

EKZAMEN
.pdf18.Обеспечение изолированности процессов на аппаратном уровне в реальных процессорах
Одна из важнейших целей, которые ставятся при разработке многозадачных сис-тем, заключается в том, чтобы разные процессы, одновременно работающие в системе, были как можно лучше изолированы друг от друга. Это означает, что процессы (в идеале) не должны ничего знать даже о существовании друг друга. Для каждого процесса ОС пре-доставляет виртуальную машину, т.е. полный набор ресурсов, имитирующий выполне-ние процесса на отдельном компьютере.
Изоляция процессов, во-первых, является необходимым условием надежности и безопасности многозадачной системы. Один процесс не должен иметь возможности вме-шаться в работу другого или получить доступ к его данным, ни по случайной ошибке, ни намеренно.
Во-вторых, проектирование и отладка программ чрезвычайно усложнились бы, если бы программист должен был учитывать непредсказуемое влияние других процессов.
С другой стороны, есть ситуации, когда взаимодействие необходимо. Процессы могут совместно обрабатывать общие данные, обмениваться сообщениями, ждать ответа и т.п. Система должна предоставлять в распоряжение процессов средства взаимодействия. Это не противоречит тому, что выше было сказано об изоляции процессов. Чтобы взаимо-действие не привело к полному хаосу, оно должно выполняться только с помощью тех хорошо продуманных средств, которые предоставляет процессам ОС. За пределами этих средств действует изоляция процессов.
Для защиты процессов друг от друга операционная система может использовать изоляцию процессов (process isolation). Изоляция процессов необходима, чтобы процессы «не наступали друг другу на ноги», взаимодействуя небезопасным образом, и не оказыва-ли негативного влияния на производительность друг друга.
Для реализации изоляции процессов могут использоваться различные методы:
• Инкапсуляция объектов
• Временное мультиплексирование общих ресурсов
• Разделение имен
• Виртуальное отображение Когда процесс инкапсулирован, никакие другие процессы не могут взаимодейст-вовать с его внутренним кодом.
Временное мультиплексирование – это технология, которая позволяет процес-сам использовать одни и те же ресурсы. Разделение имен просто означает, что все процессы имеют собственное уникаль-ное имя или идентификатор.
Отображение виртуального адресного пространства отличается от физиче-ского отображения памяти. Для приложений создается иллюзия того, что каждое из них является единственным запущенным приложением в операционной системе. Когда при-ложению требуется память для работы, оно говорит менеджеру памяти операционной системы, сколько памяти ему нужно. Операционная система выделяет необходимый объем памяти и связывает его с запрашивающим приложением.
Виртуализация — это изоляция вычислительных процессов и ресурсов друг от друга Аппаратная виртуализация — виртуализация с аппаратной поддержкой. Не отличаясь принципиально от программной,
аппаратная виртуализация обеспечила производительность, сравнимую с производительностью невиртуализованной машины, что дало виртуализации возможность практического использования и повлекло еѐ широкое распространение.
Преимущества:
•Упрощение разработки программных платформ виртуализации за счет предоставления аппаратных интерфейсов управления и поддержки виртуальных гостевых систем. Это уменьшает трудоемкость и время на разработку систем виртуализации.
•Возможность увеличения быстродействия платформ виртуализации. Управление виртуальными гостевыми системами осуществляет напрямую небольшой промежуточный слой программного обеспечения, гипервизор, что дает увеличение быстродействия.
•Улучшается защищѐнность, появляется возможность переключения между несколькими запущенными независимыми платформами виртуализации на аппаратном уровне. Каждая из виртуальных машин может работать независимо, в своем пространстве аппаратных ресурсов, полностью изолированно друг от друга. Это позволяет устранить потери быстродействия на поддержание хостовой платформы и увеличить защищенность.
•Гостевая система становится не привязана к архитектуре хостовой платформы и к реализации платформы виртуализации. Технология аппаратной виртуализации делает возможным запуск 64-битных гостевых систем на 32-битных хостовых системах (с 32-битными средами виртуализации на хостах).
Технологии:
•Режим виртуального 8086 — старая
•Intel VT (VT-x) — Intel Virtualization Technology for x86
•AMD-V
19.Особенности программирования многопроцессорных вычислительных систем
Ксистемам этого типа относятся компьютеры с SMP архитектурой, различные разновидности NUMA систем и мультипроцессорные векторно-конвейерные компьютеры. Характерным словом для этих компьютеров является ―единый‖: единая оперативная память, единая операционная система, единая подсистема ввода-вывода. Только процессоры образуют множество. Единая UNIX-подобная операционная система, управляющая работой всего компьютера, функционирует в виде множества процессов. Каждая пользовательская программа также запускается как отдельный процесс. Операционная система сама каким-то образом распределяет процессы по процессорам. В принципе, для распараллеливания программ можно использовать механизм порождения процессов. Однако этот механизм не очень удобен, поскольку каждый процесс функционирует в своем адресном пространстве, и основное достоинство этих систем – общая память – не может быть использован простым и естественным образом. Для распараллеливания программ используется механизм порождения нитей (threads) – легковесных процессов, для которых не создается отдельного адресного пространства, но которые на многопроцессорных системах также распределяются по процессорам. В языке программирования C возможно прямое использование этого механизма для распараллеливания программ посредством вызова соответствующих системных функций, а в компиляторах с языка FORTRAN этот механизм используется либо для автоматического распараллеливания, либо в режиме задания распараллеливающих директив компилятору (такой подход поддерживают и компиляторы с языка С).
Все производители симметричных мультипроцессорных систем в той или иной мере поддерживают стандарт POSIX Pthread и включают в программное обеспечение распараллеливающие компиляторы для популярных языков программирования или предоставляют набор директив компилятору для распараллеливания программ. В частности, многие поставщики компьютеров SMP архитектуры (Sun, HP, SGI) в своих компиляторах предоставляют специальные директивы для распараллеливания циклов. Однако эти наборы директив, во-первых, весьма ограничены и, во-вторых, несовместимы между собой. В результате этого разработчикам приходится распараллеливать прикладные программы отдельно для каждой платформы.
В последние годы все более популярной становится система программирования OpenMP , являющаяся во многом обобщением и расширением этих наборов директив. Интерфейс OpenMP задуман как стандарт для программирования в модели общей памяти. В OpenMP входят спецификации набора директив компилятору, процедур и переменных среды. По сути дела, он реализует идею "инкрементального распараллеливания", позаимствованную из языка HPF (High Performance Fortran – Fortran для высокопроизводительных вычислений). Разработчик не создает новую параллельную программу, а просто добавляет в текст последовательной программы OpenMP-директивы. При этом система программирования OpenMP предоставляет разработчику большие возможности по контролю над поведением параллельного приложения. Вся программа разбивается на последовательные и параллельные области. Все последовательные области выполняет главная нить, порождаемая при запуске программы, а при входе в параллельную область главная нить порождает дополнительные нити. Предполагается, что OpenMPпрограмма без какой-либо модификации должна работать как на многопроцессорных системах, так и на однопроцессорных. В последнем случае директивы OpenMP просто игнорируются. Следует отметить, что наличие общей памяти не препятствует использованию технологий программирования, разработанных для систем с распреде-ленной памятью. Многие производители SMP систем предоставляют также такие технологии программирования, как MPI и PVM. В этом случае в качестве коммуникационной среды выступает разделяемая память.
20.Взаимодействие и синхронизация потоков и процессов в вычислительных системах с общей памятью
Взаимодействие процессов Для нормального функционирования процесса, ОС старается максимально обособить их друг от друг. Каждый процесс имеет
собственное адресное пространство нарушение, которого приводит к аварийной остановке процесса. Каждому процессу по возможности предоставляется свои дополнительные ресурсы . Тем не менее для решения некоторых задач процессы могут объединить свои усилия. Причины их взаимодействия следующие:
1)Повышение скорости работы, пока один процесс ожидает наступление некоторого события, другие могут заниматься полезной работой направленное на решение общих задач. В многопроцессорных системах программа разбивается на отдельные кусочки, каждая из которых будет выполняться на своѐм процессоре.
2)Совместное использование данных. Различные процессы могут работать с одной и той же динамической базой данных или с разделѐнным файлом, совместно изменяя их содержание.
3)Реализация модульной конструкции системы. Примером может служить микроядерный способ построения ОС. Когда различные еѐ части представляют отдельные процессы, взаимодействующие путѐм передачи сообщений через микроэлемент.
4)Повышение удобства работы пользователя желающего, например, редактировать и отлаживать программу одновременно. В этой ситуации редактора и отладчика должны взаимодействовать друг с другом.
Процесс который оказывает влияние на поведение друг друга принято называть кооперативным или взаимодействующими процедурами. В отличии от независимых процессов не оказывающих друг на друга никакого воздействия и ничего не знающих о взаимном сосуществовании в вычислительной системе.
Синхронизация процессов. Проблема race condition
АКТИВНОСТИ - под активностями будем понимать последовательное выполнение некоторых действий, направленных на достижение определенной цели. Активности могут иметь место в программном и техническом обеспечении, в обычной деятельности людей и животных. Мы будем разбивать активности на некоторые неделимые или атомарные операции. Например, активность ―приготовление бутерброда‖ можно разбить на следующие атомарные операции:
1.Отрезать ломтик хлеба.
2.Отрезать ломтик колбасы.
3.Намазать ломтик хлеба маслом.
4.Положить ломтик колбасы на подготовленный ломтик хлеба.
Неделимые операции могут иметь некоторые внутренние невидимые действия (взять батон хлеба в левую руку, взять нож в правую руку, собственно произвести отрезание). Мы же называем их неделимыми потому, что считаем одним целым, выполняемыми за раз, без прерывания деятельности.
Пусть имеется две активности
P:a b c
Q:d e f,
где a, b, c, d, e, f атомарные операции. При последовательном выполнении активностей мы получаем следующую последовательность атомарных действий:
PQ: a b c d e f
Будем говорить, что набор активностей (например, программ) детерминирован, если всякий раз при псевдопараллельном исполнении для одного и того же набора входных данных он дает одинаковые выходные данные. В противном случае он недетерминирован.
Про недетерминированный набор программ (и активностей вообще) говорят, что он имеет race condition (состояние гонки, состояние состязания).
Задачу упорядоченного доступа к разделяемым данным (устранение race condition), в том случае, если нам не важна его очередность, можно решить, если обеспечить каждому процессу эксклюзивное право доступа к этим данным. Каждый процесс, обращающийся к разделяемым ресурсам, исключает для всех других процессов возможность одновременного с ним общения с этими ресурсами, если это может привести к недетерминированному поведению набора процессов. Такой прием называется взаимоисключением (mutual exclusion). Если очередность доступа к разделяемым ресурсам важна для получения правильных результатов, то одними взаимоисключеньями уже не обойтись.
Критическая секция
Важным понятием при изучении способов синхронизации процессов является понятие критической секции (critical section) программы.
Критическая секция – это часть программы, исполнение которой может привести к возникновению race condition (состояние гонки, состояние состязания) для определенного набора программ.
Чтобы исключить эффект гонок по отношению к некоторому ресурсу, необходимо организовать работу так, чтобы в каждый момент времени только один процесс мог находиться в своей критической секции, связанной с этим ресурсом. Иными словами, необходимо обеспечить реализацию взаимоисключения для критических секций программ.
Реализация взаимоисключения для критических секций программ с практической точки зрения означает, что по отношению к другим процессам, участвующим во взаимодействии, критическая секция начинает выполняться как атомарная операция. Рассмотрим следующий пример, в котором псевдопараллельные взаимодействующие процессы представлены действиями различных студентов:
Допустим три студента поочередно приходят в комнату и обнаруживают что нет хлеба. В итоге эти три студента идут в той же последовательности в магазин и покупают по 2 батона на всех. В итоге 6 батонов хлеба!!!
Сделать процесс добывания хлеба атомарной операцией можно было бы следующим образом: перед началом этого процесса закрыть дверь изнутри на засов и уходить добывать хлеб через окно, а по окончании процесса вернуться в комнату через окно и отодвинуть засов. Тогда пока один студент добывает хлеб, все остальные находятся в состоянии ожидания под дверью.
Итак, для решения задачи необходимо, чтобы в том случае, когда процесс находится в своем критическом участке, другие процессы не могли войти в свои критические участки. Мы видим, что критический участок должен сопровождаться прологом (entry section) – "закрыть дверь изнутри на засов" – и эпилогом (exit section) – "отодвинуть засов", которые не имеют отношения к активности одиночного процесса. Во время выполнения пролога процесс должен, в частности, получить разрешение на вход
вкритический участок, а во время выполнения эпилога – сообщить другим процессам, что он покинул критическую секцию.
Вобщем случае структура процесса, участвующего во взаимодействии, может быть представлена следующим образом: while (some condition) {
entry section critical section exit section
remainder section
}
Здесь под remainder section понимаются все атомарные операции, не входящие в критическую секцию. Требования, предъявляемые к организации взаимодействия процессов, имеющих критические участки
Сформулируем пять условий, которые должны выполняться для хорошего программного алгоритма организации взаимодействия процессов, имеющих критические участки, если они могут проходить их в произвольном порядке:
1.Задача должна быть решена чисто программным способом на обычной машине, не имеющей специальных команд взаимоисключения. При этом предполагается, что основные инструкции языка программирования (такие примитивные инструкции как load, store, test) являются атомарными операциями.
2.Не должно существовать никаких предположений об относительных скоростях выполняющихся процессов или числе процессоров, на которых они исполняются.
3.Если процесс Pi исполняется в своем критическом участке, то не существует никаких других процессов, которые исполняются в своих соответствующих критических секциях. Это условие получило название условия взаимоисключения
(mutual exclusion).
4.Процессы, которые находятся вне своих критических участков и не собираются входить в них, не могут препятствовать другим процессам входить в их собственные критические участки. Если нет процессов в критических секциях, и имеются процессы, желающие войти в них, то только те процессы, которые не исполняются в remainder section, должны принимать решение о том, какой процесс войдет в свою критическую секцию. Такое решение не должно приниматься бесконечно долго. Это условие получило название условия прогресса (progress).
5.Не должно возникать бесконечного ожидания для входа процесса в свой критический участок. От того момента, когда процесс запросил разрешение на вход в критическую секцию, и до того момента, когда он это разрешение получил, другие процессы могут пройти через свои критические участки лишь ограниченное число раз. Это условие получило название условия ограниченного ожидания (bound waiting).
Семафоры. Задача производитель – потребитель Одним из первых механизмов, предложенных для синхронизации поведения процессов, стали семафоры, концепцию которых описал Дейкстра (Dijkstra) в 1965 году.
Семафор представляет собой целую переменную, принимающую неотрицательные значения, доступ любого процесса к которой, за исключением момента ее инициализации, может осуществляться только через две атомарные операции: P (от датского слова proberen — проверять) и V (от verhogen — увеличивать). Классическое определение этих операций выглядит следующим образом:
P(S): пока S == 0 процесс блокируется;
S = S – 1; V(S): S = S + 1;
Эта запись означает следующее: при выполнении операции P над семафором S сначала проверяется его значение. Если оно больше 0, то из S вычитается 1. Если оно меньше или равно 0, то процесс блокируется до тех пор, пока S не станет больше 0, после чего из S вычитается 1. При выполнении операции V над семафором S к его значению просто прибавляется 1.
Одной из типовых задач, требующих организации взаимодействия процессов, является задача производитель-потребитель. Пусть два процесса обмениваются информацией через буфер ограниченного размера. Производитель закладывает информацию в буфер, а потребитель извлекает ее оттуда. Грубо говоря, на этом уровне деятельность потребителя и производителя можно описать следующим образом.
Producer: while(1) { produce_item; put_item;
}
Consumer:
while(1) { get_item; consume_item;
}
Если буфер забит, то производитель должен ждать, пока в нем появится место, чтобы положить туда новую порцию информации. Если буфер пуст, то потребитель должен дожидаться нового сообщения.
Возьмем три семафора empty, full и mutex. Семафор full будем использовать для гарантии того, что потребитель будет ждать, пока в буфере появится информация. Семафор empty будем использовать для организации ожидания производителя при заполненном буфере, а семафор mutex - для организации взаимоисключения на критических участках, которыми являются действия put_item и get_item (операции положить информацию и взять информацию не могут пересекаться, так как тогда возникнет опасность искажения информации). Тогда решение задачи выглядит так:
Semaphore mutex = 1;
Semaphore empty = N, где N – емкость буфера;
Semaphore full = 0; Producer:
while(1) { produce_item; P(empty); P(mutex); put_item; V(mutex); V(full);
}
Consumer: while(1) { P(full); P(mutex); put_item; V(mutex); V(empty); consume_item;
}
Легко убедиться, что это действительно корректное решение поставленной задачи. Попутно заметим, что семафоры использовались здесь для достижения двух целей: организации взаимоисключения на критическом участке и синхронизации скорости работы процессов.
Мониторы. Задача производитель – потребитель Хотя решение задачи производитель – потребитель с помощью семафоров выглядит достаточно элегантно, программирование
с их использованием требует повышенной осторожности и внимания, чем, отчасти, напоминает программирование на языке ассемблера. Допустим, что потребитель, войдя в свой критический участок (mutex сброшен), обнаруживает, что буфер пуст. Он блокируется и начинает ждать появления сообщений. Но производитель не может войти в критический участок, для передачи информации, так как тот заблокирован потребителем. Получаем тупиковую ситуацию.
В сложных программах произвести анализ правильности использования семафоров с карандашом в руках становится очень непростым занятием. В то же время обычные способы отладки программ зачастую не дают результата, поскольку возникновение ошибок зависит от interleaving’а атомарных операций, и ошибки могут быть трудно воспроизводимы. Для того чтобы облегчить труд программистов, в 1974 году Хором (Hoare) был предложен механизм еще более высокого уровня, чем семафоры, получивший название мониторов.
Мониторы представляют собой тип данных, который может быть с успехом внедрен в объектно-ориентированные языки программирования. Монитор обладает своими собственными переменными, определяющими его состояние. Значения этих переменных извне монитора могут быть изменены только с помощью вызова функций-методов, принадлежащих монитору. В свою очередь, эти функции-методы могут использовать в своей работе только данные, находящиеся внутри монитора и свои параметры. На абстрактном уровне можно описать структуру монитора следующим образом:
monitor monitor_name {
описание переменных ; void m1(...){...
}
void m2(...){...
}
...
void mn(...){...
}
{
блок инициализации внутрениих переменных ;
}
}
Здесь функции m1,..., mn представляют собой функции-методы монитора, а блок инициализации внутренних переменных содержит операции, которые выполняются только один раз: при создании монитора или при самом первом вызове какой-либо функции-метода до ее исполнения.
Важной особенностью мониторов является то, что в любой момент времени только один процесс может быть активен, т. е. находиться в состоянии готовность или исполнение, внутри данного монитора. Поскольку мониторы представляют собой особые конструкции языка программирования, то компилятор может отличить вызов функции, принадлежащей монитору, от вызовов других функций и обработать его специальным образом, добавив к нему пролог и эпилог, реализующий взаимоисключение.
Если функция монитора не может выполняться дальше, пока не наступит некоторое событие, она выполняет операцию wait над какой-либо условной переменной. При этом процесс, выполнивший операцию wait, блокируется, становится неактивным, и другой процесс получает возможность войти в монитор.
Когда ожидаемое событие происходит, другой процесс внутри функции-метода совершает операцию signal над той же самой условной переменной. Это приводит к пробуждению ранее заблокированного процесса, и он становится активным. Хор предложил, чтобы пробужденный процесс подавлял исполнение разбудившего процесса, пока он сам не покинет монитор. Несколько позже Хансен (Hansen) предложил другой механизм: разбудивший процесс покидает монитор немедленно после исполнения операции signal.
Применим концепцию мониторов к решению задачи производитель-потребитель . monitor ProducerConsumer {
condition full, empty; int count;
void put() {
if(count == N) full.wait; put_item;
count += 1;
if(count == 1) empty.signal;
}
void get() {
if (count == 0) empty.wait; get_item();
count -= 1;
if(count == N-1) full.signal;
}
{
count = 0;
}
}
Producer: while(1) { produce_item;
ProducerConsumer.put();
}
Consumer: while(1) {
ProducerConsumer.get(); consume_item;
}
Реализация мониторов требует разработки специальных языков программирования и компиляторов для них. Мониторы встречаются в таких языках как параллельный Евклид, параллельный Паскаль, Java и т.д.
Тупик (взаимоблокировка)
Если несколько процессов конкурируют за обладание конечным числом ресурсов и запрашиваемый процессом ресурс недоступен, процесс переходит в состояние ожидания. В случае если требуемый ресурс удерживается другим ожидающим процессом, то первый процесс не сможет сменить свое состояние. Такая ситуация называется тупиком. Говорят, что в мультипрограммной системе процесс находится в состоянии тупика, дедлока (deadlock) или клинча, если он ожидает события, которое никогда не произойдет. Системная тупиковая ситуация или зависание системы является следствием того, что один или более процессов находятся в состоянии тупика.
Тупики также могут иметь место в ситуациях, не требующих выделенных ресурсов. Например, в системах управления базами данных процессы могут локализовывать записи, чтобы избежать гонок. В этом случае может получиться так, что один из процессов заблокировал записи, требуемые другому процессу и наоборот. Т.о. тупики могут иметь место, как на аппаратных, так и на программных ресурсах.
Определение. Множество процессов находится в тупиковой ситуации, если каждый процесс из множества ожидает события, которое только другой процесс данного множества может вызвать. Так как все процессы чего-то ожидают, то ни один из них не сможет инициировать событие, которое разбудило бы другого члена множества и, следовательно, все процессы будут спать вместе. Обычно событие, которого ждет процесс в тупиковой ситуации - освобождение ресурса.
Условия возникновения тупиков
В1971 г. Коффман, Элфик и Шошани сформулировали следующие четыре условия для возникновения тупиков.
1.Условие взаимоисключения (Mutual exclusion). Каждый ресурс выделен в точности одному процессу или доступен. Процессы требуют предоставления им монопольного управления ресурсами, которые им выделяются.
2.Условие ожидания ресурсов (Hold and wait). Процессы удерживают за собой ресурсы, уже выделенные им, ожидая в то же время выделения дополнительных ресурсов (которые при этом обычно удерживаются другими процессами).
3.Условие неперераспределяемости (No preemtion). Ресурс, данный ранее, не может быть принудительно забран у процесса. Освобождены они могут быть только процессом, который их удерживает.
4.Условие кругового ожидания (Circular wait). Существует кольцевая цепь процессов, в которой каждый процесс удерживает за собой один или более ресурсов, требующихся другим процессам цепи.
Для тупика необходимо выполнение всех четырех условий.
Обычно тупик моделируется прямым графом, наподобие того, что изображен на рисунке:
состоящим из узлов двух видов: прямоугольников процессов и эллипсов ресурсов. Стрелки, направленные от ресурса к процессу, показывают, что ресурс выделен данному процессу.
21.Библиотеки для создания параллельных программ для многопроцессорных и многоядерных систем
Intel Threading Building Blocks (TBB). Основная идеяиспользование стандартного высокоуровневого C++ для быстрой разработки кросс-платформенных, хорошо масштабируемых параллельных приложений.TBB предоставляет механизмы абстрагирования от технологий многопоточного программирования, позволяя сосредоточиться непосредственно на решении прикладной задачи, что достаточно актуально.Пример:
#include ―tbb/blocked_range.h‖ #include ―tbb/parallel_for.h‖ #include ―tbb/task_scheduler_init.h‖ using namespace tbb;
<…>
// Оператор () вып-ся над диапазоном из простр-ва итераций void operator()(const blocked_range<int> &r) const
<…>
// Инициализация библиотеки TBB task_scheduler_init init;
// Запуск параллельного алгоритма for parallel_for(blocked_range<int>(0, SIZE, 500), function());
MPI-обеспечивает взаимодействие параллельных процессов с помощью механизма передачи сообщений. В число функций входят:
-функции инициализации и закрытия MPI процессов;
-ф--ии, реализующие коммуникац. опер-ии типа точка-точка; -функции, реализующие коллективные операции;
-функции для работы с группами процессов и коммуникаторами; -функции для работы со структурами данных; -функции формирования топологии процессов.
POSIX Threads — стандарт POSIX реализации потоков (нитей) выполн-я, определяющий API для созд-я и управления ими. Основные функции стандарта Функции управления потоками:
-pthread_create(): создание потока
-pthread_exit(): завершение потока (должна вызываться функцией потока при завершении)
-pthread_cancel(): отмена потока
-pthread_join(): заблокировать выполнение потока до прекращения другого потока, указанного в вызове функции
-pthread_detach(): освободить ресурсы занимаемые потоком (если поток выполняется, то освобождение ресурсов произойдѐт после его завершения)
-pthread_attr_init(): инициализировать структуру атрибутов потока
-pthread_attr_setdetachstate(): указать системе, что после завершения потока она может автоматически освободить ресурсы, занимаемые потоком
-pthread_attr_destroy(): освободить память от структуры атрибутов потока (уничтожить дескриптор)
22.Оптимизация и профилировка программ
Оптимизация — модификация системы для улучшения еѐ эффективности. Система может быть одиночной компьютерной программой, набором компьютеров или даже целой сетью, такой как Интернет.
Хотя целью оптимизации является получение оптимальной системы, истинно оптимальная система в процессе оптимизации достигается далеко не всегда. Оптимизированная система обычно является оптимальной только для одной задачи или группы пользователей: где-то может быть важнее уменьшение времени, требуемого программе для выполнения работы, даже ценой потребления большего объѐма памяти; в приложениях, где важнее память, могут выбираться более медленные алгоритмы с меньшими запросами к памяти.
Более того, зачастую не существует универсального решения (хорошо работающего во всех случаях), поэтому инженеры используют компромиссные (англ. tradeoff) решения для оптимизации только ключевых параметров. К тому же, усилия, требуемые для достижения полностью оптимальной программы, которую невозможно дальше улучшить, практически всегда превышают выгоду, которая может быть от этого получена, поэтому, как правило, процесс оптимизации завершается до того, как достигается полная оптимальность. К счастью, в большинстве случаев даже при этом достигаются заметные улучшения.
Оптимизация должна проводиться с осторожностью. Тони Хоар впервые произнѐс, а Дональд Кнут впоследствии часто повторял известное высказывание: «Преждевременная оптимизация — это корень всех бед». Очень важно иметь для начала озвученный алгоритм и работающий прототип.
Профилирование — сбор характеристик работы программы, таких как время выполнения отдельных фрагментов (обычно подпрограмм), число верно предсказанных условных переходов, число кэш промахов и т. д. Инструмент, используемый для анализа работы, называют профилировщиком. Обычно выполняется совместно с оптимизацией программы.
Характеристики могут быть аппаратными (время) или вызванные программным обеспечением (функциональный запрос). Инструментальные средства анализа программы чрезвычайно важны для того, чтобы понять поведение программы. Проектировщики ПО нуждаются в таких инструментальных средствах, чтобы оценить, как хорошо выполнена работа. Программисты нуждаются в инструментальных средствах, чтобы проанализировать их программы и идентифицировать критические участки программы.
Это часто используется, чтобы определить, как долго выполняются определенные части программы, как часто они выполняются, или генерировать граф вызовов (Call Graph). Обычно эта информация используется, чтобы идентифицировать те участки программы, которые работают больше всего. Эти трудоѐмкие участки могут быть оптимизированы, чтобы выполняться быстрее.
Также выделяют анализ покрытия (Code Coverage) — процесс выявления неиспользуемых участков кода при помощи, например, многократного запуска программы.
23.Принципы, используемые при профилировке
Основная цель профилировки — исследовать характер поведения приложения во всех его точках. Под "точкой" в зависимости от степени детализации может подразумеваться как отдельная машинная команда, так целая конструкция языка высокого уровня (например: функция, цикл или одна–единственная строка исходного текста).
Большинство современных профилировщиков поддерживают следующий набор базовых операций:
•определение общего времени исполнения каждой точки программы (total [spots] timing);
•определение удельного времени исполнения каждой точки программы ([spots] timing);
•определение причины и/или источника конфликтов и пенальти (penalty information);
•определение количества вызовов той или иной точки программы ([spots] count);
•определение степени покрытия программы ([spots] covering).
Профилировщики исследуют поведение программы в процессе ее выполнения. В частности, собирается такая информация, как частота вызовов функций, продолжительность их работы, число потоков, время ожидания – любая информация, способная помочь при оптимизации производительности. Для сбора информации профилировщики используют такие техники как инструментация кода, аппаратные прерывания, внедрение счетчиков производительности и многие другие. Выходной информацией профилировщика является трасса – список событий, произошедших в приложении (исполненные инструкции, вызовы функций, вызовы операционной системы). После получения трассы профилировщик обрабатывает собранную информацию и строит профиль приложения – статистическую сводку о работе приложения. Затем профиль представляется в графическом виде, удобном для анализа. Разработчик изучает его, определяет проблемные места и ищет способы оптимизации своего приложения.
Ситуация с многопоточными приложениями существенно другая, поскольку в силу вступают новые аспекты производительности, связанные с взаимодействием потоков, затратами на их создание и синхронизацию. Ускорение отдельных участков кода может не дать никакого прироста производительности, если, например, разработчик построил свое приложение таким образом, что основную часть времени потоки ожидают освобождения разделяемого ресурса. Также можно упомянуть такие распространенные в многопоточных приложениях проблемы как неравномерное распределение нагрузки и неэффективное использование примитивов синхронизации. Эти факторы могут привести к катастрофически низкой производительности приложения, вплоть до того, что многопоточная версия будет медленнее последовательной.
Таким образом, для анализа новых аспектов программной оптимизации, присущих именно многопоточным приложениям, необходимы специальные инструменты, ориентированные на обнаружение проблемных ситуаций и последующей помощи программистам в их разрешении. Одним из самых эффективных и популярных представителей инструментов такого класса является ITP.
Проблемы производительности, определяемые при помощи профилирования
Мы уже говорили ранее, что профилирование многопоточных приложений имеет свою специфику. ITP ориентирован на выявление проблемных ситуаций, характерных именно для многопоточных приложений, таких как: неэффективное управлением потоками, ошибки при выборе и использовании примитивов синхронизации, неправильное распределение вычислительной нагрузки и другие недостатки.
Рассмотрим далее наиболее распространенные ошибки и то, как ITP может помочь разработчикам в их обнаружении и исправлении.
Распределение вычислительной нагрузки Весьма распространенной ошибкой является неравномерное распределение нагрузки между потоками. Общее время работы
приложения в значительной степени зависит от времени работы самого медленного из его потоков. Очевидно, приложение будет работать быстрее всего, если нагрузка поделена между потоками поровну – тогда они завершают работу одновременно и за минимальное время.
Типичный пример: стоит задача обработки множества заявок, трудоемкость каждой из которых заранее неизвестна. В такой ситуации не всегда правильно разделять множество заявок поровну между потоками. Дело в том, что один поток может, например, получить все сложные заявки, в результате чего он станет узким местом в приложении.
Проблема распределения вычислительной нагрузки в ряде ситуаций решается достаточно просто. Первый признак ее появления – большая доля последовательных вычислений в приложении, что легко обнаруживается при анализе критического пути. Кроме того, ITP позволяет определить время работы каждого из потоков. При этом, если наблюдается существенное различие между временами работы нескольких потоков (при том, что они выполняют одинаковые действия), это свидетельствует о неравномерном распределении нагрузки.
Для рассмотренного выше примера в качестве решения можно предложить не делать априорного разделения множества заявок между потоками. Вместо этого стоит разрешить потокам выбирать из общей очереди новую заявку каждый раз после того, как была обработана предыдущая. Тогда пока один поток обрабатывает одну сложную заявку, второй поток успеет обработать несколько простых, и в результате можно ожидать более сбалансированного времени работы потоков.
Синхронизация и производительность Аспекты производительности, связанные с синхронизацией между потоками, требуют особого внимания. Неправильно
выбранная стратегия может привести к тому, что параллельная версия приложения будет выполняться даже медленнее, чем последовательная. Поэтому разработчик должен тщательно продумать используемую в его приложении модель синхронизации, и ITP способен оказать ему в этом существенную помощь.
Рассмотрим основные вопросы, связанные с синхронизацией. Выбор примитивов синхронизации
Существует достаточно большое число примитивов синхронизации: мьютексы, семафоры, мониторы, критические секции. Все они имеют одинаковое назначение (обрамление критических областей программы), но эффективность (дополнительные накладные расходы) их работы может существенно различаться. При этом разработчику важно выбрать наиболее подходящий тип примитива синхронизации для каждой конкретной ситуации.
Рассмотрим, например, ситуацию, когда в приложении имеется некоторый целочисленный счетчик, являющийся глобальной переменной. При этом, если мы в приложении используем каждый раз увеличение этого счетчика на единицу, то выбор такого объекта как мьютекс является нерациональным. Гораздо эффективнее использовать атомарную функцию ОС Windows InterlockedIncrement. Кроме того, при разработке модели синхронизации следует делать выбор в пользу примитивов пользовательского уровня (CriticalSection, например), поскольку они работают быстрее, так как не генерируют системных вызовов операционной системы.
ITP способен помочь в выборе наиболее подходящего примитива, позволяя определить время, затраченное на работу с каждым из объектов синхронизации. Таким образом, разработчик может реализовать несколько моделей синхронизации и сравнить их производительность между собой.
Синхронизация между потоками Разработчикам следует придерживаться следующей рекомендации: производить синхронизацию между потоками как можно
реже. То есть необходимо сделать потоки максимально независимыми, чтобы избежать ситуаций, когда они ожидают друг друга. Слишком частое обращение нескольких потоков к разделяемому ресурсу приводит к тому, что большое количество времени потоки простаивают, находясь в состоянии ожидания.
Часто встречающаяся ситуация – это совместное использование одного и того же объекта несколькими потоками. Чтобы избежать блокировки потоков при обращении к объекту, часто используется подход, при котором каждый из потоков получает копию объекта в свое личное пользование. Так, в частности, поступают при работе нескольких пользователей с одной таблицей базы данных.
Вданной ситуации ITP используется следующим образом. С его помощью определяются объекты, обращение к которым происходит наиболее часто. Затем анализируется насколько затратно столь частое обращение к объекту. Если обнаруживается, что производительность существенно страдает, разработчику следует попытаться изменить архитектуру приложения. Хороший пример – замена глобальных переменных локальными.
Непроизводительные издержки при работе с потоками Важный момент при работе с потоками – появление дополнительных накладных расходов. Конечно, эти затраты гораздо
меньше чем при управлении процессами, но все равно они могут оказаться весьма существенными. Основная рекомендация здесь состоит в следующем: потоки за время своей жизни должны совершать работу гораздо большей сложности, чем трудоемкость их собственного создания, уничтожения и управления ими.
Понятно, что если накладные расходы на управление потоками будут преобладать над их полезной деятельностью, то производительность приложения только пострадает.
ITP позволяет определить долю непроизводительных издержек от общего времени работы приложения. Если она оказывается слишком велика, скорее всего, приложение требует перепроектирования. Так, например, если создается система, обслуживающая поступающие в режиме реального времени запросы, то для обработки лучше содержать пул потоков, вместо того, чтобы создавать новый поток для каждого очередного запроса.
24.Примеры средств профилировки от компаний Microsoft и Intel intel VTune
ВVTune Performance Analyzer-поддержка профилирования кода при помощи нескольких способов, включая профилирования на основе временных характеристик, событий и т. д. Выдает итоговый результат, в который входят различные показателивремя выполнения каждой подпрограммы, которые могут быть детализированы на уровне инструкций. Время, затраченное инструкциями, может указывать на всевозможные узкие места в конвейере при выполнении инструкций. Также может быть использован для анализа производительности многопоточных программ.
Visual Studio Team System Profiler — коммерческий профилировщик от корпорации Microsoft, входящий в состав пакета Visual Studio Team System (VSTS) и версии Development Edition среды разработки Visual Studio. Данный инструмент может работать или в режиме семплирования, в котором через определенные промежутки времени производится запись снимков состояния программы, или в режиме измерения, в котором статистика собирается за счет измерений входных и выходных значений функций. Достоинством режима измерения является более тщательный сбор статистики, однако он вынуждает программу работать гораздо медленнее из-за выполнения дополнительного кода при измерениях.
Служит для обнаружения и способствует решению проблем производительности в коде, написанном для платформы .NET или родного скомпилированного кода Visual C++. Профайлер собирает информацию по характеристикам производительности для методов, вызванных на данном этапе работы профайлера, включая количество вызовов функции и весь стек вызовов при вызове функции.
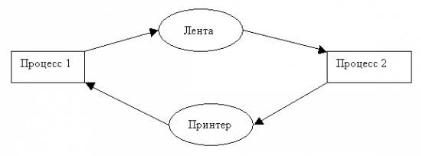
25.Многомашинные вычислительные системы
Многомашинная вычислительная система содержит несколько ЭВМ, каждая из которых имеет свою основную память и работает под управлением своей операционной системы, а также средства обмена информацией между машинами. Реализация
обмена информацией происходит, в конечном счете, путем взаимодействия операционных систем машин между собой. Это ухудшает динамические характеристики процессов межмашинного обмена данными. Многомашинные системы могут быть однородными и неоднородными. Однородные системы содержат однотипные ЭВМ или процессоры. Неоднородные ММС состоят из ЭВМ различного типа.
ММС могут иметь одноуровневую или иерархическую (многоуровневую) структуру. Обычно менее мощная машина (машина-сателлит) берет на себя ввод информации с различных терминалов и ее предварительную обработку, разгружая от этих сравнительно простых процедур основную, более мощную ЭВМ, чем достигается увеличение общей производительности (пропускной способности) комплекса.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Структуры |
параллельных |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
вычислительных систем: |
|
а – |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
иерархическая ярусного типа; 6 – |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
узловая; |
|
в |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
– одноуровневая |
однородная по |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
связям |
|
Очень важен способ организации связей между устройствами (модулями) системы, т.к. непосредственно влияет на быстроту обмена информацией между модулями=>на производительность системы, на размеры аппаратурных затрат на связь.
Способы организации межмодульных связей:
-регулярные связи между модулями;
-многоуровневые связи, соответствующие иерархии интерфейсов ЭВМ;
-многовходовые модули (в частности, модули памяти);
-коммутатор межмодульных связей
-общая шина
Примеры шин:
26.Организация обмена информацией в МВС
Многомашинные вычислительные системы (ММС) появились раньше, чем многопроцессорные. Основные отличия ММС заключаются в организации связей и обмена информацией между ЭВМ комплекса. Многомашинная ВС содержит некоторое число компьютеров, информационно взаимодействующих между собой. Машины могут находиться рядом друг с другом, а могут быть удалены друг от друга на некоторое, иногда значительное расстояние (вычислительные сети). В многомашинных ВС каждый компьютер работает под управлением своей операционной системы (ОС). А поскольку обмен информацией между машинами выполняется под управлением ОС, взаимодействующих друг с другом, динамические характеристики процедур обмена несколько ухудшаются (требуется время на согласование работы самих ОС). Информационное взаимодействие компьютеров в многомашинной ВС может быть организовано на уровне:
процессоров;
оперативной памяти;
каналов связи.
При непосредственном взаимодействии процессоров друг с другом информационная связь реализуется через регистры процессорной памяти и требует наличия в ОС весьма сложных специальных программ.
Взаимодействие на уровне оперативной памяти (ОП) сводится к программной реализации общего поля оперативной памяти, что несколько проще, но также требует существенной модификации ОС. Под общим полем имеется в виду равнодоступность модулей памяти: все модули памяти доступны всем процессорам и каналам связи.
На уровне каналов связи взаимодействие организуется наиболее просто и может быть достигнуто внешними по отношению к ОС программами-драйверами, обеспечивающими доступ от каналов связи одной машины к внешним устройствам других (формируется общее поле внешней памяти и общий доступ к устройствам ввода-вывода).
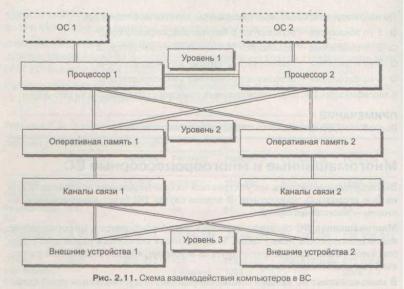
Все вышесказанное иллюстрируется схемой взаимодействия компьютеров в двухмашинной ВС, представленной на рисунке.
Ввиду сложности организации информационного взаимодействия на 1-м и 2-м уровнях в большинстве многомашинных ВС используется 3-й уровень, хотя и динамические характеристики (в первую очередь быстродействие), и показатели надежности таких
систем существенно ниже.