

EKZAMEN
.pdfВ настоящее время разработка нейрокомпьютеров ведется в большинстве промышленно развитых стран.
Нейрокомпьютеры позволяют с высокой эффективностью решать целый ряд интеллектуальных задач. Это задачи распознавания образов, адаптивного управления, прогнозирования, диагностики и т.д.
Нейрокомпьютеры отличаются от ЭВМ предыдущихи поколений не просто большими возможностями. Принципиально меняется способ использования машины. Место программирования занимает обучение, нейрокомпьютер учится решать задачи. Обучение - корректировка весов связей, в результате которой каждое входное воздействие приводит к формированию соответствующего выходного сигнала. После обучения сеть может применять полученные навыки к новым входным сигналам. При переходе от программирования к обучению повышается эффективность решения интеллектуальных задач.
Вычисления в нейронных сетях существенно отличаются от традиционных, в силу высокой параллеленности их можно рассматривать как коллективное явление. В нейронной сети нет локальных областей, в которых запоминается конкретная информация. Вся информация запоминается во всей сети.
Толчком к развитию нейрокомпьютинга послужили биологические исследования. По данным нейробиологии нервная система человека и животных состоит из отдельных клеток - нейронов. В мозге человека их число достигает 1.0e10 - 1.0e12. Каждый нейрон связан с 1.0e3 - 1.0e4 другими нейронами и выполняет сравнительно простые действия. Время срабатывания нейрона - 2-5 мс. Совокупная работа всех нейронов обуславливает сложную работу мозга, который в реальном времени решает сложнейшие задачи. Отличия нейрокомпьютеров от вычислительных устройств предыдущих поколений:
•параллельная работа очень большого числа простых вычислительных устройств обеспечивает огромное быстродействие;
•нейронная сеть способна к обучению, которое осуществляется путем настройки параметров сети;
•высокая помехо- и отказоустойчивость нейронных сетей;
•простое строение отдельных нейронов позволяет использовать новые физические принципы обработки информации для
аппаратных реализаций нейронных сетей.
Нейронные сети находят свое применение в системах распознавания образов, обработки сигналов, предсказания и диагностики, в робототехнических и бортовых системах. Нейронные сети обеспечивают решение сложных задач за времена порядка времен срабатывания цепочек электронных и/или оптических элементов. Решение слабо зависит от неисправности отдельного нейрона. Это делает их привлекательными для использования в бортовых интеллектуальных системах.
Разработки в области нейрокомпьютеров поддерживаются целым рядом международных и национальных программ. В настоящее время эксплуатируется не менее 50 нейросистем в самых различных областях - от финансовых прогнозов до экспертизы.
Разработки в области нейрокомпьютинга ведутся по следующим направлениям:
•разработка нейроалгоритмов;
•создание специализированного программного обеспечения для моделирования нейронных сетей;
•разработка специализированных процессорных плат для имитации нейросетей;
•электронные реализации нейронных сетей;
•оптоэлектронные реализации нейронных сетей.
Внастоящее время наиболее массовым направлением нейрокомпьютинга является моделирование нейронных сетей на обычных компьютерах, прежде всего персональных. Моделирование сетей выполняется для их научного исследования, для решения практических задач, а также при определении значений параметров электронных и оптоэлектронных нейрокомпьютеров.
78.Архитектурные особенности ЦСП и нейрочипов
Архитектура сигнальных процессоров, по сравнению с микропроцессорами настольных компьютеров, имеет некоторые особенности:
•Гарвардская архитектура (разделение памяти команд и данных), как правило модифицированная;
•Большинство сигнальных процессоров имеют встроенную оперативную память, из которой может осуществляться выборка нескольких машинных слов одновременно. Нередко встроено сразу несколько видов оперативной памяти, например, в силу Гарвардской архитектуры бывает отдельная память для инструкций и отдельная — для данных.
•Некоторые сигнальные процессоры обладают одним или даже несколькими встроенными постоянными запоминающими устройствами с наиболее употребительными подпрограммами, таблицами и т. п.
•Аппаратное ускорение сложных вычислительных инструкций, то есть быстрое выполнение операций, характерных для цифровой обработки сигналов, например, операция «умножение с накоплением» (MAC) (Y := X + A × B) обычно исполняется за один такт.
•«Бесплатные» по времени циклы с заранее известной длиной. Поддержка векторно-конвейерной обработки с помощью генераторов адресных последовательностей.
•Детерминированная работа с известными временами выполнения команд, что позволяет выполнять планирование работы в реальном времени.
•Сравнительно небольшая длина конвейера, так что незапланированные условные переходы могут занимать меньшее время, чем в универсальных процессорах.
•Экзотический набор регистров и инструкций, часто сложных для компиляторов. Некоторые архитектуры используют
VLIW.
•По сравнению с микроконтроллерами, ограниченный набор периферийных устройств — впрочем, существуют «переходные» чипы, сочетающие в себе свойства DSP и широкую периферию микроконтроллеров.
Особенности реализации нейрочипов Для начала определим те основные особенности, которые накладывает специфика нейронных сетей на аппаратную
реализацию. Поскольку нейронная сеть представляет собой большое количество одинаковых параллельно работающих простейших элементов — нейронов, то при ее аппаратной реализации желательно обеспечить массовое параллельное выполнение простейших операций, причем чем большая степень параллельности вычислений достигается, тем лучше. Традиционным методом повышения степени параллельности вычислений является каскадирование процессоров, т.е. объединение нескольких процессоров в единой вычислительной системе для решения поставленной задачи. Поскольку процессоры работают независимо друг от друга, то вроде бы достигается необходимая степень параллельности. Однако не следует забывать об обмене данными между процессорами. Каналы обмена данными - то «узкое горло», которое может свести на нет все выигрыши в скорости вычислений. Действительно, если 32-разрядные процессоры работают на тактовой частоте, предположим, 200 МГц, а 32-разрядные каналы связи обеспечивают передачу данных с частотой, например, 20 МГц, то такие межсоединения будут на порядок замедлять совместную скорость работы соединенных между собой процессоров. Разработчики параллельных систем всеми силами борются за расширение «узкого горла», но скорость современных процессоров все равно растет быстрее, чем пропускная способность каналов передачи данных. Поэтому зачастую более выгодным решением оказывается использовать один более мощный процессор, чем несколько менее мощных, соединенных между собой.
Традиционно считается, что нейронные сети можно успешно реализовать на универсальных процессорах, RISC-процессорах или на специализированных нейронных процессорах (нейрочипах). У каждого из перечисленных типов аппаратной реализации есть свои достоинства и недостатки.
Универсальные микропроцессоры, ярким представителем которых является семейство Intel 386/486/Pentium/PII/PIII, являются наиболее доступными и успешно используются для моделирования нейронных сетей. Доступность и распространенность компьютерных систем, построенных на таких процессорах, являются весомыми достоинствами для их применения. В качестве их основных недостатков для моделирования нейронных сетей обычно отмечается неадекватность (избыточность) архитектуры (хотя этот «недостаток» находится под большим вопросом) и сложности, связанные с каскадированием, т.е. сложности при построении многопроцессорных систем для увеличения суммарной производительности, хотя в свете вышесказанного этот недостаток также можно оспорить.
RISC-процессоры лишены указанных недостатков, поскольку имеют возможности каскадирования, предусмотренные на аппаратном уровне, да и архитектура их более адекватна для выполнения нейронных операций. Однако, существенной их чертой, снижающей эффективность применения, является дороговизна и относительно малое распространение среди широких масс разработчиков. Многие лишь слышали, что такие процессоры существуют, но никогда с ними не работали. Наиболее известными типами современных RISC-процессоров, применяемых в моделировании нейронных систем, являются TMS
компании Texas Instruments, ADSP компании Analog Devices, SHARC и другие.
Нейронный процессор можно рассматривать как супер-RISC-процессор, ориентированный на выполнение нейронных операций и обеспечивающий их массовое выполнение. Разумеется, нейропроцессор обеспечивает большую скорость при выполнении нейронных операций, чем универсальные или RISC-процессоры. Современные проектные решения позволяют интегрировать нейропроцессоры в вычислительные системы, построенные на базе RISC-процессоров, обеспечивая таким образом их совместимость. Но «звездный час» нейропроцессоров пока не наступил. Виной тому их высокая стоимость (выше, чем даже у RISC-процессоров) и малая известность.
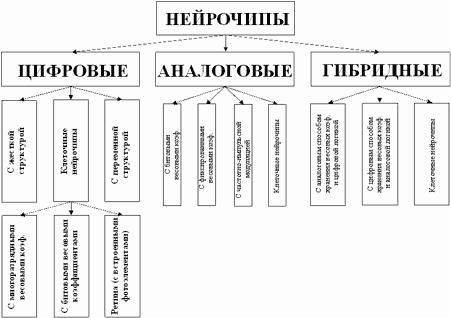
79.Классификация и элементная база нейрочипов
Элементной базой перспективных нейровычислителей являются нейрочипы. Их производство ведется во многих странах мира, причем большинство из них на сегодня ориентированны на закрытое использование (т.е. создавались для конкретных специализированных управляющих систем). Основные характеристики коммерчески доступных нейрочипов приведены в таблице 1 [1-8].
Прежде чем перейти рассмотрению наиболее интересных нейрочипов остановимся на их классификации. По типу логики их можно разделить на цифровые, аналоговые и гибридные.
По типу реализации нейроалгоритмов: с полностью аппаратной реализаций и с программно-аппаратной реализацией (когда нейроалгоритмы хранятся в ПЗУ).
По характеру реализации нелинейных преобразований: на нейрочипы с жесткой структурой нейронов (аппаратно реализованных) и нейрочипы с настраиваемой структурой нейронов (перепрограммируемые).
По возможностям построения нейросетей: нейрочипы с жесткой и переменной нейросетевой структурой (т.е. нейрочипы в которых топология нейросетей реализована жестко или гибко).
Процессорные матрицы (систолические процессоры) - это чипы, обычно близкие к обычным RISC процессорам и объединяющее в своем составе некоторое число процессорных элементов, вся же остальная логика, как правило, должна быть реализована на базе периферийных схем.
В отдельный класс следует выделить так называемые нейросигнальные процессоры, ядро которых представляет собой типовой сигнальный процессор, а реализованная на кристалле дополнительная логика обеспечивает выполнение нейросетевых операций (например, дополнительный векторный процессор и т.п.).
Обобщенная классификация нейрочипов приведена на рис.1.
Рис.1. Обобщенная классификация нейрочипов.
Кроме широко спектра фирм и корпораций (таблица 1), исследования в области современных нейропроцессоров проводят многие лаборатории и университеты, среди которых можно отметить
[2]:
• В США: Naval
Lab, MIT Lab,
Пенсельванский Университет, Колумбийский Университет, Аризонский Университет, Иллинойский
Университет и др.
• В Европе: Берлинский Технический Университет, Технический Университет в Карлсруе
и др.
• В России: МФТИ, Ульяновский Государственный Технический Университет, МГТУ им.Н.Э.Баумана (более десятка лабораторий занимающихся вопросами нейровычислителей на четырех факультетах: "Информатики и систем управления", "Специального машиностроения", "Радиоэлектроники и лазерной техники", "Биомедицинских систем"), Красноярский Государственный Технический Университет, Ростовский Государственный Университет и др.
Для оперативного информарования научной общественности и создании единого образовательного пространства в области нейроинформатики на кафедре "Конструирование и технология производства электронной аппаратуры" в рамках программ министерства образования России: Научно-методическая программа "Научно-методическое обеспечение дистаницонного образования" и Научно-технической программы "вычислительная техника, автоматизация, и интеграция сетей" проводятся работы по созданию интерактивной глобальной информационно-обучающей системы в области нейрокомпьютеров и нейроинформатикии (http://neurnews.iu4.bmstu.ru, http://cdl.iu4.bmstu.ru).
Разработка нейрочипов ведется во многих странах мира. На сегодня [2] выделяют две базовые линии развития вычислительных систем с массовым параллелизмом (ВСМП) : ВСМП с модифицированными последовательными алгоритмами, характерными для однопроцессорных фоннеймановских алгоритмов и ВСМП на основе принципиально новых сверпараллельных нейросетевых алгоритмов решения различных задач (на базе нейроматематике).
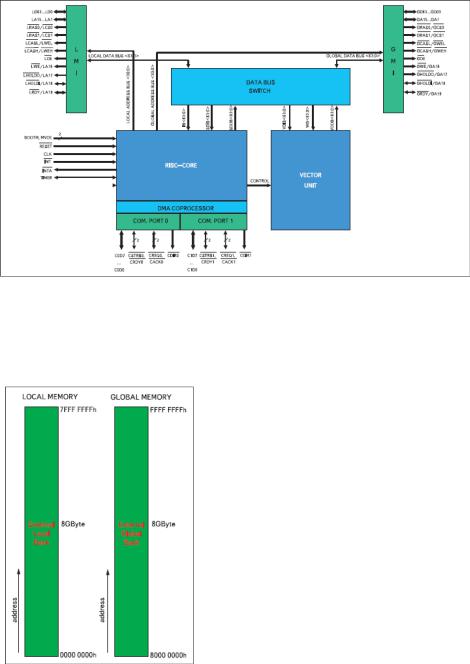
80. Архитектура нейросигнального процессора NeuroMatrix
NeuroMatrix — микропроцессорная архитектура, разработанная в компании НТЦ «Модуль». Выпущены и готовятся к выпуску несколько представителей архитектуры. Наиболее известен первый представитель семейства, микропроцессор Л1879ВМ1 (nm6403). Устройства на базе NeuroMatrix предназначены для цифровой обработки сигналов.
Описание архитектуры процессоров семейства NeuroMatrix®
Научно-техническим центром «Модуль» разработано семейство цифровых процессоров сигналов NeuroMatrix, в том числе Л1879ВМ1 (NM6403) и 1879ВМ2 (NM6404). Дальнейшее развитие семейства связано с завершением разработки и запуском на изготовление в 2006 году процессора третьего поколения 1879ВМ4 (NM6405). Особенностью данного семейства является оригинальная, запатентованная векторно-матричная архитектура, обеспечивающая высокое соотношение производительности и цены устройств. Следует особо подчеркнуть, что это полностью отечественная разработка.
Процессоры семейства 1879ВМх представляют собой высокопроизводительные вычислительные устройства, имеющие RISC-
архитектуру с элементами VLIW (Very Long Instruction Word), SIMD (Single Instruction Multiple Data) и суперскаляра.
Архитектура и структура обеспечивают: аппаратную поддержку матричных и векторных операций над векторами, представляющими собой 64-разрядные слова, в которых упакованы данные, представленные в дополнительном коде с фиксированной точкой; программную настройку исполнительных узлов для работы с векторами данных, содержащих необходимое количество элементов требуемой разрядности (в общем случае количество элементов в векторе и их разрядность должны принимать любое значение в пределах от 1 до 64, суммарная разрядность всех элементов каждого вектора должна составлять 64 разряда); исполнение векторных команд в течение нескольких процессорных тактов, число которых (от 1 до 32) определяется специальным полем команды.
Процессор Л1879ВМ1
Рис. 1. Структурная схема процессора Л1879ВМ1
В течение уже более семи лет выпускается и широко применяется цифровой микропроцессор сигналов Л1879ВМ1. Этот процессор изготавливается по КМОП технологии 0,5 мкм фирмой Samsung. Он работает на частотах до 40 МГц в диапазоне температур от –40 до +85 °С и напряжений от 3,0 до 3,6 В.
Количество операций «умножение с накоплением», выполняемых за один процессорный такт, от 2 (32-разрядные данные) до 224 (2-
разрядные данные), поэтому пиковая производительность процессора в указанных условиях составляет 8,96 млрд умножений с накоплением (GMAC). В 1999 году лицензия на использование микропроцессорного ядра этого процессора была приобретена фирмой Fujitsu.
Л1879ВМ1 поддерживает работу с 32-разрядными скалярными данными и векторными данными программируемой разрядности от 1 до 64, упакованными в 64-разрядные блоки данных. Структурная схема процессора представлена на рис. 1, а его карта памяти изображена на рис. 2.
Рис. 2. Карта памяти процессора Л1879ВМ1
Процессор состоит из следующих функциональных узлов:
RISC CORE — RISC-процессор, имеющий 5-ступенчатый конвейер и выполняющий скалярные арифметические, логические операции и операции сдвига над 32-разрядными данными, а также осуществляющий управление выполнением программ.
VECTOR UNIT — векторный узел, выполняющий арифметические и логические операции над 64-разрядными векторами данных, упакованных в 64разрядные блоки данных произвольной разрядности.
LMI и GMI — два идентичных 64-разрядных интерфейса во внешнюю память — локальную и глобальную. Каждый интерфейс имеет возможность работать с двумя банками внешней памяти типа SRAM/DRAM и поддерживает режим работы с общей памятью с другим процессором. Л1879ВМ1 использует 32разрядный адрес, причем обмен данными с памятью осуществляется по 32 или 64 разряда. Таким образом, доступное адресное пространство равно 16 Гбайт. Если старший разряд адреса равен нулю, идет обращение в локальную память, если равен единице — в глобальную. Младший разряд адреса используется только при обмене 32-разрядными данными.
COM. PORT0 и COM. PORT1 — два байтовых коммуникационных порта ввода/вывода для межпроцессорного обмена, аппаратно совместимые с портами DSP TMS320C4x фирмы Texas Instruments.
DMA COPROCESSOR — сопроцессор ПДП, осуществляющий обмен 64-разрядными данными между памятью и портами.
DATA BUS SWITCH — коммутатор шин данных, позволяющий динамически связать одну из внешних шин с одной из шести внутренних: команд IB<63:0>, входных SDIB<63:0> и выходных скалярных данных SDOB<63:0>, входных VDIB<63:0> и выходных векторных данных VDOB<63:0>, а также с входной шиной весов WB<63:0>.
RISC-процессор
Процессор представляет собой 5-ступенчатый 32-разрядный RISC с оригинальной системой команд. Он использует 32- и 64разрядные команды (одна команда обычно задает две операции: арифметическую и ввода/вывода). Все узлы RISC 32разрядные.
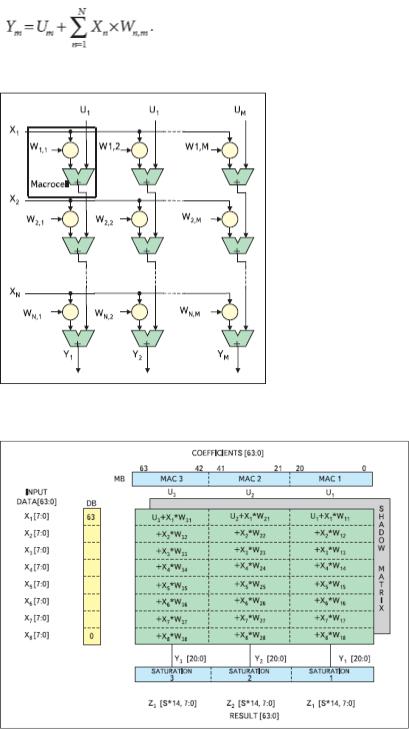
Векторный узел
Архитектура NeuroMatrix® дает уникальную возможность варьировать между производительностью и точностью вычислений для базовой процедуры:
В зависимости от приложения можно выбрать необходимую разрядность входных данных и результата (точность вычислений). Число умножений и сложений (MAC), выполняемых за один такт, зависит от разрядности операндов. Наибольшая производительность — 8960 MMAC — достигается при работе с 2-разрядными операндами на частоте 40 МГц. Имеется возможность поднять точность вычислений, если увеличить разрядность операндов до 32. В этом случае достигается производительность 80 MMAC с получением 64-разрядного результата. Векторный узел содержит операционное устройство регулярной структуры, похожее на матричный умножитель (рис.
3).
Рис. 3. Операционное устройство векторного узла Данное устройство состоит из ячеек, содержащих 1-разрядную
память (триггер) и некоторую комбинационную логику. Пользователь может поделить матрицу ячеек на макроячейки, используя два программно доступных 64-разрядных конфигурационных регистра. Эти регистры задают границы между строками и столбцами макроячеек таким образом, что каждая макроячейка выполняет операцию умножения элемента входного вектора Xi на заранее загруженный вес Wij, а затем результат прибавляется к выходному значению верхней макроячейки, расположенной в том же столбце. Таким образом, за один такт в каждом столбце независимо вычисляется свой результат. Пример конфигурации векторного узла для работы с 8- разрядными входными данными (Xi) и весами (Wij) приведен на рис. 4. В этом случае достигается пиковая производительность в 960 MMAC (за один 25 нс процессорный такт производятся 24 операции умножений с накоплением (MAC) с получением 21-
разрядных результатов).
Рис. 4. Пример работы векторного узла с 8-разрядными входными данными и весами Число операций умножений с накоплением зависит от разрядности входных операндов и весов. Конфигурация векторного узла
может меняться динамически в процессе вычислений. Можно начать вычисления с небольшой разрядностью и с большой производительностью, а затем по мере накопления разрядности в промежуточных результатах перейти к обработке данных большей разрядности за счет снижения быстродействия. На рис. 5 можно наглядно видеть, как зависит производительность от разрядности входных операндов и весов.
Рис. 5. Зависимость производительности от разрядности входных операндов и весов Операционное устройство
достигает еще большей производительности при выполнении булевого умножения, когда разрядность входных операндов и весов равна 1. В этом
случае она равна 40,96 GMOPS на частоте 40 МГц. Имеется еще одно интересное свойство использования 1-разрядных коэффициентов. В этом случае операционное устройство превращается в мощный коммутатор, когда перестановка битов в 64разрядном входном операнде происходит за один такт.
Загрузка новых весовых коэффициентов в операционное устройство осуществляется за 32 такта. Чтобы скомпенсировать задержку при изменении весов, используется теневая матрица. Новые коэффициенты грузятся в теневую матрицу в фоновом режиме и затем за один такт переписываются в рабочую.
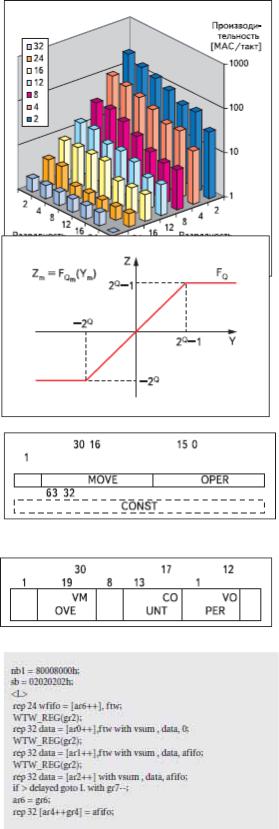
Для предотвращения переполнения аппаратно реализована функция насыщения (рис. 6) над 64-разрядными словами упакованных данных, причем границы насыщения задаются с помощью программно доступных регистров управления этой функцией. Функция насыщения не уменьшает разрядность входных операндов, но уменьшает число значащих разрядов в каждом элементе входного вектора.
Рис. 6. Функция насыщения Система команд
Команды процессора делятся на две основные группы: скалярные команды (рис. 7) и векторные (рис. 8).
Рис. 7. Кодировка скалярных команд
Рис. 8. Кодировка векторных команд
Скалярные команды являются обычными RISC-командами, которые также задают условные переходы/переходы к подпрограмме и возвраты из подпрограммы/прерывания. Процессор поддерживает работу с 32-разрядными константами, которые могут грузиться в регистры или использоваться для задания адреса или смещения при обращении к памяти. Векторные команды содержат специальное поле, задающее число повторов выполнения данной команды (от 1 до 32). Это позволяет аппаратно поддержать организацию коротких циклов и значительно увеличить плотность кода.
Конвейер Л1879ВМ1 состоит из нескольких подконвейеров. Любая скалярная или векторная команда в данный момент времени занимает один или несколько подконвейеров. Если имеются необходимые свободные подконвейеры, очередная команда может пойти на выполнение (но не более одной команды за такт). При использовании многотактовых векторных команд до четырех векторных, включая два доступа в память, и одной скалярной команды могут выполняться одновременно. Синхронизация различных подконвейеров осуществляется с
помощью механизма блокировок. Если команда требует некоторый ресурс, который в данный момент занят, формируется блокировка, и выполнение команды приостанавливается. Принадлежащие команде подконвейеры блокируются, остальные же могут продолжать свою работу. Таким образом, несмотря на последовательный запуск команды в конвейер на выполнение, использование векторных команд позволяет достичь производительности суперскалярных процессоров. Завершение команд поддерживается не в том порядке, в котором они
выбирались из памяти (out-of-order execution). Вместе с тем достигается высокий уровень загрузки аппаратуры на кристалле, поскольку скалярные и векторные команды используют единый конвейер и одни и те же исполнительные устройства. При этом требуется небольшое количество управляющей логики (менее 5%
от 115 000 используемых на кристалле вентилей).
В качестве примера приведем программу на ассемблере вычисления фильтра-свертки 3×3:
Первые две команды делят операционное устройство на 4 колонки по 16 разрядов и 8 строк по 8 разрядов. Третья загружает веса в теневую матрицу, а четвертая переписывает теневую матрицу в рабочую. Затем происходит вычисление промежуточного результата свертки с использованием трех элементов первой строки маски 3×3. Шестая команда переписывает новые веса из теневой матрицы в рабочую. Потом вычисляется промежуточный результат свертки с использованием трех элементов второй строки маски 3×3 с прибавлением результата пятой команды. Восьмая команда снова меняет веса в рабочей матрице. По девятой вычисляется промежуточный результат свертки с использованием трех элементов третьей строки маски 3×3 с прибавлением результата седьмой команды. Десятая команда задает отложенный переход на начало цикла. Термин «отложенный переход» означает, что следующие две команды будут выполнены, прежде чем произойдет сам переход. Первая отложенная команда восстанавливает указатель памяти весов, а вторая пишет
результат вычислений в память.
Результат сравнения производительности Л1879ВМ1 и DSP TMS320C80 фирмы Texas Instruments на задачах вычисления фильтра свертки приведен в таблице 1. Данные для TMS320C80 взяты из [18]. Важно отметить, что число циклов для Л1879ВМ1 с увеличением размера маски свертки растет линейно.
Таблица 1. Вычисление сверток
Область применения и оценка производительности Процессор Л1879ВМ1 используется в целом ряде применений, требующих большую производительность при умеренном потреблении питания:
цифровая обработка сигналов (БПФ, ДПФ, преобразование Уолша-Адамара);
видеообработка (фильтрация);
эмуляция нейронных сетей и матрично-векторные операции;
телекоммуникация;
встроенные системы;
многопроцессорные вычислительные комплексы.
Производительность Л1879ВМ1 на тестовых задачах для DSP приведена в таблице 2. Параметры задач следующие: для фильтра Собеля размер кадра 384 288 байт; БПФ для 256 точек, разрядность — 32; преобразование Уолша-Адамара — 2 М точек, входные данные — 5 разрядов, результат — 32 разряда. Более подробно об оценке производительности Л1879ВМ1 на различных задачах можно познакомиться в работах [19–25].
Таблица 2. Производительность на тестовых задачах для DSP