

EKZAMEN
.pdfВычислительные системы (экзамен)
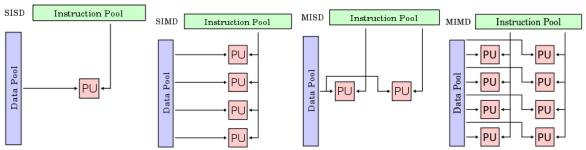
1.Классификация вычислительных систем Общая классификация архитектур ЭВМ по признакам наличия параллелизма в потоках команд и данных. Была предложена в
70-е годы Майклом Флинном (Michael Flynn). Все разнообразие архитектур ЭВМ в этой таксономии Флинна сводится к четырем классам:
•ОКОД — Вычислительная система с одиночным потоком команд и одиночным потоком данных (SISD, Single Instruction stream over a Single Data stream);
•ОКМД — Вычислительная система с одиночным потоком команд и множественным потоком данных (SIMD, Single Instruction, Multiple Data);
•МКОД — Вычислительная система со множественным потоком команд и одиночным потоком данных (MISD, Multiple Instruction Single Data);
•МКМД — Вычислительная система со множественным потоком команд и множественным потоком данных (MIMD, Multiple Instruction Multiple Data).
Так как в таксономии в качестве основного критерия используется параллелизм, то таксономия Флинна наиболее часто упоминается в технической литературе при классификации параллельных вычислительных систем. Поскольку SISD-машина параллельной машиной не является, а MISD-машины пока ещѐ не созданы (и их создание не предвидится), все параллельные вычислительные системы попадают в класс либо SIMD, либо в MIMD.
С развитием технологий классы SIMD и MIMD стали охватывать слишком большой круг машин, кардинально отличных друг от друга. В связи с этим в технической литературе используется дополнительный критерий — способ работы с памятью с точки зрения программиста. По этому критерию системы делятся на «системы с общей памятью» (англ. shared memory, SM) и «системы с распределенной памятью» (англ. distributed memory, DM). Соответственно, каждый класс — SIMD и MIMD —
делится на под-классы: SM-SIMD/DM-SIMD и SM-MIMD/DM-MIMD.
Следует обратить особое внимание на уточнение «с точки зрения программиста». Дело в том, что существуют вычислительные системы, где память физически распределена по узлам системы, но для всех процессоров системы она вся видна как общее единое глобальное адресное пространство.
Типичными представителями SIMD являются векторные архитектуры. К классу
MISD ряд исследователей относит конвейерные ЭВМ, однако это не нашло окончательного признания, поэтому можно считать, что реальных систем — представителей данного класса не существует. Класс MIMD включает в себя многопроцессорные системы, где процессоры обрабатывают множественные потоки данных.
Отношение конкретных машин к конкретному классу сильно зависит от точки зрения исследователя. Так, конвейерные машины могут быть отнесены и к классу SISD (конвейер — единый процессор), и к классу SIMD (векторный поток данных с конвейерным процессором) и к классу MISD (множество процессоров конвейера
обрабатывают один поток данных последовательно), и к классу MIMD — как выполнение последовательности различных команд (операций ступеней конвейера) на множественным скалярным потоком данных (вектором).
SISD (англ. Single Instruction, Single Data) или ОКОД (Одиночный поток Команд, Одиночный поток Данных) — архитектура компьютера, в которой один процессор выполняет один поток команд, оперируя одним потоком данных. Относится к фонНеймановской архитектуре. Один из классов вычислительных систем в классификации Флинна.
SISD компьютеры это обычные, «традиционные» последовательные компьютеры, в которых в каждый момент времени выполняется лишь одна операция над одним элементом данных (числовым или каким-либо другим значением). Большинство персональных ЭВМ до последнего времени, например, попадает именно в эту категорию. Иногда сюда относят и некоторые типы векторных компьютеров, это зависит от того, что понимать под потоком данных.
SIMD (англ. single instruction, multiple data — одиночный поток команд, множественный поток данных, ОКМД) — принцип компьютерных вычислений, позволяющий обеспечить параллелизм на уровне данных. Один из классов вычислительных систем в классификации Флинна.
SIMD-компьютеры состоят из одного командного процессора (управляющего модуля), называемого контроллером, и нескольких модулей обработки данных, называемых процессорными элементами. Управляющий модуль принимает, анализирует и выполняет команды. Если в команде встречаются данные, контроллер рассылает на все процессорные элементы команду, и эта команда выполняется на нескольких или на всех процессорных элементах. Каждый процессорный элемент имеет свою собственную память для хранения данных. Одним из преимуществ данной архитектуры считается то, что в этом случае более эффективно реализована логика вычислений. До половины логических инструкций обычного процессора связано с управлением выполнением машинных команд, а остальная их часть относится к работе с внутренней памятью процессора и выполнению арифметических операций. В SIMD компьютере управление выполняется контроллером, а «арифметика» отдана процессорным элементам.
Векторные процессоры также использовали принцип SIMD, одной командой могли обрабатываться векторы размером до нескольких тысяч элементов.
MISD-Архитектура (англ. Multiple Instruction stream, Single Data stream, Множественный поток Команд, Одиночный поток Данных, МКОД) — тип архитектуры параллельных вычислений, где несколько функциональных модулей (два или более) выполняют различные операции над одними данными. Один из классов вычислительных систем в классификации Флинна.
Отказоустойчивые компьютеры, выполняющие одни и те же команды избыточно с целью обнаружения ошибок, как следует из определения, принадлежат к этому типу. К этому типу иногда относят конвейерную архитектуру, но не все с этим согласны, так как данные будут различаться после обработки на каждой стадии в конвейере. Некоторые относят систолический массив процессоров к архитектуре MISD.
Было создано немного ЭВМ с MISD-архитектурой, поскольку MIMD и SIMD чаще всего являются более подходящими для общих методик параллельных данных. Они обеспечивают лучшее масштабирование и использование вычислительных ресурсов, чем архитектура MISD.
MIMD (англ. Multiple Instruction stream, Multiple Data stream — Множественный поток Команд, Множественный поток Данных,
сокращѐнно МКМД) — концепция архитектуры компьютера, используемая для достижения параллелизма вычислений. Один из классов вычислительных систем в классификации Флинна.
Машины имеют несколько процессоров, которые функционируют асинхронно и независимо. В любой момент, различные процессоры могут выполнять различные команды над различными частями данных. MIMD-архитектуры могут быть использованы в целом ряде областей, таких как системы автоматизированного проектирования / автоматизированное производство, моделирование, а также коммуникатор связей (communication switches). MIMD-машины могут быть либо с общей памятью, либо с распределяемой памятью. Эта классификация основана на том, как MIMD-процессоры получают доступ к памяти. Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных.
Обработка разделена на несколько потоков, каждый с собственным аппаратным состоянием процессора, в рамках единственного определѐнного программным обеспечением процесса или в пределах множественных процессов. Поскольку система имеет несколько потоков, ожидающих выполнения (системные или пользовательские потоки), эта архитектура эффективно использует аппаратные ресурсы.
В MIMD могут возникнуть проблемы взаимной блокировки и состязания за обладание ресурсами, так как потоки, пытаясь получить доступ к ресурсам, могут столкнуться непредсказуемым способом. MIMD требует специального кодирования в операционной системе компьютера, но не требует изменений в прикладных программах, кроме случаев когда программы сами используют множественные потоки (MIMD прозрачен для однопоточных программ под управлением большинства операционных систем, если программы сами не отказываются от управления со стороны ОС). И системное и пользовательское программное обеспечение, возможно, должны использовать программные конструкции, такие как семафоры, чтобы препятствовать тому, чтобы один поток вмешался в другой, в случае если они содержат ссылку на одни и те же данные. Такое действие увеличивает сложность кода, снижает производительность и значительно увеличивают количество необходимого тестирования, хотя обычно не настолько чтобы свести на нет преимущества многопроцессорной обработки.
Подобные конфликты могут возникнуть на аппаратном уровне между процессорами, и должен обычно решаться аппаратными средствами, или с комбинацией программного обеспечения и оборудования.
Архитектура SISD — это традиционный компьютер фон-Неймановской архитектуры с одним процессором, который выполняет последовательно одну инструкцию за другой, работая с одним потоком данных. В данном классе не используется параллелизм ни данных, ни инструкций, и следовательно SISD-машина не является параллельной. К этому классу также принято относить конвейерные, суперскалярные и VLIW-процессоры.
Типичными представителями SIMD являются векторные процессоры, обычные современные процессоры, когда работают в режиме выполнения команд векторных расширений, а также особый подвид с большим количеством процессоров — матричные процессоры. В SIMD-машинах один процессор загружает одну инструкцию, набор данных к ним и выполняет операцию, описанную в этой инструкции, над всем набором данных одновременно.
К классу MISD ряд исследователей относит конвейерные ЭВМ, однако это не нашло окончательного признания, поэтому можно считать, что реальных систем — представителей данного класса не существует.
Класс MIMD включает в себя многопроцессорные системы, где процессоры обрабатывают множественные потоки данных. Сюда принято относить традиционные мультипроцессорные машины, многоядерные и многопоточные процессоры, а также компьютерные кластеры.
2.Наиболее употребительные классы современных вычислительных систем
1.Векторно-конвейерные суперкомпьютеры
Первый векторно-конвейерный компьютер Cray-1 появился в 1976 году. Архитектура его оказалась настолько удачной, что он положил начало целому семейству компьютеров. Название этому семейству компьютеров дали два принципа, заложенные в архитектуре процессоров:
•конвейерная организация обработки потока команд
•введение в систему команд набора векторных операций, которые позволяют оперировать с целыми массивами данных. Длина одновременно обрабатываемых векторов в современных векторных компьютерах составляет, как правило, 128 или 256 элементов. Очевидно, что векторные процессоры должны иметь гораздо более сложную структуру и по сути дела содержать множество арифметических устройств. Основное назначение векторных операций состоит в распараллеливании выполнения операторов цикла, в которых в основном и сосредоточена большая часть вычислительной работы. Для этого циклы подвергаются процедуре векторизации с тем, чтобы они могли реализовываться с использованием векторных команд. Как правило, это выполняется автоматически компиляторами при изготовлении ими исполнимого кода программы. Поэтому векторно-конвейерные компьютеры не требовали какой-то специальной технологии программирования, что и явилось решающим фактором в их успехе на компьютерном рынке. Тем не менее, требовалось соблюдение некоторых правил при написании циклов с тем, чтобы компилятор мог их эффективно векторизовать.
Исторически это были первые компьютеры, к которым в полной мере было применимо понятие суперкомпьютер. Как правило, несколько векторно-конвейерных процессоров (2-16) работают в режиме с общей памятью (SMP), образуя вычислительный узел, а несколько таких узлов объединяются с помощью коммутаторов, образуя либо NUMA, либо MPP систему. Типичными представителями такой архитектуры являются компьютеры CRAY J90/T90, CRAY SV1, NEC SX-4/SX-
5. Уровень развития микроэлектронных технологий не позволяет в настоящее время производить однокристальные векторные процессоры, поэтому эти системы довольно громоздки и чрезвычайно дороги. В связи с этим, начиная с середины 90-х годов, когда появились достаточно мощные суперскалярные микропроцессоры, интерес к этому направлению был в значительной степени ослаблен. Суперкомпьютеры с векторно-конвейерной архитектурой стали проигрывать системам с массовым параллелизмом. Однако в марте 2002 г. корпорация NEC представила систему Earth Simulator из 5120 векторноконвейерных процессоров, которая в 5 раз превысила производительность предыдущего обладателя рекорда - MPP системы ASCI White из 8192 суперскалярных микропроцессоров. Это, конечно же, заставило многих по-новому взглянуть на перспективы векторно-конвейерных систем.
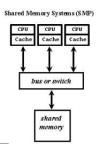
2. Симметричные мультипроцессорные системы SMP
Характерной чертой многопроцессорных систем SMP архитектуры является то, что все процессоры имеют прямой и равноправный доступ к любой точке общей памяти. Первые SMP системы состояли из нескольких однородных процессоров и массива общей памяти, к которой процессоры подключались через общую системную шину. Однако очень скоро обнаружилось, что такая архитектура непригодна для создания сколь либо масштабных систем. Первая возникшая проблема - большое число конфликтов при обращении к общей шине. Остроту этой проблемы удалось частично снять разделением памяти на блоки, подключение к которым с помощью коммутаторов позволило распараллелить обращения от различных процессоров. Однако и в таком подходе неприемлемо большими казались накладные расходы для систем более чем с 32-мя процессорами.
Современные системы SMP архитектуры состоят, как правило, из нескольких однородных серийно выпускаемых микропроцессоров и массива общей памяти, подключение к которой производится
либо с помощью общей шины, либо с помощью коммутатора (рис).
Наличие общей памяти значительно упрощает организацию взаимодействия процессоров между собой и упрощает программирование, поскольку параллельная программа работает в едином адресном пространстве. Однако за этой кажущейся простотой скрываются большие проблемы, присущие системам этого типа. Все они, так или иначе, связаны с оперативной памятью. Дело в том, что в настоящее время даже в однопроцессорных системах самым узким местом является оперативная память, скорость работы которой значительно отстала от скорости работы процессора. Для того чтобы сгладить этот разрыв, современные процессоры снабжаются скоростной буферной памятью (кэш-памятью), скорость работы которой значительно выше, чем скорость работы основной памяти. В качестве примера приведем данные измерения пропускной способности кэш-памяти и основной памяти для персонального компьютера на базе процессора Pentium III 1000 Мгц. В данном процессоре кэш-память имеет два уровня:
•L1 (буферная память команд) - объем 32 Кб, скорость обмена 9976 Мб/сек;
•L2 (буферная память данных) - объем 256 Кб, скорость обмена 4446 Мб/сек.
В то же время скорость обмена с основной памятью составляет всего 255 Мб/сек. Это означает, что для 100% согласованности со скоростью работы процессора (1000 Мгц) скорость работы основной памяти должна быть в 40 раз выше! Очевидно, что при проектировании многопроцессорных систем эти проблемы еще более обостряются. Помимо хорошо известной проблемы конфликтов при обращении к общей шине памяти возникла и новая проблема, связанная с иерархической структурой организации памяти современных компьютеров. В многопроцессорных системах, построенных на базе микропроцессоров со встроенной кэш-памятью, нарушается принцип равноправного доступа к любой точке памяти. Данные, находящиеся в кэш-памяти некоторого процессора, недоступны для других процессоров. Это означает, что после каждой модификации копии некоторой переменной, находящейся в кэш-памяти какого-либо процессора, необходимо производить синхронную модификацию самой этой переменной, расположенной в основной памяти.
С большим или меньшим успехом эти проблемы решаются в рамках общепринятой в настоящее время архитектуры ccNUMA (cache coherent Non Uniform Memory Access). В этой архитектуре память физически распределена, но логически общедоступна. Это, с одной стороны, позволяет работать с единым адресным пространством, а, с другой, увеличивает масштабируемость систем. Когерентность кэш-памяти поддерживается на аппаратном уровне, что не избавляет, однако, от накладных расходов на ее поддержание. В отличие от классических SMP систем память становится трехуровневой: кэшпамять процессора; локальная оперативная память; удаленная оперативная память. Время обращения к различным уровням может отличаться на порядок, что сильно усложняет написание эффективных параллельных программ для таких систем.
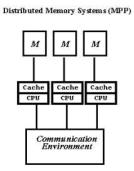
3. Системы с массовым параллелизмом (МРР)
Проблемы, присущие многопроцессорным системам с общей памятью, простым и естественным образом устраняются в системах с массовым параллелизмом. Компьютеры этого типа представляют собой многопроцессорные системы с распределенной памятью, в которых с помощью некоторой коммуникационной среды объединяются однородные вычислительные узлы (рис).
Каждый из узлов состоит из одного или нескольких процессоров, собственной оперативной памяти, коммуникационного оборудования, подсистемы ввода/вывода, т.е. обладает всем необходимым для независимого функционирования. При этом на каждом узле может функционировать либо полноценная операционная система (как в системе RS/6000 SP2), либо урезанный вариант, поддерживающий только базовые функции ядра, а полноценная ОС работает на специальном управляющем компьютере (как в системах
Cray T3E, nCUBE2).
Процессоры в таких системах имеют прямой доступ только к своей локальной памяти. Доступ к памяти других узлов реализуется обычно с помощью механизма передачи сообщений. Такая архитектура вычислительной системы устраняет одновременно как проблему конфликтов при обращении к памяти, так и проблему когерентности кэш-памяти. Это дает возможность практически неограниченного наращивания числа процессоров в системе, увеличивая тем самым ее производительность. Успешно функционируют MPP системы с сотнями и тысячами процессоров (ASCI White - 8192, Blue Mountain - 6144). Производительность наиболее мощных систем достигает 10 триллионов оп/сек (10 Tflops). Важным свойством MPP систем является их высокая степень масштабируемости. В зависимости от вычислительных потребностей для достижения необходимой производительности требуется просто собрать систему с нужным числом узлов.
На практике все, конечно, гораздо сложнее. Устранение одних проблем, как это обычно бывает, порождает другие. Для MPP систем на первый план выходит проблема эффективности коммуникационной среды. Легко сказать: "Давайте соберем систему из 1000 узлов". Но каким образом соединить в единое целое такое множество узлов? Самым простым и наиболее эффективным было бы соединение каждого процессора с каждым. Но тогда на каждом узле потребовалось бы 999 коммуникационных каналов, желательно двунаправленных. Очевидно, что это нереально. Различные производители MPP систем использовали разные топологии. В компьютерах Intel Paragon процессоры образовывали прямоугольную двумерную сетку. Для этого в каждом узле достаточно четырех коммуникационных каналов. В компьютерах Cray T3D/T3E использовалась топология трехмерного тора. Соответственно, в узлах этого компьютера было шесть коммуникационных каналов. Фирма nCUBE использовала в своих компьютерах топологию n-мерного гиперкуба. Подробнее на этой топологии мы остановимся в главе 4 при изучении суперкомпьютера nCUBE2. Каждая из рассмотренных топологий имеет свои преимущества и недостатки. Отметим, что при обмене данными между процессорами, не являющимися ближайшими соседями, происходит трансляция данных через промежуточные узлы. Очевидно, что в узлах должны быть предусмотрены какие-то аппаратные средства, которые освобождали бы центральный процессор от участия в трансляции данных. В последнее время для соединения вычислительных узлов чаще используется иерархическая система высокоскоростных коммутаторов, как это впервые было реализовано в компьютерах IBM SP2. Такая топология дает возможность прямого обмена данными между любыми узлами, без участия в этом промежуточных узлов.
Системы с распределенной памятью идеально подходят для параллельного выполнения независимых программ, поскольку при этом каждая программа выполняется на своем узле и никаким образом не влияет на выполнение других программ. Однако при разработке параллельных программ приходится учитывать более сложную, чем в SMP системах, организацию памяти. Оперативная память в MPP системах имеет 3-х уровневую структуру:
•кэш-память процессора;
•локальная оперативная память узла;
•оперативная память других узлов.
При этом отсутствует возможность прямого доступа к данным, расположенным в других узлах. Для их использования эти данные должны быть предварительно переданы в тот узел, который в данный момент в них нуждается. Это значительно усложняет программирование. Кроме того, обмены данными между узлами выполняются значительно медленнее, чем обработка данных в локальной оперативной памяти узлов. Поэтому написание эффективных параллельных программ для таких компьютеров представляет собой более сложную задачу, чем для SMP систем.
4.Кластерные системы
Кластерные технологии стали логическим продолжением развития идей, заложенных в архитектуре MPP систем. Если процессорный модуль в MPP системе представляет собой законченную вычислительную систему, то следующий шаг напрашивается сам собой: почему бы в качестве таких вычислительных узлов не использовать обычные серийно выпускаемые компьютеры. Развитие коммуникационных технологий, а именно, появление высокоскоростного сетевого оборудования и специального программного обеспечения, такого как система MPI (см. часть 2), реализующего механизм передачи сообщений над стандартными сетевыми протоколами, сделали кластерные технологии общедоступными. Сегодня не составляет большого труда создать небольшую кластерную систему, объединив вычислительные мощности компьютеров отдельной лаборатории или учебного класса.
Привлекательной чертой кластерных технологий является то, что они позволяют для достижения необходимой производительности объединять в единые вычислительные системы компьютеры самого разного типа, начиная от персональных компьютеров и заканчивая мощными суперкомпьютерами. Широкое распространение кластерные технологии получили как средство создания систем суперкомпьютерного класса из составных частей массового производства, что значительно удешевляет стоимость вычислительной системы. В частности, одним из первых был реализован проект COCOA [4], в котором на базе 25 двухпроцессорных персональных компьютеров общей стоимостью порядка $100000 была создана система с производительностью, эквивалентной 48-процессорному Cray T3D стоимостью несколько миллионов долларов США.
Конечно, о полной эквивалентности этих систем говорить не приходится. Как указывалось в предыдущем разделе, производительность систем с распределенной памятью очень сильно зависит от производительности коммуникационной среды. Коммуникационную среду можно достаточно полно охарактеризовать двумя параметрами: латентностью - временем задержки при посылке сообщения, и пропускной способностью - скоростью передачи информации. Так вот для компьютера Cray T3D эти параметры составляют соответственно 1 мкс и 480 Мб/сек, а для кластера, в котором в качестве коммуникационной среды использована сеть Fast Ethernet, 100 мкс и 10 Мб/сек. Это отчасти объясняет очень высокую стоимость суперкомпьютеров. При таких параметрах, как у рассматриваемого кластера, найдется не так много задач, которые могут эффективно решаться на достаточно большом числе процессоров.
Если говорить кратко, то кластер - это связанный набор полноценных компьютеров, используемый в качестве единого вычислительного ресурса. Преимущества кластерной системы перед набором независимых компьютеров очевидны. Вопервых, разработано множество диспетчерских систем пакетной обработки заданий, позволяющих послать задание на обработку кластеру в целом, а не какому-то отдельному компьютеру. Эти диспетчерские системы автоматически распределяют задания по свободным вычислительным узлам или буферизуют их при отсутствии таковых, что позволяет обеспечить более равномерную и эффективную загрузку компьютеров. Во-вторых, появляется возможность совместного использования вычислительных ресурсов нескольких компьютеров для решения одной задачи.
Для создания кластеров обычно используются либо простые однопроцессорные персональные компьютеры, либо двухили четырехпроцессорные SMP-серверы. При этом не накладывается никаких ограничений на состав и архитектуру узлов. Каждый из узлов может функционировать под управлением своей собственной операционной системы. Чаще всего используются стандартные ОС: Linux, FreeBSD, Solaris, Tru64 Unix, Windows NT. В тех случаях, когда узлы кластера неоднородны, то говорят о гетерогенных кластерах.
При создании кластеров можно выделить два подхода. Первый подход применяется при создании небольших кластерных систем. В кластер объединяются полнофункциональные компьютеры, которые продолжают работать и как самостоятельные единицы, например, компьютеры учебного класса или рабочие станции лаборатории. Второй подход применяется в тех случаях, когда целенаправленно создается мощный вычислительный ресурс. Тогда системные блоки компьютеров компактно размещаются в специальных стойках, а для управления системой и для запуска задач выделяется один или несколько полнофункциональных компьютеров, называемых хост-компьютерами. В этом случае нет необходимости снабжать компьютеры вычислительных узлов графическими картами, мониторами, дисковыми накопителями и другим периферийным оборудованием, что значительно удешевляет стоимость системы.
Разработано множество технологий соединения компьютеров в кластер. Наиболее широко в данное время используется технология Fast Ethernet. Это обусловлено простотой ее использования и низкой стоимостью коммуникационного оборудования. Однако за это приходится расплачиваться заведомо недостаточной скоростью обменов. В самом деле, это оборудование обеспечивает максимальную скорость обмена между узлами 10 Мб/сек, тогда как скорость обмена с оперативной памятью составляет 250 Мб/сек и выше. Разработчики пакета подпрограмм ScaLAPACK, предназначенного для решения задач линейной алгебры на многопроцессорных системах, в которых велика доля коммуникационных операций, формулируют следующим образом требование к многопроцессорной системе: "Скорость межпроцессорных обменов между двумя узлами, измеренная в Мб/сек, должна быть не менее 1/10 пиковой производительности вычислительного узла, измеренной в Mflops" [5]. Таким образом, если в качестве вычислительных узлов использовать компьютеры класса Pentium III 500 Мгц (пиковая производительность 500 Mflops), то аппаратура Fast Ethernet обеспечивает только 1/5 от требуемой скорости. Частично это положение может поправить переход на технологии Gigabit Ethernet.
Ряд фирм предлагают специализированные кластерные решения на основе более скоростных сетей, таких как SCI фирмы Scali Computer (~100 Мб/сек) и Mirynet (~120 Мб/сек). Активно включились в поддержку кластерных технологий и фирмыпроизводители высокопроизводительных рабочих станций (SUN, HP, Silicon Graphics).
5.Грид-вычисления (англ. grid — решѐтка, сеть)
Это форма распределѐнных вычислений, в которой «виртуальный суперкомпьютер» представлен в виде кластеров соединѐнных с помощью сети, слабосвязанных, гетерогенных компьютеров, работающих вместе для выполнения огромного количества заданий (операций, работ). Эта технология применяется для решения научных, математических задач, требующих значительных вычислительных ресурсов. Грид-вычисления используются также в коммерческой инфраструктуре для решения таких трудоѐмких задач, как экономическое прогнозирование, сейсмоанализ, разработка и изучение свойств новых лекарств.
Грид с точки зрения сетевой организации представляет собой согласованную, открытую и стандартизованную среду, которая обеспечивает гибкое, безопасное, скоординированное разделение вычислительных ресурсов и ресурсов хранения информации, которые являются частью этой среды, в рамках одной виртуальной организации.
Концепция грид Грид является географически распределѐнной инфраструктурой, объединяющей множество ресурсов разных типов
(процессоры, долговременная и оперативная память, хранилища и базы данных, сети), доступ к которым пользователь может получить из любой точки, независимо от места их расположения.
Идея грид-компьютинга возникла вместе с распространением персональных компьютеров, развитием интернета и технологий пакетной передачи данных на основе оптического волокна (SONET, Синхронная цифровая иерархияSDH и ATM), а также технологий локальных сетей (Gigabit Ethernet). Полоса пропускания коммуникационных средств стала достаточной, чтобы при необходимости привлечь ресурсы другого компьютера. Учитывая, что множество подключенных к глобальной сети компьютеров большую часть рабочего времени простаивает и располагает ресурсами, большими, чем необходимо для решения их повседневных задач, возникает возможность применить их неиспользуемые ресурсы в другом месте.
Сравнение грид-систем и обычных суперкомпьютеров Распределѐнные или грид-вычисления в целом являются разновидностью параллельных вычислений, которое основывается
на обычных компьютерах (со стандартными процессорами, устройствами хранения данных, блоками питания и т. д.) подключенных к сети (локальной или глобальной) при помощи обычных протоколов, например Ethernet. В то время как обычный суперкомпьютер содержит множество процессоров, подключенных к локальной высокоскоростной шине.

Основным преимуществом распределѐнных вычислений является то, что отдельная ячейка вычислительной системы может быть приобретена как обычный неспециализированный компьютер. Таким образом можно получить практически те же вычислительные мощности, что и на обычных суперкомпьютерах, но с гораздо меньшей стоимостью.
Типы грид-систем В настоящее время выделяют три основных типа грид-систем:
•Добровольные гриды — гриды на основе использования добровольно предоставляемого свободного ресурса персональных компьютеров;
•Научные гриды — хорошо распараллеливаемые приложения программируются специальным образом (например, с
использованием Globus Toolkit);
•Гриды на основе выделения вычислительных ресурсов по требованию (коммерческий грид, англ. enterprise grid) — обычные коммерческие приложения работают на виртуальном компьютере, который, в свою очередь, состоит из нескольких физических компьютеров, объединѐнных с помощью грид-технологий.
6.Облачные вычисления (англ. cloud computing)
Это модель обеспечения повсеместного и удобного сетевого доступа по требованию к общему пулу (англ. pool) конфигурируемых вычислительных ресурсов (например, сетям передачи данных, серверам, устройствам хранения данных, приложениям и сервисам — как вместе, так и по отдельности), которые могут быть оперативно предоставлены и освобождены с минимальными эксплуатационными затратами и/или обращениями к провайдеру.
Потребители облачных вычислений могут значительно уменьшить расходы на инфраструктуру информационных технологий (в краткосрочном и среднесрочном планах) и гибко реагировать на изменения вычислительных потребностей, используя свойства вычислительной эластичности (англ. elastic computing) облачных услуг.
7.Многоядерный процессор Центральный процессор, содержащий два и более вычислительных ядра на одном процессорном кристалле или в одном корпусе.
Архитектура многоядерных систем Многоядерные процессоры можно подразделить по наличию поддержки когерентности (общей) кеш-памяти между ядрами. Бывают процессоры с такой поддержкой и без неѐ.
Способ связи между ядрами:
•разделяемая шина
•сеть (Mesh) на каналах точка-точка
•сеть с коммутатором
•общая кэш-память
Кэш-память: Во всех существующих на сегодня многоядерных процессорах кеш-памятью 1-го уровня обладает каждое ядро в отдельности, а кеш-память 2-го уровня существует в нескольких вариантах:
•разделяемая — расположена на одном кристалле с ядрами и доступна каждому из них в полном объѐме. Используется в процессорах семейств Intel Core.
•индивидуальная — отдельные кеши равного объѐма, интегрированные в каждое из ядер. Обмен данными из кешей 2-го уровня между ядрами осуществляется через контроллер памяти — интегрированный (Athlon 64 X2, Turion X2, Phenom) или внешний (использовался в Pentium D, в дальнейшем Intel отказалась от такого подхода).
3.Эволюция и тенденции развития процессорных архитектур
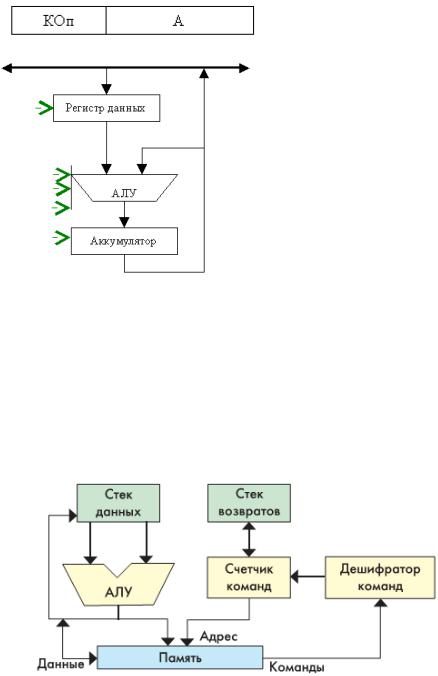
4.Аккумуляторная архитектура Характерной чертой аккумуляторной архитектуры является использование аккумулятора. Аккумулятор – специальный
регистр, хранящий операнды либо промежуточные результаты вычисления АЛУ, при этом сам аккумулятор всегда жестко связан с одним из входов АЛУ.
Для управления таким вычислителем необходимо загружать данные на свободный вход АЛУ (операция LOAD). При загрузке первого операнда он автоматически попадает в аккумулятор, и копируется на вход АЛУ, загрузка второго операнда помещает его на второй вход АЛУ. АЛУ выполняет операцию, а результат выполнения помещает в аккумулятор. Для сохранения результатов из аккумулятора в основную память используется операция STORE.
Достоинства:
•Реализация произвольных алгоритмов осуществляется с использованием одно или без операндных инструкций.
•Сложность программы эквивалентна сложности программы для вычислителей со стековой архитектурой.
•Отсутствует память с последовательным доступом.
•Положительный эффект от аккумулятора, при реализации итеративных алгоритмов.
Недостатки:
• Наличие аккумулятора, что требует использования операций последовательной загрузки операндов и сохранения результатов.
Аккумуляторная система команд исторически возникла одной из первых. В ней для хранения одного из операндов арифметических и логических команд, а также и результатов выделен специальный регистр – аккумулятор. Поскольку размещение одного операнда предопределено, в командах обработки достаточно указывать размещение только второго операнда. Поэтому для данной архитектуры характерны одноадресные команды (рис). Например, команда сложения имеет
формат ADD A.
Для непосредственной загрузки аккумулятора из памяти предусмотрена специальная команда Load A, а для записи содержимого аккумулятора в память -команда Store A.
На рисунке приведена архитектура УОД с аккумулятором.
Выполнение арифметических команд, например сложения ADD A, где A – адрес второго слагаемого производится следующим образом. В первом цикле команды производится считывание слагаемого из памяти по адресу A в регистр данных. Затем в АЛУ выполняется операция сложения над содержимым регистра данных и аккумулятора. Результат записывается в аккумулятор, замещая первое слагаемое.
Достоинством аккумуляторной АСК являются простые одноадресные команды, что упрощает их дешифрацию и способствует повышению быстродействия. АСК на базе аккумулятора была популярна в ранних ЭВМ таких, как IBM 7090, PDP-8 (DEC), MOS 6502.
5.Стековые процессоры
Процессор, который осуществляет свои действия, используя стек. Такая архитектура процессора позволяет осуществлять действия очень быстро; несмотря на то, что такой принцип вышел на некоторое время из моды, развитие технологии дает возможность реализовать идею стекового процессора очень эффективно, что может привести к значительному увеличению скорости выполнения вычислительных операций.
Верхнюю ячейку называют вершиной стека. Для работы со стеком предусмотрены две операции: push (проталкивание данных в стек) и pop (вытягивание данных из стека). Запись возможна только в верхнюю ячейку стека, при этом вся хранящаяся в стеке информация предварительно проталкивается на одну позицию вниз. Чтение допустимо также только из вершины стека. Извлеченная информация удаляется из стека, а оставшееся его содержимое продвигается вверх. В вычислительных машинах, где реализована АСК на базе стека (их обычно называют стековыми), операнды перед обработкой помещаются в две верхних ячейки стековой памяти.
Блок-схема стекового процессора приведена на рис. 1. В отличие от «обычного» микропроцессора, стековый процессор содержит два стека — стек данных и стек возвратов. Стек возвратов используется для возвратов из подпрограмм, как и у «обычных» микропроцессоров, а вот стек данных — это «привилегия» стекового процессора. Именно через стек данных производится передача параметров при вычислениях.
6.Регистровая архитектура
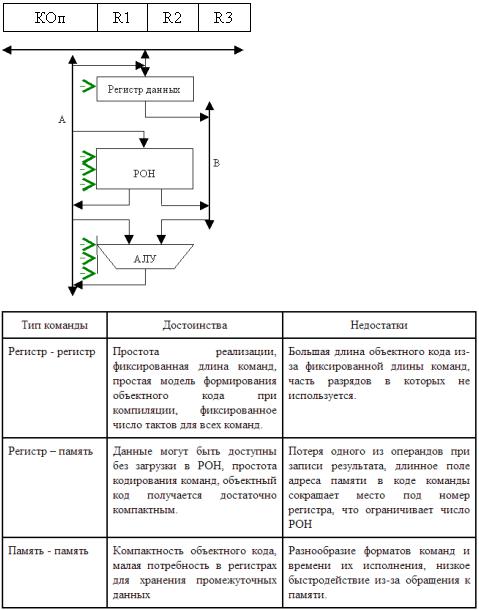
Вмашинах данного типа процессор включает в себя массив регистров (регистровый файл), известных как регистры общего назначения (РОН). Эти регистры, в каком-то смысле, можно рассматривать как явно управляемый кэш для хранения недавно использовавшихся данных. Размер регистров обычно фиксирован и совпадает с размером машинного слова. К любому регистру можно обратиться, указав его номер. Количество РОН в архитектурах типа CISC обычно невелико (от 8 до 32), и для представления номера конкретного регистра необходимо не более пяти разрядов, благодаря чему в адресной части команд обработки допустимо одновременно указать номера двух, а зачастую и трех регистров (двух регистров операндов и регистра результата). RISC-архитектура предполагает использование существенно большего числа РОН (до нескольких сотен), однако типичная для таких ВМ длина команды (обычно 32 разряда) позволяет определить в команде до трех регистров. Регистровая архитектура допускает расположение операндов в одной из двух запоминающих сред: основной памяти или регистрах. С учетом возможного размещения операндов в рамках регистровых АСК выделяют три подвида команд обработки: регистррегистр; регистр-память; память-память.
Вварианте «регистр-регистр» операнды могут находиться только в регистрах. В них же засылается и результат. Подтип «регистр-память» предполагает, что од и и из операндов размещается в регистре, а второй в основной памяти. Результат обычно замещает один из операндов. В командах типа «память-память» оба операнда хранятся в основной памяти. Результат заносится в память. Каждому из вариантов свойственны свои достоинства и недостатки (табл. 2.4).
Ввыражениях вида (т, п), приведенных в первом столбце таблицы, т означает количество операндов, хранящихся в основной памяти, а n — общее число операндов в команде арифметической или логической обработки.
Вариант «регистр-регистр» является основным в вычислительных машинах типа RISC. Команды типа «регистр-память» характерны для CISC-машин. Наконец, вариант «память-память» считается неэффективным, хотя и остается в наиболее сложных моделях машин класса CISC.
Вкомпьютерах с данной архитектурой в состав процессора включается массив регистров общего назначения (РОН),
используемых в качестве быстродействующей буферной памяти для размещения наиболее актуальных данных. Разрядность регистров обычно соответствует длине машинного слова. В CISCархитектурах число РОН невелико (8 – 32) и для их адресации требуется не более 5 разрядов. Это позволяет использовать команды, в адресной части которых указываются адреса двух или даже трех
регистров (рис).
RISC-архитектура предполагает использование до нескольких сотен РОН. Но и в этом случае при длине команды 32 разряда в ней можно разместить адреса трех регистров.
На рисунке приведена архитектура УОД на базе РОН.
Регистровая архитектура предполагает размещение операндов как в ОП, так и в РОН, поэтому возможны три типа команд обработки: регистр – регистр; регистр – память; память – память.
Сравнительная оценка этих типов команд приведена в таблице.
Команды типа «регистр – регистр» являются основными в RISC-компьютерах. Команды типа «регистр – память» характерны для CISC-машин. Команды «память – память» считаются неэффективными, хотя и входят в состав набора команд наиболее сложных CISC-процессоров.
Примерами ЭВМ на базе РОН служат CDC 6600, IBM 360/370, PDP-11 и подавляющая часть современных персональных компьютеров.
7.CISC и RISC процессоры
CISC (англ. Complex Instruction Set Computing) — концепция проектирования процессоров, которая характеризуется следующим набором свойств:
•небольшое число регистров общего назначения;
•большое количество машинных команд,
•наличие сложных (многотактных) команд, функционально аналогичных операторам языков программирования высокого уровня,
•большое количество способов адресации,
•большое количество форматов команд различной разрядности,
•преобладание двухадресного формата команд,
•наличие команд обработки типа регистр-память.
Процессору с архитектурой CISC приходится иметь дело с более сложными инструкциями неодинаковой длины. Выполнение одиночной CISC-инструкции может происходить быстрее, однако обрабатывать несколько таких инструкций параллельно сложнее.
Облегчение отладки программ на ассемблере влечет за собой загромождение узлами микропроцессорного блока. Для повышения быстродействия следует увеличить тактовую частоту и степень интеграции, что вызывает необходимость совершенствования технологии и, как следствие, удорожание производства.
RISC (Reduced Instruction Set Computing). Процессор с сокращенным набором команд. Система команд имеет упрощенный вид. Все команды одинакового формата с простой кодировкой. Обращение к памяти происходит посредством команд загрузки и записи, остальные команды типа регистр-регистр. Команда, поступающая в CPU, уже разделена по полям и не требует дополнительной дешифрации.
Часть кристалла освобождается для включения дополнительных компонентов. Степень интеграции ниже, чем в предыдущем архитектурном варианте, поэтому при высоком быстродействии допускается более низкая тактовая частота. Команда меньше загромождает ОЗУ, CPU дешевле. Программной совместимостью указанные архитектуры не обладают. Отладка программ на RISC более сложна. Данная технология может быть реализована программно-совместимым с технологией CISC (например, суперскалярная технология).
Поскольку RISC-инструкции просты, для их выполнения нужно меньше логических элементов, что в конечном итоге снижает стоимость процессора. Но большая часть программного обеспечения сегодня написана и откомпилирована специально для CISC-процессоров фирмы Intel. Для использования архитектуры RISC нынешние программы должны быть перекомпилированы, а иногда и переписаны заново.
4 основных принципа RISC:
1.Любая операция должна выполняться за один такт, вне зависимости от ее типа.
2.Система команд должна содержать минимальное количество наиболее часто используемых простейших инструкций одинаковой длины.
3.Операции обработки данных реализуются только в формате ―регистр - регистр― (операнды выбираются из оперативных регистров процессора, и результат операции записывается также в регистр; а обмен между оперативными регистрами и памятью выполняется только с помощью команд загрузки\записи ).
4.Состав системы команд должен быть ― удобен ― для компиляции операторов языков высокого уровня
Вдальнейшем эти требования были несколько смягчены. Выполнение команды за один такт стало трактоваться как загрузка конвейера команд в темпе "команда за такт". Набор команд современных RISC-процессоров возрос и содержит до 150 команд и более.
Незыблемым для архитектуры RISC остается только требование: обработка данных ведется только командами в формате регистр-регистр.
Среди других особенностей RISC архитектур следует отметить:
• наличие достаточно большого файла РОНов (32 и более регистров),
• для обработки используются трехадресные регистровые команды,
• команды регистр-память используются только для загрузки (Ld) РОНов из памяти и сохранения (ST) содержимого РОНов в памяти,
• как следствие упрощения команд, использование аппаратной, а не микропрограммной логики выполнения команд,
Впоследних разработках МП компании Intel, начиная с МП Pentium Pro, а также ее последователей и конкурентов (AMD R5, Cyrix M1, NexGen Nx586 и др.) широко используются идеи, реализованные в RISC-микропроцессорах.
8.Суперскалярные процессоры
Суперскалярность — архитектура вычислительного ядра, использующая несколько декодеров команд, которые могут загружать работой множество исполнительных блоков. Планирование исполнения потока команд является динамическим и осуществляется самим вычислительным ядром.
Если в процессе работы команды, обрабатываемые конвейером, не противоречат друг другу, и одна не зависит от результата другой, то такое устройство (ядро) может осуществить параллельное выполнение команд. В суперскалярных системах решение о запуске инструкции на исполнение принимает сам вычислительный модуль, что требует много ресурсов.
Параллельное выполнение команд не всегда возможно по причине тех же конфликтов, что и в конвейере. Для разрешения возможных конфликтов используют методы внеочередной выборки и завершения команд, прогнозирования переходов, условное выполнение команд и пр. Применяется динамическое распределение команд, причем порядок их выборки может не совпадать с порядком следования в программе. Естественно, результат выполнения должен совпадать с результатом строго последовательного выполнения.
Недостатки: сложность аппаратной части; ограниченный размер окна выполнения, что уменьшает возможности определения потенциально параллельных команд.
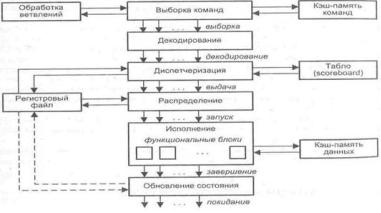
Суперскалярным называется центральный процессор (ЦП), который одновременно выполняет более чем одну скалярную команду. Это достигается за счет включения в состав ЦП нескольких самостоятельных функциональных (исполнительных) блоков, каждый из которых отвечает за свой класс операций и может присутствовать в процессоре в нескольких экземплярах. Так, в микропроцессоре Pentium III блоки целочисленной арифметики и операций с плавающей точкой дублированы, а в микропроцессорах Pentium 4 и Athlon — троированы. Структура типичного суперскалярного процессора показана на рисунке. Процессор включает в себя шесть блоков: выборки команд, декодирования команд, диспетчеризации команд, распределения команд ПФ функциональным блокам, блок исполнения
и блок обновления состояния.
Блок выборки команд извлекает команды из основной памяти через кэш-память команд. Этот блок хранит несколько значений счетчика команд и обрабатывает команды условного перехода.
Блок декодирования расшифровывает код операции, содержащийся в извлеченных из кэш-памяти командах. В некоторых суперскалярных, процессорах, например в микропроцессорах фирмы Intel, блоки выборки и декодирования совмещены.
Блоки диспетчеризации и распределения взаимодействуют между собой и в совокупности играют в суперскалярном процессоре роль контроллера трафика. Оба блока хранят очереди декодированных команд. Очередь блока распределения часто рассредоточивается по несколько самостоятельным буферам — накопителям команд или схемам резервирования (reservation station),- предназначенным для хранения команд, которые уже декодированы, но еще не выполнены. Каждый накопитель команд связан со своим функциональным блоком (ФБ), поэтому число накопителей обычно равно числу ФБ, но если в процессоре используется несколько однотипных ФБ, то им придается общий накопитель. По отношению к блоку диспетчеризации накопители команд выступают в роли виртуальных функциональных устройств.
В дополнение к очереди, блок диспетчеризации хранит также список свободных функциональных блоков, называемый табло (Scoreboard). Табло используется для отслеживания состояния очереди распределения. Один раз за цикл блок диспетчеризации извлекает команды из своей очереди, считывает из памяти или регистров операнды этих команд, после чего, в зависимости от состояния табло, помещает команды и значения операндов в очередь распределения. Эта операция называется выдачей команд. Блок распределения в каждом цикле проверяет каждую команду в своих очередях на наличие всех необходимых для ее выполнения операндов и при положительном ответе начинает выполнение таких команд в соответствующем функциональном блоке.
Блок исполнения состоит из набора функциональных блоков. Примерами ФБ могут служить целочисленные операционные блоки, блоки умножения и сложения с плавающей запятой, блок доступа к памяти. Когда исполнение команды завершается, ее результат записывается и анализируется блоком обновления состояния, который обеспечивает учет полученного результата теми командами в очередях распределения, где этот результат выступает в качестве одного из операндов.
Как было отмечено ранее, суперскалярность предполагает параллельную работу максимального числа исполнительных блоков, что возможно лишь при односменном выполнении нескольких скалярных команд. Последнее условие хорошо сочетается с конвейерной обработкой, при этом желательно, чтобы в суперскалярном процессоре было несколько конвейеров, например два или три.