

EKZAMEN
.pdfустройствам на блочном уровне. Ранее на предприятии возникали «острова» высокопроизводительных дисковых массивов SCSI. Каждый такой массив был выделен для конкретного приложения и виден ему как некоторое количество «виртуальных жестких дисков» (LUN'ов).
Сеть хранения данных позволяет объединить эти «острова» средствами высокоскоростной сети. Также без использования технологий SCSI транспорта невозможно организовать отказоустойчивые кластеры, в которых один сервер подключается к двум и более дисковым массивам, находящимся на большом расстоянии друг от друга на случай стихийных бедствий.
Сети хранения помогают повысить эффективность использования ресурсов систем хранения, поскольку дают возможность выделить любой ресурс любому узлу сети.
Не стоит забывать и об устройствах резервного копирования, которые также подключаются к СХД (SAN). В данный момент существуют как промышленные ленточные библиотеки (на несколько тысяч лент) от ведущих брендов, так и low-end решения для малого бизнеса. Сети хранения данных позволяют подключить к одному хосту несколько приводов таких библиотек, обеспечив таким образом хранилище данных для резервного копирования от сотен терабайт до нескольких петабайт.
Преимущества Совместное использование систем хранения как правило упрощает администрирование и добавляет изрядную гибкость,
поскольку кабели и дисковые массивы не нужно физически транспортировать и перекоммутировать от одного сервера к другому.
Другим преимуществом является возможность загружать сервера прямо из сети хранения. При такой конфигурации можно быстро и легко заменить сбойный сервер, переконфигурировав SAN таким образом, что сервер-замена, будет загружаться с LUN'а сбойного сервера. Эта процедура может занять, например, полчаса[2]. Идея относительно новая, но уже используется в новейших датацентрах.
Дополнительным преимуществом является возможность на хосте собрать RAID-зеркало с LUNов, которые презентованы хосту с двух разных дисковых массивов. В таком случае полный отказ одного из массивов не навредит хосту.
Также сети хранения помогают более эффективно восстанавливать работоспособность после сбоя. В SAN может входить удаленный участок со вторичным устройством хранения. В таком случае можно использовать репликацию — реализованную на уровне контроллеров массивов, либо при помощи специальных аппаратных устройств. Поскольку каналы WAN на основе протокола IP встречаются часто, были разработаны протоколы Fibre Channel over IP (FCIP) и iSCSI с целью расширить единую SAN средствами сетей на основе протокола IP. Спрос на такие решения значительно возрос после событий 11 сентября 2001 года в США.
Сравнение технологий обмена данными
Порой сравнивают SAN и NAS, говоря на самом деле о разнице между сетевым диском и сетевой ФС — которая состоит в том, кто обслуживает файловую систему, хранящую данные.
В случае сетевого диска (также «блочного устройства», англ. block device):
• обмен данными с ним по сети осуществляется блоками подобно тому, как и с локальным SCSIили SATA-диском;
• файловая система, если нужна, создаѐтся и управляется клиентом и как правило — используется им одним.
В случае сетевой файловой системы («ресурс с совместным/разделяемым доступом» — не хранит, а только передаѐт данные):
•обмен данными по сети происходит с применением более высокоуровневых понятий «файл» и «каталог», соответствующих объектам подлежащей «настоящей» ФС на физических дисках (либо логических поверх них в случае применения RAID, LVM);
•эта файловая система создаѐтся и обслуживается в рамках удалѐнной системы, при этом может одновременно использоваться на чтение и запись множеством клиентов.
Топология сети
Однокоммутаторная структура (single-switch fabric) состоит из одного коммутатора Fibre Channel, сервера и системы хранения данных. Обычно эта топология является базовой для всех стандартных решений — другие топологии создаются объединением однокоммутаторных ячеек.
Дерево или Каскадная структура
Каскадная структура (англ. cascaded fabric) — набор ячеек, коммутаторы которых соединены в дерево с помощью межкоммутаторных соединений (англ. Inter-Switch link, ISL). Во время инициализации сети коммутаторы выбирают «верхушку дерева» (англ. principal switch, главный коммутатор) и присваивают ISL’ам статус «upstream» (вверх) или «downstream» (вниз) в зависимости от того, ведет этот линк в сторону главного свитча или на периферию.
Решѐтка
Решетка
Решетка (англ. meshed fabric) — набор ячеек, коммутатор каждой из которых соединен со всеми другими. При отказе одного (а в ряде сочетаний — и более) ISL соединения связность сети не нарушается. Недостаток — большая избыточность соединений. Кольцо
Кольцо
Кольцо (англ. ring fabric) — практически повторяет схему топологии решѐтка. Среди преимуществ — использование меньшего количества ISL соединений.
Производительность
Появление новых высокотехнологичных материалов способствует росту производительности сетей на базе Fibre Channel и Ethernet. Уже существуют коммутаторы, поддерживающие скорость передачи 10Gbit/s. Для этого используется новый тип трансивера - XFP, а также оптоволокно стандарта ОМ3. Росту скорости передачи способствует и то, что коммутаторы могут собирать на Inter Switch Link'ах транкгруппы из нескольких портов. Коммутаторы "SilkWorm" от Brocade могут собирать транк из восьми линков. Транков может быть несколько, если возникает такая необходимость.
NAS
В отличие от SAN, NAS (network attached storage) — не сеть, а сетевое устройство хранения, точнее, выделенный файловый сервер с подсоединенной к нему дисковой подсистемой. Иногда в конфигурацию NAS может входить оптическая или ленточная библиотека. NAS-устройство (NAS appliance) напрямую подключается в сеть и предоставляет хостам доступ к файлам на своей интегрированной подсистеме внешней памяти. Появление выделенных файловых серверов связано с разработкой в начале 90-х годов компанией Sun Microsystems сетевой файловой системы NFS, которая позволяла клиентским компьютерам в локальной сети использовать файлы на удаленном сервере. Затем у Microsoft появилась аналогичная система для среды Windows — Common Internet File System. Конфигурации NAS поддерживают обе эти системы, а также другие протоколы на базе IP, обеспечивая разделение файлов клиентскими приложениями.
AS-устройство напоминает конфигурацию DAS, но принципиально отличается от нее тем, что обеспечивает доступ на уровне файлов, а не блоков данных, и позволяет всем приложениям в сети совместно использовать файлы на своих дисках. NAS специфицирует файл в файловой системе, сдвиг в этом файле (который представляется как последовательность байт) и число байт, которое необходимо прочитать или записать. Запрос к NAS-устройству не определяет том или сектор на диске, где находится файл. Задача операционной системы NAS-устройства транслировать обращение к конкретному файлу в запрос на уровне блоков данных. Файловый доступ и возможность разделения информации удобны для приложений, которые должны обслуживать множество пользователей одновременно, но не требуют загрузки очень больших объемов данных по каждому запросу. Поэтому обычной практикой становится использование NAS для Internet-приложений, Web-cлужб или CAПР, в которых над одним проектом работают сотни специалистов.
Вариант NAS прост в установке и управлении. В отличие от сети хранения, установка NAS-устройства не требует специального планирования и затрат на дополнительное управляющее ПО — достаточно просто подключить файловый сервер в локальную сеть. NAS освобождает серверы в сети от задач управления хранением, но не разгружает сетевой трафик, поскольку обмен данными между серверами общего назначения и NAS идет по той же локальной сети. На NAS-устройстве может быть сконфигурирована одна или несколько файловых систем, каждой из которых отводится определенный набор томов на диске. Всем пользователям одной и той же файловой системы по требованию выделяется некоторое дисковое пространство. Таким образом, NAS обеспечивает более эффективные по сравнению с DAS организацию и использование ресурсов памяти, поскольку подключенная напрямую подсистема хранения обслуживает только один вычислительный ресурс, и может случиться так, что у одного сервера в локальной сети будет слишком много внешней памяти, в то время как другой испытывает нехватку пространства на дисках. Но из нескольких NAS-устройств нельзя создать единый пул ресурсов хранения и потому увеличение числа NAS-узлов в сети усложнит задачу управления.
51.Области применения SAN и NAS
Основные области применения SAN — организация высокоскоростного резервного копирования без участия сервера/ЛВС, консолидация разделяемых ресурсов массовой памяти с высокой степенью масштабирования, создание отказоустойчивых систем массовой памяти с высокой степенью доступности.
Поскольку NAS-серверы оптимизированы для работы с файлами, основными приложениями для таких устройств являются Web, CAD/CAM, системы управления документами, поддержание файловых архивов. Также NAS-устройства оптимально решают проблему разделяемого доступа к файлам клиентов, использующих различные ОС.
52.Интерфейсы подсистем хранения (SCSI, iSCSI, Fibre Channel)
SCSI Small Computer Systems Interface (системный интерфейс для малых компьютеров) – интерфейс, разработанный для объединения на одной шине различных по своему назначению устройств, таких как жѐсткие диски, накопители на магнитооптических дисках, стримеры, сканеры и т.д. Интерфейс предназначен для соединения устройств различных классов: памяти прямого и последовательного доступа, CD-ROM, оптических дисков однократной и многократной записи, устройств автоматической смены носителей информации, принтеров, сканеров, коммуникационных устройств и процессоров. Применяется в различных архитектурах компьютерных систем, а не только в PC. Стандарт определяет не только физический интерфейс, но и систему команд, управляющих устройствами SCSI. За время своего существования стандарт активно развивался.
Стандарты, описывающие SCSI
Стандарт SCSI-1 был стандартизован ANSI ещѐ в 1986 г. Стандарт SCSI-2.
Стандарт SCSI-3 описывается документами: SIP (SCSI Interlock Protocol), SPI (SCSI Parallel Interface).
Стандарт SPI, 1995 г. Определяет Fast SCSI (Fast Wide SCSI). Стандарт SPI-2, 1999 г. Определяет Ultra2 SCSI (Wide Ultra2 SCSI). Стандарт SPI-3, 2000 г. Определяет Wide Ultra3 SCSI (Ultra 160).
Стандарт SPI-4, 2001 г. Определяет Ultra320 SCSI.
Стандарт EPI (Enhanced Parallel Interface). Описывает построение SCSI-систем.
Протокол команд SCSI
Втерминологии SCSI взаимодействие идѐт между инициатором и целевым устройством. Инициатор посылает команду целевому устройству, которое затем отправляет ответ инициатору.
Команды SCSI посылаются в виде блоков описания команды (англ. Command Descriptor Block, CDB). Длина каждого блока может составлять 6, 10, 12, 16 или 32 байта. В последних версиях SCSI блок может иметь переменную длину. Блок состоит из однобайтового кода команды и параметров команды.
После получения команды целевое устройство возвращает значение 00h в случае успешного получения, 02h в случае ошибки или 08h в случае, если устройство занято. В случае, если устройство вернуло ошибку, инициатор обычно посылает команду запроса состояния. Устройство возвращает Key Code Qualifier (KCQ).
Все команды SCSI делятся на четыре категории: N (non-data), W (запись данных от инициатора целевым устройством), R (чтение данных) и B (двусторонний обмен данными). Всего существует порядка 60 различных команд SCSI, из которых наиболее часто используются:
•Test unit ready — проверка готовности устройства, в том числе наличия диска в дисководе.
•Inquiry — запрос основных характеристик устройства.
•Send diagnostic — указание устройству провести самодиагностику и вернуть результат.
•Request sense — возвращает код ошибки предыдущей команды.
•Read capacity — возвращает ѐмкость устройства.
•Format Unit
•Read (4 варианта) — чтение.
•Write (4 варианта) — запись.
•Write and verify — запись и проверка.
•Mode select — установка параметров устройства.
•Mode sense — возвращает текущие параметры устройства.
Каждое устройство на SCSI-шине имеет как минимум один номер логического устройства (LUN — англ. Logical Unit Number). В некоторых более сложных случаях одно физическое устройство может представляться набором LUN.
Для возможности работы нескольких независимых целевых устройств SCSI, в UNIX-подобных операционных системах применяется адресация из произвольно назначаемого драйвером идентификатора целевого устройства (SCSI target id) и номера LUN, сконфигурированного на нѐм.
Для устройств типа приводов CD/DVD/Blu-Ray, в том числе их разновидностей с возможностью записи, разработан MMC — Multimedia Command Set. Некоторые приводы, например, производства Asus и Pioneer, используют конкурирующий стандарт Mt. Fuji, отличающийся от MMC в некоторых нюансах.
iSCSI (англ. Internet Small Computer System Interface) — протокол, который базируется на TCP/IP и разработан для установления взаимодействия и управления системами хранения данных, серверами и клиентами.
iSCSI описывает:
•Транспортный протокол для SCSI, который работает поверх TCP.
•Механизм инкапсуляции SCSI команд в IP сети.
•Протокол для нового поколения систем хранения данных, которые будут использовать «родной» TCP/IP.
Протокол iSCSI является стандартизованным по RFC 3720. Существует много коммерческих и некоммерческих реализаций этого протокола.
Системы на основе iSCSI могут быть построены на любой достаточно быстрой физической основе, поддерживающей протокол IP, например Gigabit Ethernet или 10G Ethernet. Использование стандартного протокола позволяет применять стандартные средства контроля и управления потоком, а также существенно уменьшает стоимость оборудования по сравнению с сетями
Fibre Channel.
Необходимо знать, что протокол iSCSI определяет, как минимум, транспортный протокол для SCSI, который работает поверх TCP, и технологию инкапсуляции SCSI-команд в сеть на базе IP. Проще говоря, iSCSI – это протокол, позволяющий получить блочный доступ к данным с помощью команд SCSI, пересылаемых через сеть со стеком TCP/IP. iSCSI появился как замена FibreChannel и в современных СХД имеет перед ним несколько преимуществ – способность объединять устройства на огромных расстояниях (используя существующие сети IP), возможность обеспечивать заданный уровень QoS (Quality of Service, качество обслуживания), более низкую стоимость connectivity. Однако основная проблема использования iSCSI как замены FibreChannel – большое время задержек, возникающих в сети из-за особенностей реализации стека TCP/IP – это время может приближаться к 80 микросекундам, что сводит на нет одно из важных преимуществ использования СХД – скорость доступа к информации и низкую латентность. Это серьѐзный минус Примеры реализаций Инициаторы (клиенты)
•Для GNU/Linux (есть пакет в DebianGNU/Linux) — Open-iSCSI
Присутствует в стандартной сборке Linux с версии 2.6.16.
•Microsoft iSCSI Software Initiator Version 2.08 (для Windows 2000/XP/2003 Server)
•Реализация target для Linux (позволяет экспортировать устройство или файл как iSCSItarget)
•Бесплатная программная реализация target для WindowsServerR2
Также существует монолитный проект на основе BSD — OpenNAS,
На основе FreeBSD 7.2 сделан FreeNAS (может выступать как в качестве target, так и initiator).
Аналог FreeNAS, но на основе Linux — проект Openfiler (также может выступать как в качестве target, так и initiator) Преимущества
•Консолидация систем хранения данных
•Резервирование данных
•Кластеризация серверов
•Репликация
•Восстановление в аварийных ситуациях
•Географическое распределение SAN
•QoS
•Безопасность
FibreChannel (FC) (англ. fibrechannel — волоконный канал) — семейство протоколов для высокоскоростной передачи данных. Стандартизацией протоколов занимается Технический комитет T11, входящий в состав Международного комитета по стандартам в сфере ИТ (InterNationalCommitteeforInformationTechnologyStandards — INCITS), аккредитованного Американским национальным институтом стандартов (ANSI). Изначальное применение FC в области суперкомпьютеров впоследствии практически полностью перешло в сферу сетей хранения данных, где FC используется как стандартный способ подключения к системам хранения данных уровня предприятия.
FibreChannelProtocol (FCP) — транспортный протокол (как TCP в IP-сетях), инкапсулирующий протокол SCSI по сетям FibreChannel. Является основой построения сетей хранения данных.
Топологии FibreChannel
Топологии FC определяют взаимное подключение устройств, а именно передатчиков (трансмиттеров) и приѐмников (ресиверов) устройств. Существует три типа топологии FC:
Точка-Точка (point-to-point)
Устройства соединены напрямую — трансмиттер одного устройства соединѐн с ресивером второго и наоборот. Все отправленные одним устройством кадры предназначены для второго устройства.
Управляемая петля (arbitratedloop)
Устройства объединены в петлю — трансмиттер каждого устройства соединѐн с ресивером следующего. Перед тем, как петля сможет служить для передачи данных, устройства договариваются об адресах. Для передачи данных по петле устройство должно завладеть «эстафетой» (token). Добавление устройства в петлю приводит к приостановке передачи данных и пересобиранию петли. Для построения управляемой петли используют концентраторы, которые способны размыкать или замыкать петлю при добавлении нового устройства или выходе устройства из петли.
Коммутируемая связная архитектура (switchedfabric)
Основана на применении коммутаторов. Позволяет подключать большее количество устройств, чем в управляемой петле, при этом добавление новых устройств не влияет на передачу данных между уже подключѐнными устройствами. Так как на основе коммутаторов можно строить сложные сети, на коммутаторах поддерживаются распределѐнные службы управления сетью (fabric services), отвечающие за маршруты передачи данных, регистрацию в сети и присвоение сетевых адресов и проч. Fibre Channel изначально разрабатывался как высокоскоростная сеть, пригодная для работы в реальном времени. В транспорте Fibre Channel заложены механизмы регулирования потока (flow control), синхронизации портов по времени и возможность повтора сбойной информации без обращения к протоколу верхнего уровня. Упрощенно, без подробностей зонирования и виртуализации, в Fibre Channel при подключении порта обязательным является выполнение login, так что коммутатор о всех портах сети всегда знает какой порт где находится и что может. Когда в коммутатор Fibre Channel приходит кадр данных, то коммутатор уже знает, где находится адресат и куда этот кадр маршрутизировать (в отличие от Ethernet, в котором коммутатор после прихода кадра сначала ищет, где находится адресат и только после его ответа посылает ему этот кадр, и, если истекло время старения, коммутатор Ethernet вновь будет искать маршрут для другого кадра данных от того же источника к тому же адресату, хотя оба порта были online). Очевидно, что подход Fibre Channel требует больше ресурсов, поэтому коммутаторы по этой технологии значительно дороже, чем для Ethernet. Иногда под топологией FC ошибочно подразумевают топологию сети хранения данных, то есть, взаимное подключение оборудования инфраструктуры и оконечных устройств.
Уровни
FibreChannel состоит из пяти уровней:
•FC-0 Физический Описывает среду передачи, трансиверы, коннекторы и типы используемых кабелей. Включает определение электрических и оптических характеристик, скоростей передачи данных и других физических компонентов. Поддерживается как оптическая, так и электрическая среда (витая пара, коаксиальный или твинаксиальный кабели, а также многомодовое или одномодовое волокно), со скоростью передачи данных от 133 мегабит/с до 10 гигабит/с на расстояния до 50 километров.
•FC-1 Кодирование Описывает процесс 8b/10b Кодирования (каждые 8 бит данных кодируются в 10-битовый символ (TransmissionCharacter)), специальные символы и контроль ошибок. Для 10GFC используется кодирование 64b/66b, вследствие этого 10GFC несовместим с 1/2/4/8GFC.
•FC-2 Кадрирование и сигнализация Описывает сигнальные протоколы. На этом уровне происходит определение слов, разбиение потока данных на кадры. Определяет правила передачи данных между двумя портами, классы служб).
•FC-3 Общих для узла служб Определяет базовые и расширенные службы для транспортного уровня, а также такие особенности, как: расщепление потока данных (striping) (Возможность передачи потока данных через несколько соединений (маршрутов), отображение множества портов на одно устройство.
•FC-4 Отображения протоколов Предоставляет возможность инкапсуляции других протоколов (SCSI, ATM, IP, HIPPI , AV, VI, IBMSBCCS и многих других.)
53.Архитектура и адресация в iSCSI
iSCSI - клиент-серверная архитектура. Сервер (принимающий запросы) называется iSCSItarget, клиент - iSCSIinitiator.
Сервер (target) может быть реализован как программно, так и аппаратно. Программная реализация принимает запросы по сети, обрабатывает их, читает (записывает) нужные данные на носитель, отдаѐт информацию (результат) обратно по сети. Так как эти операции при высокой интенсивности запросов занимают существенное время процессора, были созданы аппаратные iSCSIHBA (адаптеры), которые совмещают в себе сетевую карту Ethernet и SCSI-контроллер.
iSCSI работает на блочном уровне. Объектом, к которому предоставляется доступ, является область данных, интерпретируемая инициатором как блочное устройство (диск). Доступ является монопольным (за исключением специально рассчитанных на это файловых систем и файловых систем в режиме "только для чтения"). Обязанность создавать и обслуживать файловую систему возлагается на инициатора; сервер (цель, target) лишь обслуживает низкоуровневые запросы, аналогичные запросам, которые обслуживает драйвер диска при работе с локальными дисками.
Для адресации по сети и клиент и сервер имеют свои адреса, которые должны быть уникальными.
Маленькое замечание по поводу хостов – они могут использовать как обычные сетевые карты (тогда обработка стека iSCSI и инкапсуляция команд будет осуществляться программными средствами), так и специализированные карты с поддержкой технологий аналогичных TOE (TCP/IP Offload Engines). Такая технология обеспечивает аппаратную обработку соответствующей части стека протокола iSCSI. Программный метод дешевле, однако больше загружает центральный процессор сервера и в теории может приводить к бОльшим задержкам, чем аппаратный обработчик. При современной скорости сетей Ethernet в 1 Гбит/с можно предположить, что iSCSI будет работать ровно в два раза медленнее FibreChannel со скоростью 2 Гбит, однако в реальном применении разница будет ещѐ заметнее.
Для обнаружения списка доступных устройств на iSCSI цели (сервере) используется технология обнаружения (discovery, autodiscovery). Это сервис, слушающий на порте tcp (обычно, 3260) запросы клиентов и отдающий им список доступных целей. Такой сервис называют порталом (англ. portal).
Помимо порталов, для поиска доступных целей может так же использоваться iSNS (Internetstoragenameservice). Дополнительно, iSCSI поддерживает Multipathing (Технология резервирования каналов данных обеспечивает наличие более одного канала между хостом и дисковой системой. Компоненты избыточных каналов включают: шины, контроллеры, коммутаторы и мосты).
Система адресации iSCSI – штука не столько мудреная, сколько непривычная. Естественно, как и полагается узлам IP-сети, каждый хост является логическим объектом, однозначно определяемым уникальным именем – iSCSIName, которое включает в себя обозначение типа, название присвоившей имя компании и уникального идентификатора. Также любой объект имеет адрес (или адреса, что тоже допускается), который может изменяться при перемещении машины. Обратите внимание, что имя при этом сохраняется, что уже удобно.
Существуют два типа адресации – EUI-based и IQN, просто приведу примеры записи адресов двумя различными методами адресации (они не эквивалентны друг другу – это лишь пример):
•eui.5a1b375297690100;
•iqn.1979-07.ivs.home:winxp.
54.Принципы построения дисковой подсистемы высокоскоростных отказоустойчивых кластеров, массивы RAID
Основная концепция дисковой подсистемы кластера следующая. Существует отдельный дисковый сервер, который имеет массив жестких дисков. Он по сети экспортирует так называемые виртуальные диски, для каждого узла кластера – свой отдельный. Каждый узел подсоединяет по сети свой виртуальный жесткий диск, и работает с ним так, словно бы он являлся его собственным физическим диском. Все операции чтения/записи при этом транслируются по сетевой среде на дисковый сервер. Такой подход позволяет использовать бездисковые вычислительные узлы кластера, к тому же их быстродействие будет не хуже, а во многих случаях даже лучше, чем у аналогичных узлов с локальными жесткими дисками.
При этом для дисковой подсистемы кластера более важным будет максимальное быстродействие при работе с одним клиентом, чем ее общая производительность при одновременном обслуживании многих узлов, что более критично для централизованного хранилища данных кластера, поскольку способ использования виртуальной памяти и временной файловой системы не предусматривает массовые операции чтения/записи.
Массивы RAID
RAID (англ. redundant array of independent disks — избыточный массив независимых жѐстких дисков) — массив из нескольких дисков, управляемых контроллером, взаимосвязанных скоростными каналами и воспринимаемых внешней системой как единое целое. В зависимости от типа используемого массива может обеспечивать различные степени отказоустойчивости и быстродействия. Служит для повышения надѐжности хранения данных и/или для повышения скорости чтения/записи информации (RAID 0).
Аббревиатура RAID изначально расшифровывалась как «redundant array of inexpensive disks» («избыточный (резервный) массив недорогих дисков», так как они были гораздо дешевле RAM). Именно так был представлен RAID его создателями Петтерсоном (David A. Patterson), Гибсоном (Garth A. Gibson) и Катцом (Randy H. Katz) в 1987 году. Со временем RAID стали расшифровывать как «redundant array of independent disks» («избыточный (резервный) массив независимых дисков»), потому что для массивов приходилось использовать и дорогое оборудование (под недорогими дисками подразумевались диски для ПЭВМ).
Калифорнийский университет в Беркли представил следующие уровни спецификации RAID, которые были приняты как стандарт де-факто:
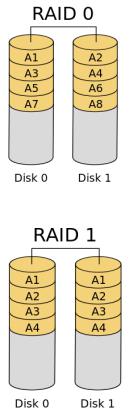
RAID 0 представлен как дисковый массив повышенной производительности, без отказоустойчивости. RAID 1 определѐн как зеркальный дисковый массив.
RAID 2 зарезервирован для массивов, которые применяют код Хемминга.
RAID 3 и 4 используют массив дисков с чередованием и выделенным диском чѐтности. RAID 5 используют массив дисков с чередованием и "невыделенным диском чѐтности".
RAID 6 используют массив дисков с чередованием и двумя независимыми "чѐтностями" блоков. RAID 10 — RAID 0, построенный из RAID 1 массивов
RAID 50 — RAID 0, построенный из RAID 5 RAID 60 — RAID 0, построенный из RAID 6 Базовые уровни RAID
RAID 0
RAID 0 (striping — «чередование») — дисковый массив из двух или более жѐстких дисков без резервирования (т.е., по сути
RAID-массивом не является). Информация разбивается на блоки данных ( ) фиксированной длины и записывается на оба/несколько дисков одновременно.
(+): За счѐт этого существенно повышается производительность (от количества дисков зависит кратность увеличения производительности).
(-): Надѐжность RAID 0 заведомо ниже надѐжности любого из дисков в отдельности и падает с увеличением количества входящих в RAID 0 дисков, т. к. отказ любого из дисков приводит к неработоспособности всего массива.
Два диска — минимальное количество для построения «зеркального» массива
RAID 1 (mirroring — «зеркалирование») — массив из двух дисков, являющихся полными копиями друг друга. Не следует путать с массивами RAID 1+0, RAID 0+1 и RAID 10, в которых используется более двух дисков и более сложные механизмы зеркалирования.
(+): Обеспечивает приемлемую скорость записи и выигрыш по скорости чтения при распараллеливании запросов.[1] (+): Имеет высокую надѐжность — работает до тех пор, пока функционирует хотя бы один диск в
массиве. Вероятность выхода из строя сразу двух дисков равна произведению вероятностей отказа каждого диска, т.е. значительно ниже вероятности выхода из строя отдельного диска. На практике при выходе из строя одного из дисков следует срочно принимать меры — вновь восстанавливать
избыточность. Для этого с любым уровнем RAID (кроме нулевого) рекомендуют использовать диски горячего резерва.
(-): Недостаток RAID 1 в том, что по цене двух жестких дисков пользователь фактически получает лишь один.
RAID 2
Массивы такого типа основаны на использовании кода Хемминга. Диски делятся на две группы:
для данных и для кодов коррекции ошибок, |
причѐм если данные хранятся на дисках, то для |
хранения кодов коррекции необходимо |
дисков. Данные распределяются по дискам, |
предназначенным для хранения информации, так же, как и в RAID 0, т.е. они разбиваются на небольшие блоки по числу дисков. Оставшиеся диски хранят коды коррекции ошибок, по которым в случае выхода какого-либо жѐсткого диска из строя возможно восстановление информации. Метод Хемминга давно применяется в памяти типа ECC и позволяет на лету исправлять однократные и обнаруживать двукратные ошибки.
Достоинством массива RAID 2 является повышение скорости дисковых операций по сравнению с производительностью одного диска.
Недостатком массива RAID 2 является то, что минимальное количество дисков, при котором имеет смысл его использовать,— 7. При этом нужна структура из почти двойного количества дисков (для n=3 данные будут храниться на 4 дисках), поэтому такой вид массива не получил распространения. Если же дисков около 30-60, то перерасход получается 11-19%.
RAID 3
В массиве RAID 3 из дисков данные разбиваются на куски размером меньше сектора (разбиваются на байты) или блоки и распределяются по дискам. Ещѐ один диск используется для хранения блоков чѐтности. В RAID 2 для этой цели применялся диск, но большая часть информации на контрольных дисках использовалась для коррекции ошибок на лету, в то время как большинство пользователей удовлетворяет простое восстановление информации в случае поломки диска, для чего хватает информации, умещающейся на одном выделенном жѐстком диске.
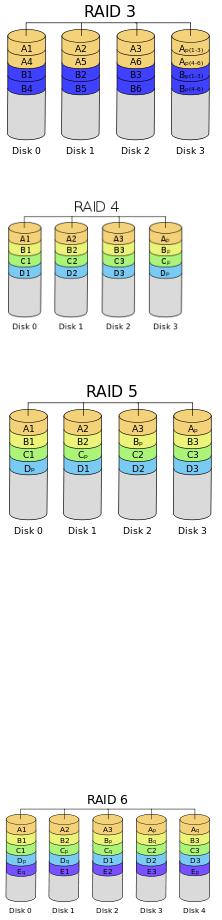
Отличия RAID 3 от RAID 2: невозможность коррекции ошибок на лету и меньшая избыточность.
Достоинства:
•высокая скорость чтения и записи данных;
•минимальное количество дисков для создания массива равно
трѐм. Недостатки:
•массив этого типа хорош только для однозадачной работы с большими файлами, так как время доступа к отдельному сектору, разбитому по дискам, равно максимальному из интервалов доступа к секторам каждого из дисков. Для блоков малого размера время доступа намного больше времени чтения.
•большая нагрузка на контрольный диск, и, как следствие, его надѐжность сильно падает по сравнению с дисками, хранящими данные.
RAID 4 похож на RAID 3, но отличается от него тем, что данные разбиваются на блоки, а не на байты. Таким образом, удалось отчасти «победить» проблему низкой скорости передачи данных небольшого объѐма. Запись же производится медленно из-за того, что чѐтность для блока генерируется при записи и записывается на единственный диск. Из систем хранения широкого распространения RAID-4 применяется на устройствах хранения компании NetApp (NetApp FAS), где его недостатки успешно устранены за счет работы дисков в специальном режиме групповой записи, определяемом используемой на устройствах внутренней файловой системой WAFL.
RAID 5
Основным недостатком уровней RAID от 2-го до 4-го является невозможность производить параллельные операции записи, так как для хранения информации о чѐтности используется отдельный контрольный диск. RAID 5 не имеет этого недостатка. Блоки данных и контрольные суммы циклически записываются на все
диски массива, нет асимметричности конфигурации дисков. Под контрольными суммами подразумевается результат операции XOR (исключающее или). Xor обладает особенностью, которая даѐт возможность заменить любой операнд результатом, и, применив алгоритм xor, получить в результате недостающий операнд.
Например: a xor b = c (где a, b, c — три диска рейд-массива), в случае если a откажет, мы можем получить его, поставив на его место c и проведя xor между c и b: c xor b = a. Это применимо вне зависимости от количества операндов: a xor b xor c xor d = e. Если отказывает c тогда e встаѐт на его место и проведя xor в результате получаем c: a xor b xor e xor d = c. Этот метод по сути обеспечивает отказоустойчивость 5 версии. Для хранения результата xor требуется всего 1 диск, размер которого равен размеру любого другого диска в raid.
(+): RAID5 получил широкое распространение, в первую очередь,
благодаря своей экономичности. Объѐм дискового массива RAID5 рассчитывается по формуле (n-1)*hddsize, где n — число дисков в массиве, а hddsize — размер наименьшего диска. Например, для массива из 4-х дисков по 80 гигабайт общий объѐм будет (4 — 1) * 80 = 240 гигабайт. На
запись информации на том RAID 5 тратятся дополнительные ресурсы и падает производительность, так как требуются дополнительные вычисления и операции записи, зато при чтении (по сравнению с отдельным винчестером) имеется выигрыш, потому что потоки данных с нескольких дисков массива могут обрабатываться параллельно.
(-): Производительность RAID 5 заметно ниже, в особенности на операциях типа Random Write (записи в произвольном порядке), при которых производительность падает на 10-25% от производительности RAID 0 (или RAID 10), так как требует большего количества операций с дисками (каждая операция записи сервера заменяется на контроллере RAID на три - одну операцию чтения и две операции записи). Недостатки RAID 5 проявляются при выходе из строя одного из дисков — весь том переходит в критический режим (degrade), все операции записи и чтения сопровождаются дополнительными манипуляциями, резко падает производительность. При этом уровень надежности снижается до надежности RAID-0 с соответствующим количеством дисков (то есть в n раз ниже надежности одиночного диска). Если до полного восстановления массива произойдет выход из строя, или возникнет невосстановимая ошибка чтения хотя бы на еще одном диске, то массив разрушается, и данные на нем восстановлению обычными методами не подлежат. Следует также принять во внимание, что процесс RAID Reconstruction (восстановления данных RAID за счет избыточности) после выхода из строя диска вызывает интенсивную нагрузку чтения с дисков на протяжении многих часов непрерывно, что может спровоцировать выход какого-либо из оставшихся дисков из строя в этот наименее защищенный период работы RAID, а также выявить ранее необнаруженные сбои чтения в массивах cold data (данных, к которым не обращаются при обычной работе массива, архивные и малоактивные данные), что повышает риск сбоя при восстановлении данных.
Минимальное количество используемых дисков равно трѐм.
RAID 6 — похож на RAID 5, но имеет более высокую степень надѐжности — под контрольные суммы выделяется ѐмкость 2-х дисков, рассчитываются 2 суммы по разным алгоритмам. Требует более мощный RAID-контроллер. Обеспечивает работоспособность после одновременного выхода из строя двух дисков — защита от кратного отказа. Для организации массива требуется минимум 4 диска[2]. Обычно использование RAID-6 вызывает примерно 10-15% падение производительности дисковой группы, по сравнению с аналогичными показателями RAID-5, что вызвано большим объѐмом обработки для контроллера (необходимость рассчитывать вторую контрольную сумму, а также прочитывать и перезаписывать больше дисковых блоков при записи каждого блока).
Комбинированные уровни
Помимо базовых уровней RAID 0 - RAID 6, описанных в стандарте «Common RAID Disk Drive Format (DEF) standard»,
существуют комбинированные уровни с названиями вида «RAID α+β» или «RAID αβ», что обычно означает «RAID β, составленный из нескольких RAID α» (иногда производители интерпретируют это по-своему).
Например:
•RAID 10 (или 1+0) — это RAID 0, составленный из нескольких (или хотя бы двух) RAID 1 (зеркалированных пар).
•RAID 51 — RAID 1, зеркалирующий два RAID 5 .
Комбинированные уровни наследуют как преимущества, так и недостатки своих «родителей»: появление чередования в уровне RAID 5+0 нисколько не добавляет ему надѐжности, но зато положительно отражается на производительности. Уровень RAID 1+5, наверное, очень надѐжный, но не самый быстрый и, к тому же, крайне неэкономичный: полезная ѐмкость тома меньше половины суммарной ѐмкости дисков…
RAID 0+1
Под RAID 0+1 может подразумеваться два варианта:
•два RAID 0 объединяются в RAID 1;
•в массив объединяются три и более диска, и каждый блок данных записывается на два диска данного массива[3]; таким
образом, при таком подходе, как и в «чистом» RAID 1, полезный объѐм массива составляет половину от суммарного объѐма всех дисков (если это диски одинаковой ѐмкости).
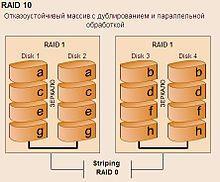
RAID 10
RAID 10 — зеркалированный массив, данные в котором записываются
последовательно на несколько дисков, как в RAID 0. Эта архитектура
представляет собой массив типа RAID 0, сегментами которого вместо
отдельных дисков являются массивы RAID 1. Соответственно, массив этого уровня должен содержать как минимум 4 диска (и всегда чѐтное количество). RAID 10 объединяет в себе высокую отказоустойчивость и производительность.
Утверждение, что RAID 10 является самым надѐжным вариантом для хранения данных, ошибочно, т.к., несмотря на то, что для данного уровня RAID возможно сохранение целостности данных при выходе из строя
половины дисков, необратимое разрушение массива происходит при выходе из строя уже двух дисков, если они находятся в одной зеркальной паре.
55. Особенности физической реализации серверов кластерных систем, blade –серверы
К общим требованиям, предъявляемым к кластерным системам, относятся:
1.Высокая готовность
2.Высокое быстродействие
3.Масштабирование
4.Общий доступ к ресурсам
5.Удобство обслуживания
Естественно, что при частных реализациях одни из требований ставятся во главу угла, а другие отходят на второй план. Так, например, при реализации кластера, для которого самым важным является быстродействие, для экономии ресурсов меньше внимания придают высокой готовности.
Вобщем случае кластер функционирует как мультипроцессорная система, поэтому, важно понимать классификацию таких систем в рамках распределения программно-аппаратных ресурсов.
Проблематика High Performance кластеров. Почти в любой ориентированной на параллельное вычисление задаче невозможно избегнуть необходимости передавать данные от одной подзадачи другой.
Таким образом, быстродействие High Performance кластерной системы определяется быстродействием узлов и связей между ними. Причем влияние скоростных параметров этих связей на общую производительность системы зависит от характера выполняемой задачи. Если задача требует частого обмена данными с подзадачами, тогда быстродействию коммуникационного интерфейса следует уделять максимум внимания. Естественно, чем меньше взаимодействуют части параллельной задачи между собою, тем меньше времени потребуется для ее выполнения. Что диктует определенные требования также и на программирование параллельных задач.
Проблематика High Availability кластерных систем. Сегодня в мире распространены несколько типов систем высокой готовности. Среди них кластерная система является воплощением технологий, которые обеспечивают высокий уровень отказоустойчивости при самой низкой стоимости. Отказоустойчивость кластера обеспечивается дублированием всех жизненно важных компонент. Максимально отказоустойчивая система должна не иметь ни единой точки, то есть активного элемента, отказ которого может привести к потере функциональности системы. При построении систем высокой готовности, главная цель — обеспечить минимальное время простоя.
Для того, чтобы система обладала высокими показатели готовности, необходимо:
• чтобы ее компоненты были максимально надежными
• чтобы она была отказоустойчивая, желательно, чтобы не имела точек отказов
• а также важно, чтобы она была удобна в обслуживании и разрешала проводить замену компонент без останова Пренебрежение любым из указанных параметров, может привести к потере функциональности системы.
Типы кластеров. Условное деление на классы предложено Язеком Радаевским и Дугласом Эдлайном:
Класс I. Класс машин строится целиком из стандартных деталей, которые продают многие поставщики компьютерных компонентов (низкие цены, простое обслуживание, аппаратные компоненты доступны из различных источников).
Класс II. Система имеет эксклюзивные или не слишком широко распространенные детали. Таким образом можно достичь очень хорошей производительности, но при более высокой стоимости.
Итак, в настоящее время кластер состоит из вычислительных узлов на базе стандартных процессоров, соединенных высокоскоростной системной сетью (интерконнектом), а также, как правило, вспомогательной и сервисной сетями. Большинство кластерных систем списка Тор500 выполнены на процессорах Intel (Intel Xeon, Intel Xeon EM64T, Intel Itanium 2). Часто используются процессоры Power и PowerPC компании IBM. В последнее время популярностью пользуются процессоры AMD (особенно AMD Opteron и его недавно вышедшая двухъядерная версия).
Вкачестве вычислительных узлов чаще всего используются двухпроцессорные SMP-серверы в корпусе от 1U до 4U, собранные в 19-дюйм стойки. Компактные устройства позволяют создавать высокопроизводительные решения с максимальной удельной плотностью, более крупные - недорогие системы. Иногда ведущие изготовители предлагают собственный формфактор: например, IBM, Verari, LinuxNetworx и другие компании предлагают вычислительные узлы на основе блэйдтехнологий, которые обеспечивают высокую плотность установки, но удорожают решение. На российском рынке блэйдрешения пока мало востребованы из-за их высокой стоимости.
Каждый узел работает под управлением своей копии стандартной операционной системы, в большинстве случаев - Linux. Состав и мощность узлов могут быть разными в рамках одного кластера, однако чаще строятся однородные кластеры. Выбор конкретной коммуникационной среды (интерконнекта) определяется многими факторами: особенностями решаемых задач, доступным финансированием, требованиями к масштабируемости и т. п. В кластерных решениях применяются такие технологии интерконнекта, как Gigabit Ethernet, SCI, Myrinet, QsNet, InfiniBand.
Кластер - это сложный программно-аппаратный комплекс, и задача построения кластера не ограничивается объединением большого количества процессоров в один сегмент. Для того чтобы кластер быстро и правильно считал задачу, все комплектующие должны быть тщательно подобраны друг к другу с учетом требований программного обеспечения, так как производительность кластерного ПО сильно зависит от архитектуры кластера, характеристик процессоров, системной шины, памяти и интерконнекта. Использование тех или иных компонентов сильно зависит от задачи, для которой строится кластер. Для некоторых хорошо распараллеливаемых задач (таких, как рендеринг независимых сюжетов в видеофрагменте) основной фактор быстродействия - мощный процессор, и производительность интерконнекта не играет основной роли. В то же время для задач гидро- и аэродинамики, расчета крэш-тестов важна производительность системной сети, иначе увеличение числа узлов в кластере будет мало влиять на скорость решения задачи.
Системная сеть, или высокоскоростная коммуникационная среда, выполняет задачу обеспечения эффективности вычислений. Gigabit Ethernet - наиболее доступный тип коммуникационной среды, оптимальное решение для задач, не требующих интенсивных обменов данными (например, визуализация трехмерных сцен или обработка геофизических данных). Эта сеть обеспечивает пропускную способность на уровне MPI* (около 70 Мбайт/с) и задержку (время между отправкой и получением пакета с данными) примерно 50 мкс. Myrinet - наиболее распространенный тип коммуникационной среды с пропускной способностью до 250 Мбайт/с и задержкой 7 мкс, а новое, недавно анонсированное ПО для этой сети позволяет сократить эту цифру в два раза. Сеть SCI отличается небольшими задержками - менее 3 мкс на уровне MPI - и обеспечивает пропускную способность на уровне MPI от 200 до 325 Мбайт/с. QsNet - очень производительное и дорогое оборудование, обеспечивающее задержку менее 2 мкс и пропускную способность до 900 Мбайт/с. Наиболее перспективная на сегодня технология системной сети - InfiniBand. Ее текущая реализация имеет пропускную способность на уровне MPI до 1900 Мбайт/с и время задержки от 3 до 7 мкс. Один из наиболее интересных продуктов, появившихся в последнее время, - высокоскоростной адаптер компании PathScale, который реализует стандартные коммутаторы и кабельную структуру InfiniBand, используя собственный транспортный протокол. Это позволило достичь рекордно низкого времени задержки - 1,3 мкс.
Сейчас существуют два способа внутреннего устройства стандартных системных сетей. Например, сеть SCI имеет топологию двухили трехмерного тора и не требует применения коммутаторов, что уменьшает стоимость системы. Однако эта технология имеет существенные ограничения по масштабируемости.
Остальные общедоступные высокоскоростные технологии системных сетей Myrinet, QsNet, InfiniBand используют коммутируемую топологию Fat Tree. Вычислительные узлы кластера соединяются кабелями с коммутаторами нижнего уровня (leaf, или edge switches), которые в свою очередь объединяются через коммутаторы верхнего уровня (core, или spine switches). При такой топологии имеется много путей передачи сообщений между узлами, что позволяет повысить эффективность передачи сообщений благодаря распределению загрузки при использовании различных маршрутов. Кроме того, при помощи Fat Tree можно объединить практически неограниченное количество узлов, сохранив при этом хорошую масштабируемость приложений.
Задача эффективного доступа узлов к данным (например, к внешнему хранилищу) чаще всего решается с помощью вспомогательной сети (как правило, Gigabit Ethernet). Иногда для этого применяют каналы Fibre Channel (это значительно увеличивает стоимость системы) или системную сеть (например, InfiniBand в кластерах баз данных). Вспомогательная (или сервисная) сеть также отвечает за распределение задач между узлами кластера и управление работой заданий. Она используется для файлового обмена, сетевой загрузки ОС узлов и управления узлами на уровне ОС, в том числе мониторинга температурного режима и других параметров работы узлов. Сервисная сеть применяется и для так называемого управления узлами out-of-band, т. е. без участия операционной системы. К нему относятся "плавное", последовательное включение и выключение узлов во избежание большого скачка напряжения, аппаратный сброс узла и доступ к его консоли на всех этапах работы, что позволяет диагностировать поломки в недоступных узлах, изменять настройки ОС и др. Ведущие изготовители суперкомпьютеров, такие, как IBM, SUN, HP, вводят в состав узла специальные платы, позволяющие осуществлять управление out-of-band, которые в пересчете на весь кластер довольно дороги. К счастью, есть гораздо более доступное российское решение с аналогичной функциональностью - сеть ServNet, разработанная в Институте программных систем РАН и успешно применяемая в отечественных кластерных системах, в частности в кластерах "СКИФ". Компактная плата ServNet (всего 66x33 мм) легко встраивается в вычислительный узел и позволяет, кроме всего вышеперечисленного, изменять параметры BIOS узла, выбирать загружаемую ОС, изменять параметры загрузки ядра Linux, контролировать критические сообщения ОС и проводить "посмертное" чтение (из энергонезависимой памяти платы ServNET) нескольких последних сообщений ОС.
Суперкомпьютеры - это всегда очень большие мощности. В сложившейся ситуации уже невозможно рассматривать высокопроизводительные вычислительные системы отдельно от систем их размещения, охлаждения и электропитания. Например, "СКИФ К-1000" потребляет более 89 кВт, и практически все уходит в тепло. Такой мощности было бы достаточно для обогрева небольшого дома, но все 288 узлов формфактора 1U стоят в восьми стойках, и без продуманного теплового дизайна не обойтись. В первых суперкомпьютерах использовалось жидкостное охлаждение, но такие охладительные системы нередко выходили из строя. В современных суперкомпьютерах применяют воздушное охлаждение, и необходимый температурный режим обеспечивается двумя факторами. Во-первых, продуманным тепловым дизайном вычислительного узла: стандартные шасси необходимо модернизировать для того, чтобы воздушный поток, создаваемый внутренними вентиляторами, максимально эффективно охлаждал процессоры. Во-вторых, поддержанием рабочей температуры в помещении: горячий воздух должен быть либо отведен от узлов и кондиционирован, либо направлен за пределы помещения.
Оптимизация энергопотребления - не менее серьезная задача. По мнению мировых экспертов, при современных темпах роста производительности систем и сохранении характеристик их энергопотребления уже к 2010 г. самые мощные суперкомпьютеры будут потреблять столько энергии, что обеспечить ее подачу и отвод тепла будет невозможно. Однако проблема обеспечения бесперебойного питания существует и для систем со средней производительностью, и каждый изготовитель решает ее посвоему.
Блейд-серверы, лезвия (англ. blade) — компьютерные серверы с компонентами, вынесенными и обобщѐнными в корзине для уменьшения занимаемого пространства. Корзина (англ. enclosure) — шасси для блейд-серверов, предоставляющая им доступ к общим компонентам, например, блокам питания и сетевым контроллерам. Блейд-серверы называют также ультракомпактными серверами.
Внутренняя структура В блэйд-сервере отсутствуют или вынесены наружу некоторые типичные компоненты, традиционно присутствующие в
компьютере. Функции питания, охлаждения, сетевого подключения, подключения жѐстких дисков, межсерверных соединений и управления могут быть возложены на внешние агрегаты. Вместе с ними набор серверов образует т. н. блэйд-систему.
Для вычислений компьютеру требуются как минимум следующие части (машина Тьюринга):
•память, содержащая исходные данные,
•процессор, выполняющий команды,
•память для записи результатов.
Остальные компоненты, типичные для компьютера, выполняют вспомогательные для вычислений функции, такие как ввод и вывод, обеспечение питания. Внутри сервера они представляют собой дополнительные потребители энергии, источники тепла, причины сбоев (особенно компоненты с движущимися частями). Концепция блэйд-сервера предусматривает замену их внешними агрегатами (блоки питания) или виртуализацию (порты ввода-вывода, консоли управления), тем самым значительно упрощая и облегчая сам сервер, а также делая его производство (теоретически) дешевле.
Внешние подключаемые блоки
Стопка блэйд-серверов IBM HS20. В каждом из них установлено по два процессора Intel Xeon 2,8 ГГц, два 36 ГБ Ultra-320 SCSI жестких диска и 2 ГБ ОЗУ
Блэйд-системы состоят из набора блэйд-серверов и внешних компонентов, обеспечивающих невычислительные функции. Как правило, за пределы серверной материнской платы выносят компоненты, создающие много тепла, занимающие много места, а также повторяющиеся по функциям между серверами. Их ресурсы могут быть распределены между всем набором серверов. Деление на встроенные и внешние функции варьируется у разных производителей.
Источники питания Преобразователь напряжения питания, как правило, создается общим для блэйд-системы. Он может быть как вмонтирован
внутрь нее, так и вынесен в отдельный блок. По сравнению с суммой отдельных блоков питания, необходимых серверам формата 1U, единый источник питания блэйд-систем — один из самых весомых источников экономии пространства, энергопотребления и числа электронных компонентов.
Охлаждение Традиционный дизайн серверов пытается сбалансировать плотность размещения электронных компонентов и возможность
циркуляции охлаждающего воздуха между ними. В блэйд-конструкциях количество выступающих и крупных частей сведено к минимуму, что улучшает охлаждение модулей.
Сетевые подключения Современные сетевые интерфейсы рассчитаны на чрезвычайно большие скорости передачи данных через токопроводящие и
оптические кабели . Такая аппаратура дорога́и занимает место в конструкции сервера . Частый случай — чрезмерная пропускная способность сетевых интерфейсов, чьи возможности оказываются не востребованы в практических задачах. Объединение сетевых интерфейсов в одно устройство или использование специальных блэйд-слотов, занятых исключительно работой с сетью, позволяет сократить количество разъемов и снизить стоимость каждого из подключений.
Использование дисковых накопителей