

EKZAMEN
.pdfсистем управления процесс создания контрольных точек сложен и зависит от реализации системы управления и возможностей операционной системы, используемой на узлах кластера. Все системы, поддерживающие контрольное сохранение, делают это с теми или иными ограничениями, о которых мы упомянем при более детальном рассмотрении конкретных систем.
Сложной задачей является восстановление состояния параллельной программы. Применяются два метода (и их комбинация), основанные на промежуточной фиксации состояния либо ведении журнала выполняемых операций. Они различаются объемом запоминаемой информацией и временем, требуемым для восстановления. На рис. 1 показаны три процесса (X,Y,Z), взаимодействующие через сообщения. Вертикальные черточки показывают на временной оси моменты запоминания состояния процесса для восстановления в случае отказа. Стрелочки соответствуют сообщениям и показывают моменты их отправления и получения.
Если процесс Y аварийно завершился в точке F1 после отправки сообщения M1, посылка которого зафиксирована в точке x3 и не зафиксирована в y2. Сообщение М1 называется сообщением-сиротой, а состояния y2 и x3 являются несогласованными. В таком случае процесс X должен быть возвращен в состояние x2. Этот эффект известен как эффект домино. Множество
контрольных точек должно быть консистентным. Для любой зафиксированной операции |
приема |
сообщения, |
соответствующая операция посылки должна быть также зафиксирована (нет сообщений-сирот). |
Система |
должна |
осуществлять восстановление с использованием консистентного множества контрольных точек – повторить отправку тех сообщений, квитанции о получении которых стали недействительными в результате отката.
В случае отказа управляющего узла, система должна иметь возможность либо продолжить работу, выбрав самостоятельно новый управляющий узел, либо восстановить свое состояние позднее, когда управляющая машина вернется в рабочее состояние.
Пользовательский интерфейс Очень важная характеристика системы для конечных пользователей – это пользовательский интерфейс. Если пользователь не
понимает систему из-за сложного или громоздкого интерфейса, система не будет использоваться.
Система управления должна предоставлять пользователю возможность доступа через WEB – интерфейс. Такой доступ не требует установки на машины пользователя никакого дополнительного программного обеспечения.
Задания для системы управления должны формулироваться с использованием некоторого языка. Этот язык не должен быть сложен при изучении и использовании.
Для обеспечения эффективности система может потребовать, чтобы программа была заново перекомпилирована или собрана с использованием специальных библиотек. Такое требование обычно необходимо для обеспечения поддержки контрольных точек и миграции процессов, однако в большинстве случаев может быть неприемлемо для пользователей. Переносимости в
общем случае нет. |
|
|
|
Особенности |
реализации |
систем |
управления кластерами |
В общем |
случае система |
управления |
кластером имеет подсистему, работающую на управляющем узле кластера |
(управляющая подсистема) и подсистемы, работающие на каждом вычислительном узле (периферийные подсистемы). Управляющая и периферийные подсистемы взаимодействуют через коммуникационную систему кластера.
Следует отметить, что кластер должен иметь две коммуникационных системы: одна используется для взаимодействия компонент распределенных программ, выполняемых на кластере, другая – для организации взаимодействия подсистем системы управления кластером. Это следует из того, что для эффективного использования сетей рабочих станций коммуникационная система должна обеспечивать максимальную пропускную способность и минимальные задержки при передаче данных [22], и дополнительная нагрузка со стороны системы управления может значительно снизить производительность кластера. В настоящее время коммуникационная система, обеспечивающая взаимодействие компонент распределенных программ, расположенных на разных узлах кластера, строится на основе коммуникационного оборудования Myrinet или SCI, а коммуникационная система для работы системы управления – на основе Ethernet или Fast Ethernet.
Управляющая подсистема принимает задания от пользователей и отправляет их на вычислительные узлы. Кроме того, управляющая подсистема опрашивает периферийные подсистемы узлов кластера и собирает необходимую информацию, связанную с текущим состоянием каждого узла. Все управление кластером осуществляется его управляющей подсистемой, а периферийные подсистемы узлов кластера в общем случае только отвечают на запросы управляющей подсистемы. Такой подход позволяет избежать резких скачков сетевого трафика, которые могут быть порождены несогласованными действиями большого количества периферийных подсистем. Можно сказать, что система управления кластером работает по принципу клиент-сервер, клиентом является управляющая подсистема, а каждая периферийная подсистема – сервером.
Как управляющая, так и периферийные подсистемы могут быть реализованы как прикладные программы для операционной системы узла. Однако некоторые требования к системе управления, связанные с механизмами защиты (сохранение состояния процесса, контроль над используемыми ресурсами и т.п.) не могут быть полностью реализованы на уровне прикладных программ. Для обеспечения указанных возможностей часть системы управления должна быть реализована на уровне ядра операционной системы (если операционной системой узла является Linux, то наиболее удобна реализация в виде модуля).
36.Основные подходы к управлению кластерами (Распределенные окружения для кла-стерных вычислений и системы управления кластерами)
a.Распределенные окружения для кластерных вычислений:
Распределѐнные вычисления — способ решения трудоѐмких вычислительных задач с использованием нескольких компьютеров, чаще всего объединѐнных в параллельную вычислительную систему. Выполнение последовательных вычислений в распределенных системах имеет смысл в рамках решения многих задач одновременно, например в распределенных системах управления. Особенностью распределенных многопроцессорных вычислительных систем, в отличие от локальных суперкомпьютеров, является возможность неограниченного наращивания производительности за счет масштабирования.
Слабосвязанные, гетерогенные вычислительные системы с высокой степенью распределения выделяют в отдельный класс распределенных систем — Grid.
Распределѐнная ОС, динамически и автоматически распределяя работы по различным машинам системы для обработки, заставляет набор сетевых машин обрабатывать информацию параллельно. Пользователь распределѐнной ОС, вообще говоря, не имеет сведений о том, на какой машине выполняется его работа.
Распределѐнная ОС существует как единая операционная система в масштабах вычислительной системы. Каждый компьютер сети, работающей под управлением распределѐнной ОС, выполняет часть функций этой глобальной ОС. Распределѐнная ОС объединяет все компьютеры сети в том смысле, что они работают в тесной кооперации друг с другом для эффективного использования всех ресурсов компьютерной сети.
b.системы управления кластерами:
Подобная система должна решать, по меньшей мере, следующие классы задач:
Задача обеспечения доступа пользователей к кластеру и создание благоприятной среды для их работы.
Административные задачи управления ресурсами кластера (такими как узлы, пользователи и т.д.), мониторинга используемых ресурсов, ведение и анализ журналов событий различного типа.
Планирование выполнение задач на кластере, а именно распределение задач по времени начала выполнения и по используемым узлам (в общем случае - используемым ресурсам) с целью оптимизации выбранного показателя производительности (в качестве такого показателя обычно выбирается пропускная способность системы).
Например, такой системой является система MOSIX. MOSIX это система управления кластерами и сетями ОС на ядре Linux, представляющая их как одну систему (Single-System Image, SSI), то есть эквивалент операционной системы для кластера в целом. В кластере MOSIX нет необходимости в модификации существующих приложений, в связывании с дополнительными библиотеками, в явном входе на удаленные узлы — все это осуществляется автоматически, прозрачно для приложений подобно SMP.
37.Примеры систем управления кластерами (Condor, Microsoft Compute Cluster Server)
Система управления кластером Condor была создана группой разработчиков университета Висконсин Мэдисон (Wisconsin Madison). Первая конфигурация была развернута в этом университете в 1986 году. Ключевые особенности системы:
–Создание контрольных точек с возможностью миграции заданий между процессами
–Возможность интеграции в Grid
–Поддержка широкого круга архитектур и операционных систем
–Использование для вычислений не только выделенных машин, но и рабочих станций
Типы узлов в системе:
–Центральный менеджер. Ядро системы. Собирает информацию о загрузке узлов кластера и получает запросы пользователей, он затем определяет время и место запуска. Остановка менеджера приведет к остановке всей системы
–Выполняющие машины. Счетные узлы. Производительность выполняющих машин в конечном итоге определяет, когда пользователь получит результат. Однако, Condor создавался с намерением использовать все доступные ресурсы, в том числе и низкопроизводительные
–Запускающие машины. Узлы, с которых производится запуск пользовательских заданий. Во время работы задания на запускающей машине будут выполняться некоторые служебные процессы, которые обеспечивают доступ удаленных процессов к локальным файлам
–Сервер контрольных точек. Узел для хранения всех контрольных точек пользовательских заданий. От узла требуется большой объем оперативной памяти и надежное сетевое соединение/
MicrosoftCCS:
Сравнительно новая система управления кластером (9 июня 2006 года – дата выхода первого релиза) Первая система управления, предназначенная исключительно
для Windows
Ключевые особенности системы:
–Наличие параллельного отладчика MPI – программ
–Автоматическое освобождение ресурсов при аварийной остановке задания
–Интеграция с средствами администрирования Windows Server: Active Directory, Microsoft Operations Manager 2005, Systems Management Server 2003, MMC 3.0
Управление может осуществляться через графический (основной), командный, программный интерфейсы. Выполняют планирование задач, руководствуясь следующей схемой. Каждой задаче в приложении ставится в соответствие некоторый приоритет. Чем больше приоритет, тем выше должна быть реактивность задачи. Высокая реактивность достигается путѐм реализации подхода приоритетного вытесняющего планирования (preemptivepriorityscheduling), суть которого заключается в том, что планировщику разрешается останавливать выполнение любой задачи в произвольный момент времени, если установлено, что другая задача должна быть запущена незамедлительно.
Описанная схема работает по следующему правилу: если две задачи одновременно готовы к запуску, но первая обладает высоким приоритетом, а вторая низким, то планировщик отдаст предпочтение первой. Вторая задача будет запущена только после того, как завершит свою работу первая.
Возможна ситуация, когда задача с низким приоритетом уже запущена, а планировщик получает сообщение, что другая задача с более высоким приоритетом готова к запуску. Причиной этому может послужить какое-либо внешнее воздействие (прерывание от оборудования), как, например, изменение состояния переключателя устройства. В такой ситуации планировщик задач поведет себя согласно подходу приоритетного вытесняющего планирования следующим образом. Задаче с низким приоритетом будет позволено выполнить до конца текущую ассемблерную команду (но не команду, описанную в исходнике программы языком высокого уровня), после чего выполнение задачи останавливается. Далее запускается задача с высоким приоритетом. После того, как она прорабатывает, планировщик запускает прерванную первую задачу с ассемблерной команды, следующей за последней выполненной.
Каждый раз, когда планировщик задач получает сигнал о наступлении некоторого внешнего события (триггер), причина которого может быть как аппаратная, так и программная, он действует по следующему алгоритму.
• Определяет, должна ли текущая выполняемая задача продолжать работать.
• Устанавливает, какая задача должна запускаться следующей.
• Сохраняет контекст остановленной задачи (чтобы она потом возобновила работу с места останова)
• Устанавливает контекст для следующей задачи.
• Запускает эту задачу.
Эти пять шагов алгоритма также называются переключением задач. Выполнение задачи Обычно задача может находиться в 3-х возможных состояниях:
• Задача выполняется;
• Задача готова к выполнению;
• Задача заблокирована.
Большую часть времени основная масса задач заблокирована. Только одна задача может выполняться на центральном процессоре в текущий момент времени.
Если в списке готовых к выполнению задач последних имеется не больше двух-трех, то предполагается, что все задачи расположены в оптимальном порядке. Если же случаются такие ситуации, что число задач в списке превышает допустимый лимит, то задачи сортируются в порядке приоритета.
Алгоритмы планирования В настоящее время для решения задачи эффективного планирования в ОСРВ наиболее интенсивно развиваются два подхода.
Статические алгоритмы планирования (RMS, RateMonotonicScheduling). Используют приоритетное вытесняющее планирование. Приоритет присваивается каждой задаче до того, как она начала выполняться. Преимущество отдается задачам с самыми короткими периодами выполнения.
Динамические алгоритмы планирования (EDF, EarliestDeadlineFirstScheduling). Приоритет задачам присваивается динамически, причем предпочтение отдается задачам с наиболее ранним предельным временем начала (завершения) выполнения.
При больших загрузках системы EDF более эффективен, нежели RMS.
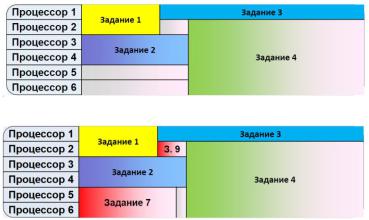
38.Типы узлов в системе Condor
Типы узлов в системе:
–Центральный менеджер. Ядро системы. Собирает информацию о загрузке узлов кластера и получает запросы пользователей, он затем определяет время и место запуска. Остановка менеджера приведет к остановке всей системы
–Выполняющие машины. Счетные узлы. Производительность выполняющих машин в конечном итоге определяет, когда пользователь получит результат. Однако, Condor создавался с намерением использовать все доступные ресурсы, в том числе и низкопроизводительные
–Запускающие машины. Узлы, с которых производится запуск пользовательских заданий. Во время работы задания на запускающей машине будут выполняться некоторые служебные процессы, которые обеспечивают доступ удаленных процессов к локальным файлам
–Сервер контрольных точек. Узел для хранения всех контрольных точек пользовательских заданий. От узла требуется большой объем оперативной памяти и надежное сетевое соединение.
39.Планировщики заданий, функции и принципы их работы
Планировщик заданий отвечает за распределение доступных кластерных ресурсов между задачами. В случае превышения требованиями задач доступных ресурсов кластера, они образуют очередь заданий, управляемую также планировщиком заданий.
Существует несколько широко применяемых алгоритмов планирования заданий. Самые простые алгоритмы принимают решение о выделении ресурсов основываясь на текущем состоянии очереди: когда на кластере освобождается достаточное число ресурсов, их занимает следующая задача. Простейший способ определения очередности дает алгоритм FIFO (First input first output). Следующая задача определяется по времени постановки в очередь. Другим примером является алгоритм SJF(smallest jobs first) и LJF(largest jobs first). Данные задачи выбирают очередную задачу согласно числу требуемых ресурсов. Наиболее часто применяется алгоритм обратного заполнения Backfill. Данный алгоритм использует данные не только о текущем состоянии очереди, но и проводит процесс планирования, определяя требования к ресурсам на протяжении определенного времени. Если результаты планирования показывают наличие свободных ресурсов, недостаточных для первоочередных заданий, то подключается процесс обратного заполнения: производится поиск задачи в очереди, подходящей по запросам к доступному объему ресурсов. Поиск задачи также может проходить с использованием различных стратегий. Стратегия Best Fit производит поиск задачи максимально покрывающей доступные ресурсы, стратегия First Fit ищет ближайшую задачу способную поместиться в доступные ресурсы.
Все вышеуказанные алгоритмы планируют размещения задач исходя из их двух основных критериев – объема запрашиваемых вычислительных ресурсов и времени счета. Данные критерии являются условными, поскольку большинство параллельных программ позволяют варьировать число используемых ресурсов, причем сокращение выделенных для расчетов узлов, ведет к увеличению времени счета. Такие задачи называют масштабируемыми или пластичными. Согласно текущим исследованиям, более 80% параллельных задач являются масштабируемыми
40.Алгоритм Backfilling
Алгоритм обратного заполнения (backfilling). Алгоритм является модификацией списочных алгоритмов, применимой при наличии информации о предполагаемом времени работы задач. В этом случае порядок запуска может частично нарушаться за счет более раннего выполнения небольших менее приоритетных задач, если они не замедлят старт более приоритетных ресурсоемких задач. Данный алгоритм является наиболее популярным в настоящее время.
Backfilling‰
• Первая стадия алгоритма обратного заполнения – составление расписания для наиболее приоритетных N задач с учетом
пользовательской оценки требуемого времени
• В расписании образуются окна. В эти периоды процессоры ожидают начала выполнения запланированных заданий
• Вторая стадия алгоритма – заполнение образовавшихся окон менее приоритетными и менее требовательными к
ресурсам задачами
•Таким образом, алгоритм Backfilling старается обеспечить максимальную загрузку кластера в каждый момент времени
При подсчете приоритетов может использоваться следующая информация:
–Приоритет пользователя (например, преподаватель и студент)
–Приоритет, который пользователь поставил своей задаче
–Время ожидания запуска
–Число задач, запущенных пользователем за последний день/неделю/месяц
–Предположительное время выполнения задачи

41. Принципы построения кластеров для реализации многопоточной обработки. Многосерверные Web-сайты
Конфигурация web-сайта из нескольких машин (server farm)
Запросы от клиентов поступают на один из нескольких серверов. Этот сервер обрабатывает пришедший запрос и, если требуется, считывает данные из базы данных, или пишет в нее. Если какойлибо из web-серверов зависает, другие сервера просто принимают на себя дополнительные запросы. Эта конфигурация:
1) обеспечивает распределение нагрузки (load balancing) в том смысле, что нагрузка по обработке запросов распределяется между несколькими серверами; 2) обеспечивает отказоустойчивость системы
(fault tolerance) в том смысле, что при выходе из строя одной машины сам web-сайт не выходит из строя.
42.Проблемы распределения нагрузки и отказоустойчивости
ВИнтернете каждому IP-адресу соответствует одна машина. Как можно распределять нагрузку между несколькими машинами так, чтобы они извне выглядели как один единственный web-сайт?" При конфигурации с одной машиной, на все HTTPзапросы всегда отвечает одна и та же машина. В конфигурации с несколькими машинами все схемы распределения нагрузки между ними используют маршрутизацию (routing), при которой каждый последующий HTTP-запрос передается на (потенциально) другую машину.
43.Схемы распределения нагрузки в многомашинной системе
Самыми распространенными подходами для организации динамического распределения нагрузки являются: - круговой DNS, когда для распределения нагрузки используется DNS-сервер;
- аппаратное распределение нагрузки, когда используется прибор, схожий по своим функциям с маршрутизатором; - программное распределение нагрузки, например, продукт "TCP/IP Network Load Balancing" от Microsoft;
- смешанные схемы, когда используется комбинация аппаратных и программных средств.
44.Круговой DNS
Круговой DNS - это самый простой способ перенаправления HTTP-запросов на несколько серверов. Однако балансировка нагрузки здесь заключается лишь в том, что каждый из серверов получит равное количество запросов. В этом решении совершенно не учитывается, насколько сильно загружен процессор той или иной машины. Поэтому способ чрезвычайно неэффективен для серьезных приложений. Кроме того, эта схема практически не может помочь в случае выхода какой - либо из машин из строя.
Round robin DNS — один из методов распределения нагрузки, или отказоустойчивости за счѐт избыточности количества серверов, с помощью управления ответами DNS-сервера в соответствии с некой статистической моделью. Обычно применяется к таким интернет-протоколам, как веб-серверы, FTP-серверы.
Впростейшем случае Round robin DNS работает, отвечая на запросы не только одним IP-адресом, а списком из нескольких адресов серверов, предоставляющих идентичный сервис. Порядок, в котором возвращаются IP-адреса из списка, основан на алгоритме round-robin. С каждым ответом последовательность ip-адресов меняется. Как правило, простые клиенты пытаются устанавливать соединения с первым адресом из списка, таким образом разным клиентам будут выданы адреса разных серверов, что распределит общую нагрузку между серверами.
Не существует стандартной процедуры для определения того, какие адреса будут использоваться запрашивающим приложением — некоторые серверы пытаются изменить порядок списка, уделяя приоритетное внимание численно более «близким» сетям. Некоторые настольные клиенты пытаются получить альтернативные адреса после того, как не удалось установить соединение в течение 30-45 секунд.
Круговая система DNS часто используется для распределения нагрузки территориально распределѐнных веб-серверов. Например, у компании есть один домен и три идентичных веб-сайта, расположенных на трѐх серверах с тремя разными адресами. Когда один пользователь получает доступ к главной странице, он будет направлен на первый адрес IP. Второй пользователь, обращающийся к главной странице, будет отправлен на следующий адрес IP, а третий пользователь будет отправлен на третий адрес IP. В каждом случае, когда IP-адрес выдается, он отправляется в конец списка. Четвертый пользователь, следовательно, будет отправлен вновь на первый адрес IP, и так далее.
Недостатки
Хотя Round robin DNS (RR DNS) легко реализовать, всѐ же этот алгоритм имеет несколько проблематичных недостатков, связанных с кэшированием записи в иерархии RR DNS самого себя, а также с кэшированием на стороне клиента, выданного адреса и его повторного использования, сочетание которых трудно управляемо. RR DNS не опирается на доступность услуг. К примеру, если сервис на одном из адресов недоступен, RR DNS будет продолжать раздавать этот адрес и клиенты будут попрежнему пытаться соединиться с неработающим сервером.
Кроме того, оно не может быть лучшим выбором для балансировки нагрузки на самого себя, поскольку он лишь заменяет порядок адресов каждый раз, когда имя сервера запрашивается. Не существует учѐта соответствия IP-адреса пользователя и его географического расположения, времени выполнения, нагрузки на сервер, перегрузки сети и т.д. Круговая система DNS нагрузки лучше всего подходит для услуг с большим количеством равномерно распределенных соединений с серверами эквивалентной мощности. В противном случае он просто делает распределение нагрузки.
Существуют методы, чтобы преодолеть такие ограничения. Например, модифицированные DNS-сервера (такие, как lbnamed) могут регулярно опрашивать зеркала серверов для проверки их доступности и нагруженности. Если сервер не отвечает по мере необходимости, сервер может быть временно удалѐн из пула DNS, пока он не сообщит, что опять работает в соответствии со спецификацией.
Кроме того, при такой схеме у вас возникнут проблемы:
- с Java-апплетами, так как Java-апплеты в принципе могут общаться только с той машиной, с которой они были загружены. - с SSL-соединениями
- с поддержкой сессий

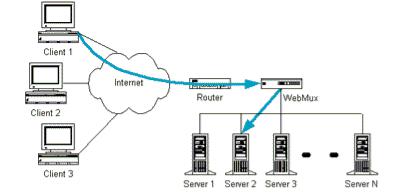
45.Аппаратное распределение нагрузки
Намного более надежной альтернативой круговому DNS является использование для распределения нагрузки специальных устройств. В сеть между другим сетевым оборудованием (сетевым экраном, маршрутизатором и т.д.) и web-серверами добавляется новый элемент, который называется аппаратным распределителем нагрузки (Hardware Load Balancer, WebMux см. рис).
Все запросы пользователей, адресованные на определенный URL проходят через распределитель. К нему подключается группа web-серверов, которые ведут себя, как один сервер. Эта конфигурация называется кластером (cluster). Для всего внешнего мира весь кластер серверов имеет один IP-адрес.
С некоторым упрощением можно считать, что при получении TCP/IP пакетов предназначенных для кластера, распределитель делает следующее:
-принимает решение, какому из серверов кластера следует направить следующий запрос;
-опрашивает (или оценивает, наблюдая за трафиком) все сервера и приложения (т.е. определенный TCP/IP порт) - доступны ли они;
-в некоторых случаях проверяет, возвращает ли сервер корректные данные. Это особенно критично в тех случаях, когда сервер отвечает, но вот в ответ он все время выдает "HTTP Error 404";
-переделывает IP-заголовок пакета так, что он уходит определенному серверу. Эта переделка называется "преобразованием сетевого адреса" (network address translation);
-отправляет клиентский пакет на сервер;
-когда сервер отвечает клиенту, распределитель производит такое же преобразование всех пакетов и возвращает их клиенту. В результате этого второго преобразования клиент получает TCP/IP-пакеты в таком виде, как если бы они были получены от определенного IP-адреса, который закреплен за кластером.
Таким образом, web-сервер будет способен функционировать до тех пор, пока будет работать хотя бы одна серверная машина в кластере.
46.Программное распределение нагрузки
При программном распределении нагрузки (речь идет о решении от Microsoft - Windows Load Balancing Service, или WLBS) на каждый сервер ставится особе программное обеспечение, которое завязывает сервера в единый кластер с единым IP-адресом. Этот IP-адрес и присваивается доменному имени сайта. Каждой машине присваивается свой идентификатор в кластере от 1 до
32 (максимальное число машин в кластере 32). Кроме того, назначается весовой коэффициент, так как машины могут иметь разный объем ресурсов, и устанавливается набор правил.
При установке распределителя, между TCP/IP стеком и драйвером сетевой карты внедряется программный фильтр, который определяет, какой из серверов должен обработать запрос и только определенный сервер отвечает на запрос. Поскольку этот распределитель является программой, у него больше средств объективно оценивать способности машины обработать запрос. Ему доступным процент загрузки процессора, объем свободной памяти, и объем свободного места на диске и т.п. Так как принцип работы построен на фильтрации пакетов, а не на преобразовании их заголовков, программный распределитель работает быстрее, чем аппаратный.
Обычно на каждую машину устанавливают еще одну сетевую плату, через которую машины в кластере общаются между собой и с базой данных (см. рис).
При этом весь приходящий трафик идет через первый сетевой интерфейс (с которым взаимодействует распределитель), а весь межмашинный трафик идет через второй интерфейс, так что администрирование машин и прочие сервисы не мешают работе web-серверов.
47.Смешанные схемы
На практике встречаются также смешанные схемы, когда работают вместе аппаратные и программные распределители нагрузки. Например, в системе может использоваться один аппаратный распределитель нагрузки (и еще один запасной) и два кластера серверов, в которых используются программные распределители нагрузки. Аппаратный распределитель «не знает» о том, что за двумя IP-адресами скрывается целая группа машин. Точно также, каждый из кластеров «не догадывается» о существовании своего соседа. Используя смешанную схему можно легко превысить предел в 32 машины, устанавливаемый программным распределителем.
48.Проблема привязки (affinity) и варианты ее решения, в частности на основе механизма cookies
При использовании балансировщиков нагрузки возникает проблема. Соединения равномерно распределяются между машинами, значит, что соединение определенного клиента с определенным сервером при продолжении сеанса взаимодействия после предыдущего элементарного акта обмена, закончившегося разрывом TCP – соединения, просто не гарантируется, если не принять специальных мер. В частности, была предложена технология, которая называется "привязка" (affinity). Она есть в распределителях (load balancer) как в аппаратных, так и в программных. "Привязка" означает, что по началу сессии клиент направляется на любую машину, и на протяжении всей сессии поддерживает соединение только с ней.
Рисунок. Привязка пользователя к определенному серверу
Ксожалению, при использовании привязки эффективность распределения нагрузки падает, так как клиенты распределяются между серверами по оценке состояния машин на момент прихода первого запроса. Состояние машины после первого запроса может измениться кардинально, но из-за привязки - она по-прежнему будет получать запросы от клиентов, привязанных к ней.
Другая проблема, возникающая при привязке - это отказоустойчивость. Если привязать пользователя к определенной машине, то теряет смысл наличие дополнительных машин. Например, если
сервер А зависнет или "упадет", все операции и данные пользователей A и B будут потеряны. Решение проблемы привязки
Существует несколько подходов к решению проблемы привязки. Обычно основой этих подходов является анализ и модификация пакетов, передаваемых между клиентом и web – сервером, программным обеспечением балансировщика. Речь идет об анализе и модификации некоторых идентифицирующих клиента признаков (но не IP – адреса клиента!). Вначале использовались довольно ограниченные возможности "невидимых полей" в HTML-формах или организация специального процесса обработки "маркеров", встроенных в указатели ресурсов (URL). У этих методов есть определенные недостатки и более привлекательным является использование в запросах и ответах маркировочных полей, введенных впервые компанией Netscape и названных первоначально "persistent cookies" (в буквальном переводе означает что-то типа "постоянные плюшки").
Инициатором записи cookie выступает сервер. Если в ответе сервера присутствует поле заголовка Set-cookie, клиент воспринимает это как команду на запись cookie. В дальнейшем, если клиент обращается к серверу, от которого он ранее принял поле заголовка Set-cookie, помимо прочей информации он передает серверу данные cookie. Для передачи указанной информации серверу используется поле заголовка cookie.
Для того чтобы в общих чертах представить себе, как происходит обмен данными cookie, рассмотрим следующий пример. Предположим, что клиент передает запросы на серверы А, В и С. Предположим также, что сервер В, в отличие от А и С, передает клиенту команду записать cookie. Последовательность запросов клиента серверу и ответов на них будет выглядеть приблизительно следующим образом.
1.Передача запроса серверу А.
2.Получение ответа от сервера А.
3.Передача запроса серверу В.
4.Получение ответа от сервера В. В состав ответа входит поле заголовка SetCookie. Получив его, клиент записывает cookie на диск.
5.Передача запроса серверу С. Несмотря на то что на диске хранится запись cookie, клиент не предпринимает никаких специальных действий, так как значение cookie было записано по инициативе другого сервера.
6.Получение ответа от сервера С.
7.Передача запроса серверу А. В этом случае клиент также никак не реагирует на тот факт, что на диске хранится cookie.
8.Получение ответа от сервера А.
9.Передача запроса серверу В. Перед тем как сформировать запрос, клиент определяет, что на диске хранится запись cookie, созданная после получения ответа от сервера В. Клиент проверяет, удовлетворяет ли данный запрос некоторым
требованиям, и, если проверка дает положительный результат, включает в заголовок запроса поле cookie.
Таким образом, процедуру записи и получения cookie можно представить себе как своеобразный "запрос" сервера, инкапсулированный в его ответе клиенту. Соответственно получение cookie также можно представить себе как ответ клиента, инкапсулированный в составе запроса тому же серверу.

49.Обеспечение отказоустойчивости кластеров многопоточной обработки
"Кластеры высокой готовности" (HA, High Availability), "кластеры 24 х 7" (24 часа 7 дней в неделю) или "кластеры 365 х 24".
Общая структура типового двухузлового кластера
Существует два вида кластера для надежности -- симметричный и асимметричный. В симметричном кластере все его серверы работают с различными приложениями и в случае выхода из строя любого из серверов оставшиеся перераспределяют между собой его нагрузку по заранее описанным правилам. В асимметричном кластере существует специальный сервер (standby), который не выполняет работы по обслуживанию клиентов, а только отслеживает состояние основных серверов в кластере и при сбое одного из них начинает выполнять его задачи.
С точки зрения такой классификации понятен и следующий подход. В кластерных решениях, ориентированных на надежность, чаще всего используется не более двух компьютеров, поскольку их одновременный выход из строя маловероятен.
Кластер состоит из двух узлов (серверов), подключенных к общему дисковому массиву. Все основные компоненты этого дискового массива
— блок питания, дисковые накопители, контроллер ввода/вывода - имеют резервирование с возможностью горячей замены. Узлы кластера соединены между собой внутренней сетью для обмена информацией о своем текущем состоянии. Электропитание кластера осуществляется от двух независимых источников. Подключение каждого узла к внешней локальной сети также дублируется.
Таким образом, все подсистемы кластера имеют резервирование, поэтому при отказе любого элемента кластер в целом останется в работоспособном состоянии. Более того, замена отказавшего элемента возможна без остановки кластера.

50.Дисковые подсистемы хранения данных и резервного копирования. Системы DAS, SAN, NAS
DAS (direct-attached storage) — устройство внешней памяти, напрямую подсоединенное к основному компьютеру и используемое только им. Простейший пример DAS — встроенный жесткий диск. Для связи хоста с внешней памятью в типовой конфигурации DAS используется SCSI, команды которого позволяют выделить определенный блок данных на специфицированном диске или смонтировать определенный картридж в ленточной библиотеке.
Системы типа DAS состоят из накопителя (например жѐсткого диска), соединенного с компьютером адаптером контроллера шины. Между ними нет сетевого устройства (концентратора, коммутатора или маршрутизатора), и это основной признак DAS.
Основными протоколами для коммуникации в DAS являются ATA, SATA, eSATA[2], SCSI, Serial Attached SCSI и Fibre
Channel.
Конфигурация DAS приемлема для применений, нетребовательных к объемам, производительности и надежности систем хранения. DAS не обеспечивает возможности совместного использования емкости хранения разными хостами и тем более возможности разделения данных. Установка таких устройств хранения — более дешевый вариант по сравнению с сетевыми конфигурациями, однако, если иметь в виду большие организации, этот тип
инфраструктуры хранения нельзя считать оптимальным. Много DASподключений означает разрозненные и разбросанные по всей компании островки внешней памяти, избытки которой не могут использоваться другими хост-компьютерами, что приводит к неэффективной трате емкости хранения в целом. Кроме того, при такой организации хранения нет никакой возможности создать единую точку управления
внешней памятью, что неизбежно усложняет процессы резервирования/восстановления данных и создает серьезную проблему защиты информации. В итоге общая стоимость владения подобной системой хранения может оказаться значительно выше, чем более сложная на первый взгляд и изначально более дорогая сетевая конфигурация. Недостатком DAS является невозможность разделять данные или неиспользуемые ресурсы с другими серверами.
SAN
Сегодня, говоря о системе хранения корпоративного уровня, мы имеем в виду сетевое хранение (storage networking). Больше известны широкой публике сети хранения — SAN (storage area network). SAN представляет собой выделенную сеть устройств хранения, которая позволяет множеству серверов использовать совокупный ресурс внешней памяти без нагрузки на локальную сеть.
SAN не зависит от среды передачи, но на данный момент фактическим стандартом является технология Fibre Channel (FC), обеспечивающая скорость передачи данных 1-2 Гбит/с. В отличие от традиционных сред передачи на базе SCSI, обеспечивающих подключение на расстояние не более чем на 25 метров, Fibre Channel позволяет работать на удалении до 100 км. Средой передачи в сети Fibre Channel могут служить как медный кабель, так и оптоволокно.
В сеть хранения могут подключаться дисковые массивы RAID, простые массивы дисков, (так называемые Just a Bunch of Disks — JBOD), ленточные или магнитооптические библиотеки для резервирования и архивирования данных. Основными компонентами для организации сети SAN помимо самих устройств хранения являются адаптеры для подключения серверов к сети Fibre Channel (host bus adapter —
НВА), cетевые устройства для поддержки той или иной топологии FC-сети и специализированный программный инструментарий для управления сетью хранения. Эти программные системы могут выполняться как на сервере общего
назначения, так и на самих устройствах хранения, хотя иногда часть функций выносится на специализированный тонкий сервер для управления сетью хранения (SAN appliance).

Задача программного обеспечения для SAN — это прежде всего централизованное управление сетью хранения, включая конфигурирование, мониторинг, контроль и анализ компонентов сети. Одной из наиболее важных является функция управления доступом к дисковым массивам, если в SAN хранятся данные разнородных серверов. Сети хранения обеспечивают одновременный доступ множества серверов к множеству дисковых подсистем, привязывая каждый хост к определенным дискам на определенном дисковом массиве.
Для разных операционных систем необходимо расслоение дискового массива на «логические области» (logical unit — LUN), которыми они будут пользоваться без возникновения конфликтов. Выделение логических областей может понадобиться и для организации доступа к одним и тем же данным для некоторого пула серверов, например, серверов одной рабочей группы. За поддержку всех этих операций отвечают специальные программные модули.
Привлекательность сетей хранения объясняется теми преимуществами, которые они могут дать организациям, требовательным к эффективности работы с большими объемами данных. Выделенная сеть хранения разгружает основную (локальную или глобальную) сеть вычислительных серверов и клиентских рабочих станций, освобождая ее от потоков ввода/вывода данных.
Этот фактор, а также высокоскоростная среда передачи, используемая для SAN, обеспечивают повышение производительности процессов обмена данными с внешними системами хранения. SAN означает консолидацию систем хранения, создание на разных носителях единого пула ресурсов, который будет разделяться всеми вычислительными мощностями, и в результате необходимую емкость внешней памяти можно будет обеспечить меньшим числом подсистем. В SAN резервирование данных с дисковых подсистем на ленты происходит вне локальной сети и потому становится более производительным — одна ленточная библиотека может служить для резервирования данных с нескольких дисковых подсистем. Кроме того, при поддержке соответствующего ПО можно реализовать прямое резервирование в SAN без участия сервера, тем самым, разгружая процессор. Возможность разнесения серверов и памяти на большие расстояния отвечает потребностям повышения надежности корпоративных хранилищ данных. Консолидированное хранение данных в SAN лучше масштабируется, поскольку позволяет наращивать емкость хранения независимо от серверов и без прерывания их работы. Наконец, SAN дает возможность централизованного управления единым пулом внешней памяти, что упрощает администрирование.
Безусловно, сети хранения, недешевое и непростое решение и, несмотря на то, что все ведущие поставщики выпускают сегодня устройства для SAN на базе Fibre Channel, их совместимость не гарантируется, и выбор подходящего оборудования создает проблему для пользователей. Понадобятся дополнительные расходы на организацию выделенной сети и покупку управляющего ПО, и начальная стоимость SAN окажется выше организации хранения с помощью DAS, однако совокупная стоимость владения должна быть ниже.
Сеть хранения данных, СХД (англ. Storage Area Network, SAN) — представляет собой архитектурное решение для подключения внешних устройств хранения данных, таких как дисковые массивы, ленточные библиотеки, оптические приводы к серверам таким образом, чтобы операционная система распознала подключѐнные ресурсы как локальные. Несмотря на то, что стоимость и сложность таких систем постоянно падают, по состоянию на 2007 год сети хранения данных остаются редкостью за пределами больших предприятий.
SAN характеризуются предоставлением так называемых сетевых блочных устройств (обычно посредством протоколов Fibre Channel, iSCSI или AoE), в то время как сетевые хранилища данных (англ. Network Attached Storage, NAS) нацелены на предоставление доступа к хранящимся на их файловой системе данным при помощи сетевой файловой системы (такой как
NFS, SMB/CIFS, или Apple Filing Protocol).
Следует обратить внимание, что категорическое разделение вида «SAN — это только сетевые диски, NAS — это только сетевая файловая система» является искусственным: с появлением iSCSI началось взаимное проникновение технологий с целью повышения гибкости и удобства их применения. Например, в 2003 году NetApp уже предоставляли iSCSI на своих NAS, а EMC и HDS — наоборот, предлагали NAS-шлюзы для своих SAN-массивов.
Типы сетей
SAN-Свитч Qlogic SANbox 5600 с подключѐнными к нему оптическими коннекторами Fibre Channel.
Большинство сетей хранения данных использует протокол SCSI для связи между серверами и устройствами хранения данных на уровне шинной топологии. Так как протокол SCSI не предназначен для формирования сетевых пакетов, в сетях хранения данных используются низкоуровневые протоколы:
•Fibre Channel Protocol (FCP), транспорт SCSI через Fibre Channel. Наиболее часто используемый на данный момент протокол. Существует в вариантах 1 Gbit/s, 2 Gbit/s, 4 Gbit/s, 8 Gbit/s, 10 Gbit/s, 16 Gbit/s, 20 Gbit/s.
•iSCSI, транспорт SCSI через TCP/IP.
•iSER, транспорт iSCSI через InfiniBand / RDMA.
•SRP, транспорт SCSI через InfiniBand / RDMA
•FCoE, транспортировка FCP/SCSI поверх «чистого» Ethernet.
•FCIP и iFCP, инкапсуляция и передача FCP/SCSI в пакетах IP.
•HyperSCSI, транспорт SCSI через Ethernet.
•FICON транспорт через Fibre Channel (используется только мейнфреймами).
•ATA over Ethernet, транспорт ATA через Ethernet.
Совместное использование устройств хранения Движущей силой для развития сетей хранения данных стал взрывной рост объема деловой информации (такой как электронная
почта, базы данных и высоконагруженные файловые серверы), требующей высокоскоростного доступа к дисковым