, что в свою очередь затрудняет работу по выделению скрытых ненаблюдаемых параметров и их дальнейшего исследования.
Что же такое факторный анализ? Факторный анализ относится к множеству статистических техник, основная задача которых состоит в представлении множества изучаемых признаков в виде сокращенной системы гипотетических переменных. Факторный анализ — исследовательский эмпирический метод, который преимущественно находит свое применение в социальных и психологических дисциплинах.
В качестве примера использования факторного анализа можно рассмотреть изучение свойств личности с помощью психологических тестов. Свойства личности не поддаются прямому измерению, о них можно судить только на основании поведения человека, ответов на те или иные вопросы и т.д. Для объяснения собранных эмпирических данных их результаты подвергаются факторному анализу, который и позволяет выявить те личностные свойства, которые оказывали влияние на поведение испытуемых в проведенных опытах.
Первым этапом факторного анализа, как правило, является выбор новых признаков, которые являются линейными комбинациями прежних и «вбирают» в себя большую часть общей изменчивости наблюдаемых данных, а поэтому передают большую часть информации, заключенной в первоначальных наблюдениях. Обычно это осуществляют с помощью метода главных компонент,хотя иногда используют и другие приемы (например, метод главных факторов, метод максимального правдоподобия).
Метод главных компонент– статистический прием, позволяющий преобразовывать исходные переменные в их линейную комбинацию (GeorgH.Dunteman). Цель метода – получить сокращенную систему исходных данных, которая намного проще для понимания и дальнейшей статистической обработки. Этот подход был предложен Пирсоном (1901) и независимо от него получил свое дальнейшее развитие у Хотеллинга (1933). Автор пытался минимизировать использование матричной алгебры при работе с данным методом.
Основная цель метода главных компонент – выделение первичных факторов и определение минимального числа общих факторов, которые удовлетворительно воспроизводят корреляции между изучаемыми переменными. Результат данного шага – матрица коэффициентов факторных нагрузок, представляющих собой в ортогональном случае коэффициенты корреляции между переменными и факторами. При определении числа выделяемых факторов используется следующий критерий: выделяются только факторы с собственными значениями больше указанной константы (как правило, единицы).
Однако обычно факторы, полученные методом главных компонент, не поддаются достаточно наглядной интерпретации. Поэтому следующим шагом факторного анализа является преобразование (вращение) факторов таким образом, чтобы облегчить их интерпретацию. Вращение факторов состоит в нахождении наиболее простой факторной структуры, то есть такого варианта оценки факторных нагрузок и остаточных дисперсий, который и дает возможность содержательно интерпретировать общие факторы и нагрузки.
Наиболее часто исследователями в качестве метода вращения используется метод варимакс. Это метод, позволяющий, с одной стороны, за счет минимизации разброса квадратов нагрузок для каждого фактора, получить упрощенную факторную структуру за счет увеличения больших и уменьшения малых факторных нагрузок, с другой стороны.
Итак, основные цели факторного анализа:
сокращение числа переменных (редукция данных);
определение структуры взаимосвязей между переменными, т.е. классификация переменных.
Поэтому факторный анализ используется или как метод сокращения данных или как метод классификации.
Практические примеры и советы по применению факторного анализа можно, найти в книге Стивенса (Stevens, 1986); более подробное описание приводят Кули и Лонес (Cooley, Lohnes, 1971); Харман (Harman, 1976); Ким и Мюллер (Kim, Mueller, 1978a, 1978b); Лоули и Максвелл (Lawley, Maxwell, 1971); Линдеман, Меренда и Голд (Lindeman, Merenda, Gold, 1980); Моррисон (Morrison, 1967) и Мулэйк (Mulaik, 1972). Интерпретация вторичных факторов в иерархическом факторном анализе, как альтернатива традиционному вращению факторов, дана Верри (Wherry, 1984).
Вопросы подготовки данных для применения
факторного анализа
Рассмотрим ряд вопросов и кратких ответов в рамках использования факторного анализа.
Какой уровень измерений требует факторный анализ или, иными словами, в каких шкалах измерений должны представляться данные для факторного анализа?
Факторный анализ требует, чтобы переменные были представлены в интервальной шкале (Stevens, 1946) и отвечали нормальному распределению. Это требование предполагает также, что в качестве входных данных используются ковариационные или корреляционные матрицы.
Матрица, содержащая переменные, представленные порядковой шкалой, используется в факторном анализе исключительно в эвристических целях. Следует учитывать, что существуют методы неметрического шкалирования для установления связи между неметрическими переменными.
Должен ли исследователь избегать использования факторного анализа, когда метрическая основа переменных определена неточно, т.е. данные представлены в порядковой шкале?
Нет необходимости. Многие переменные, представляющие, например, измерения мнений испытуемых по большому количеству тестов, не имеют точно установленной метрической базы. Однако, в общем, предполагается, что многие «порядковые переменные» могут содержать числовые значения, не искажающие и даже сохраняющие основные свойства изучаемого признака. Задачи исследователя: а) правильно определить число рефлексивно выделяемых порядков (уровней); б) учесть, что сумма допущенных искажений будет включена в корреляционную матрицу, являющуюся основой входных данных факторного анализа; в) коэффициенты корреляции закрепляются в качестве «порядковых» искажений в измерениях (Labovitz, 1967, 1970;Kim, 1975).
Долгое время считалось, что искажения назначаются числовым значениям именно порядковых категорий. Однако это необоснованно, поскольку и для метрических величин возможны искажения, пусть даже минимальные, в процессе проведения эксперимента. В факторном анализе результаты зависят от возможного допущения ошибок, получаемых в процессе измерения, а не их происхождения и соотнесения к данным определенного типа шкал.
Можно ли использовать факторный анализ для номинальных (дихотомических) переменных?
Многие исследователи
утверждают, что использовать факторный
анализ для номинальных переменных очень
удобно. Во-первых, дихотомические
значения (значения, равные «0» и «1»)
исключают выбор каких-либо иных, отличных
от них. Во-вторых, как результат,
коэффициент связи
![]() является эквивалентом коэффициента
корреляции Пирсона, который и выступает
в качестве числового значения переменной
для факторного анализа.
является эквивалентом коэффициента
корреляции Пирсона, который и выступает
в качестве числового значения переменной
для факторного анализа.
Однако однозначно положительного ответа на данный вопрос нет. Дихотомические переменные сложно выразить в рамках аналитической факторной модели: каждая переменная имеет значение весовой нагрузки, по крайней мере, двух основных факторов — общего и частного (Kim,Muller). Даже если эти факторы имеют два значения (что довольно редко встречается в реальных факторных моделях), то итоговые результаты в наблюдаемых переменных должны содержать, как минимум, четыре различных значения, которые, в свою очередь, и оправдывают противоречивость использования номинальных переменных. Поэтому факторный анализ для таких переменных используется с целью получения ряда эвристических критериев.
Сколько должно быть переменных для каждого гипотетически построенного фактора?
Предполагается, что для каждого фактора должно быть, по крайней мере, три переменные. Но это требование опускается, если факторный анализ используется для подтверждения какой-либо гипотезы. В общем, исследователи едины в том, что необходимо иметь, по крайней мере, вдвое больше переменных, чем факторов.
Еще один момент касательно данного вопроса. Чем больше размер выборки, тем достовернее значение критерия ХИ-квадрат. Результаты считаются статистически значимыми, если выборка включает как минимум 51 наблюдение. Таким образом:
N-n-150,(3.33)
где N – размер выборки (число измерений),
n – количество переменных (Lawley, Maxwell, 1971).
Это, конечно, только общее правило.
Какой смысл имеет знак факторной нагрузки?
Сам знак не имеет существенного значения и не существует пути для оценки значимости связи между переменной и фактором. Однако знаки переменных, входящих в фактор, имеют специфическое значение относительно знаков других переменных. Различные знаки просто означают, что переменные связаны с фактором в противоположных направлениях.
Например, по результатам факторного анализа было получено, что для пары качеств открытый-замкнутый (многофакторный опросник Кетелла) имеют место соответственно положительная и отрицательная весовые нагрузки. Тогда говорят, что доля качестваоткрытый, в выделенном факторе больше, чем доля качествазамкнутый.
Главные компоненты и факторный анализ
Факторный анализ как метод редукции данных
Предположим, что проводится (до некоторой степени "глупое") исследование, в котором измеряется рост ста людей в метрах и сантиметрах. Таким образом, имеются две переменные. Если далее исследовать, например, влияние разных пищевых добавок на рост, будет ли целесообразным использовать обе переменные? Вероятно, нет, т.к. рост является одной характеристикой человека, независимо от того, в каких единицах он измеряется.
Предположим, что измеряется удовлетворенность людей жизнью с помощью опросника, содержащего различные пункты. Задаются, например, вопросы: удовлетворены ли люди своим хобби (пункт 1) и как интенсивно они им занимаются (пункт 2). Результаты преобразуются так, что средние по уровню ответы (например, для удовлетворенности) соответствуют значению 100, в то время как ниже и выше средних ответов расположены меньшие и большие значения, соответственно. Две переменные (ответы на два разных пункта) коррелированы между собой. Из высокой коррелированности двух этих переменных можно сделать вывод об избыточности двух пунктов опросника. Это, в свою очередь, позволяет осуществить объединение двух переменных в один фактор.
Новая переменная (фактор) будет включать в себя наиболее существенные черты обеих переменных. Итак, фактически, выполнено сокращение исходного числа переменных и осуществлена замена двух переменных одной. Отметим, что новый фактор (переменная) в действительности является линейной комбинацией двух исходных переменных.
Пример, в котором две коррелированные переменные объединены в один фактор, показывает главную идею факторного анализа или, более точно, анализа главных компонент. Если же пример с двумя переменными распространить на большее число переменных, то вычисления становятся сложнее, однако основной принцип представления двух или более зависимых переменных одним фактором остается в силе.
Метод главных компонент
Анализ главных компонент является методом сокращения или редукции данных, т.е. методом сокращения числа переменных. Возникает естественный вопрос: сколько факторов следует выделять? Отметим, что в процессе последовательного выделения факторов они включают в себя все меньше и меньше изменчивости. Решение о том, когда следует остановить процедуру выделения факторов, главным образом зависит от точки зрения на то, что считать малой "случайной" изменчивостью. Это решение достаточно произвольно, однако имеются некоторые рекомендации, позволяющие рационально выбрать число факторов (см. раздел Собственные значения и число выделяемых факторов).
В случае, когда имеются более двух переменных, можно считать, что они определяют трехмерное "пространство" точно так же, как две переменные определяют плоскость. Если имеется три переменные, то можно построить трехмерную диаграмму рассеяния (см. рис. 3.10).
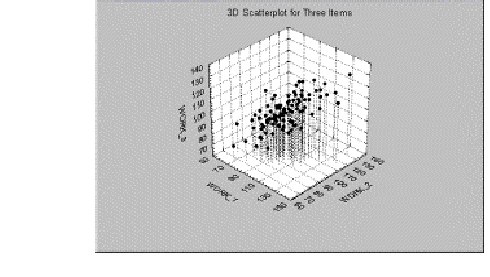
Рис. 3.10. Трехмерная диаграмма рассеяния признака
Для случая более трех переменных, становится невозможным представить точки на диаграмме рассеяния, однако логика вращения осей с целью максимизации дисперсии нового фактора остается прежней.
После того, как найдена линия, для которой дисперсия максимальна, вокруг нее остается некоторый разброс данных и процедуру естественно повторить. В анализе главных компонент именно так и делается: после того, как первый фактор выделен, то есть, после того, как первая линия проведена, определяется следующая линия, максимизирующая остаточную вариацию (разброс данных вокруг первой прямой), и т.д. Таким образом, факторы последовательно выделяются один за другим. Так как каждый последующий фактор определяется так, чтобы максимизировать изменчивость, оставшуюся от предыдущих, то факторы оказываются независимыми друг от друга (некоррелированными или ортогональными).
Собственные значения и число выделяемых факторов
Рассмотрим некоторые стандартные результаты анализа главных компонент. При повторных вычислениях выделяются факторы с все меньшей и меньшей дисперсией. Для простоты изложения считают, что обычно работа начинается с матрицы, в которой дисперсии всех переменных равны 1,0. Поэтому общая дисперсия равна числу переменных. Например, если имеется 10 переменных и дисперсия каждой из них равна 1, то наибольшая изменчивость, которая потенциально может быть выделена, равна 10 раз по 1.
Предположим, что при изучении степени удовлетворенности жизнью включено 10 пунктов для измерения различных аспектов удовлетворенности домашней жизнью и работой. Дисперсия, объясненная последовательными факторами, представлена в таблице 3.14:
Таблица 3. 14
Таблица собственных значений
|
STATISTICA ФАКТОРНЫЙ АНАЛИЗ |
Собственные значения (factor.sta) Выделение: Главные компоненты | |||
|
Значение |
Собственные значения |
% общей дисперсии |
Кумулят. собств. знач. |
Кумулят. % |
|
1 |
6.118369 |
61.18369 |
6.11837 |
61.1837 |
|
2 |
1.800682 |
18.00682 |
7.91905 |
79.1905 |
|
3 |
.472888 |
4.72888 |
8.39194 |
83.9194 |
|
4 |
.407996 |
4.07996 |
8.79993 |
87.9993 |
|
5 |
.317222 |
3.17222 |
9.11716 |
91.1716 |
|
6 |
.293300 |
2.93300 |
9.41046 |
94.1046 |
|
7 |
.195808 |
1.95808 |
9.60626 |
96.0626 |
|
8 |
.170431 |
1.70431 |
9.77670 |
97.7670 |
|
9 |
.137970 |
1.37970 |
9.91467 |
99.1467 |
|
10 |
.085334 |
.85334 |
10.00000 |
100.0000 |
Во втором столбце таблицы 3. 14. (Собственные значения) представлена дисперсия нового, только что выделенного фактора. В третьем столбце для каждого фактора приводится процент от общей дисперсии (в данном примере она равна 10) для каждого фактора. Как видно, первый фактор (значение 1) объясняет 61 процент общей дисперсии, фактор 2 (значение 2) – 18 процентов, и т.д. Четвертый столбец содержит накопленную (кумулятивную) дисперсию.
Итак, дисперсии, выделяемые факторами, названы собственными значениями. Это название происходит из использованного способа вычисления.
Как только получена информация о том, сколько дисперсии выделил каждый фактор, можно возвратиться к вопросу о том, сколько факторов следует оставить. Как говорилось выше, по своей природе это решение произвольно. Однако имеются некоторые общеупотребительные рекомендации, и на практике следование им дает наилучшие результаты.
Критерии выделения факторов
Критерий Кайзера. Сначала отбираются только те факторы, собственные значения которых больше 1. По существу, это означает, что если фактор не выделяет дисперсию, эквивалентную, по крайней мере, дисперсии одной переменной, то он опускается. Этот критерий предложен Кайзером (Kaiser, 1960), и является наиболее широко используемым. В приведенном выше примере (см. табл. 3.14) на основе этого критерия следует сохранить только 2 фактора (две главные компоненты).
Критерий каменистой осыпи является графическим методом, впервые предложенным Кэттелем (Cattell, 1966). Он позволяет изобразить собственные значения в виде простого графика:

Рис. 3. 11. Критерий каменистой осыпи
Оба критерия были изучены подробно Брауном (Browne, 1968), Кэттелем и Джасперсом (Cattell, Jaspers, 1967), Хакстианом, Рожерсом и Кэттелем (Hakstian, Rogers, Cattell, 1982), Линном (Linn, 1968), Тюкером, Купманом и Линном (Tucker, Koopman, Linn, 1969). Кэттель предложил найти такое место на графике, где убывание собственных значений слева направо максимально замедляется. Предполагается, что справа от этой точки находится только «факториальная осыпь» («осыпь» – геологический термин, обозначающий обломки горных пород, скапливающиеся в нижней части скалистого склона). В соответствии с этим критерием можно оставить в рассмотренном примере 2 или 3 фактора.
Какому критерию все-таки следует отдавать предпочтение на практике? Теоретически, можно вычислить характеристики путем генерации случайных данных для конкретного числа факторов. Тогда можно увидеть, обнаружено с помощью используемого критерия достаточно точное число существенных факторов или нет. С использованием этого общего метода первый критерий (критерий Кайзера) иногда сохраняет слишком много факторов, в то время как второй критерий (критерий каменистой осыпи) иногда сохраняет слишком мало факторов; однако оба критерия вполне хороши при нормальных условиях, когда имеется относительно небольшое число факторов и много переменных.
На практике возникает важный дополнительный вопрос, а именно: когда полученное решение может быть содержательно интерпретировано. Поэтому обычно исследуется несколько решений с большим или меньшим числом факторов, и затем выбирается одно наиболее "осмысленное". Этот вопрос далее будет рассматриваться в рамках вращений факторов.
Общности
На языке факторного анализа доля дисперсии отдельной переменной, принадлежащая общим факторам (и разделяемая с другими переменными) называется общностью. Поэтому дополнительной работой, стоящей перед исследователем при применении этой модели, является оценка общностей для каждой переменной, т.е. доли дисперсии, которая является общей для всех пунктов. Тогда доля дисперсии, за которую отвечает каждый пункт, равна суммарной дисперсии, соответствующей всем переменным, минус общность (Harman, Jones, 1966).
Главные факторы и главные компоненты
Термин факторный анализ включает как анализ главных компонент, так и анализ главных факторов. Предполагается, что, в целом, известно сколько факторов следует выделить. Можно узнать (1) значимость факторов, (2) можно ли интерпретировать их разумным образом и (3) как это сделать. Чтобы проиллюстрировать, каким образом это может быть сделано, производятся действия "в обратном порядке", то есть, начинают с некоторой осмысленной структуры, а затем смотрят, как она отражается на результатах.
Основное различие двух моделей факторного анализа состоит в том, что в анализе главных компонент предполагается, что должна быть использована вся изменчивость переменных, тогда как в анализе главных факторов используется только изменчивость переменной, общая и для других переменных.
В большинстве случаев эти два метода приводят к весьма близким результатам. Однако анализ главных компонент часто более предпочтителен как метод сокращения данных, в то время как анализ главных факторов лучше применять с целью определения структуры данных.
Факторный анализ как метод классификации данных
Корреляционная матрица
Первый этап факторного анализа предусматривает вычисление корреляционной матрицы (в случае нормального выборочного распределения). Вернемся к примеру об удовлетворенности и рассмотрим корреляционную матрицу для переменных, относящихся к удовлетворенности на работе и дома.
Таблица 3. 15