

EKZAMEN
.pdf27.Особенности реализации каналов передачи данных в кластерных ВС
Под кластером обычно понимается множество отдельных компьютеров, объединенных в сеть, для которых при помощи специальных аппаратно-программных средств обеспечивается возможность унифицированного управления (single system image), надежного функционирования (availability) и эффективного использования (performance). Кластеры могут быть образованы на базе уже существующих у потребителей отдельных компьютеров либо же сконструированы из типовых компьютерных элементов, что обычно не требует значительных финансовых затрат. Вместе с этим следует отметить, что организации взаимодействия вычислительных узлов кластера при помощи передачи сообщений обычно приводит к значительным временным задержкам, что накладывает дополнительные ограничения на тип разрабатываемых параллельных алгоритмов и программ.
При организации параллельных вычислений в МВС для организации взаимодействия, синхронизации и взаимоисключения параллельно выполняемых процессов используется передача данных между процессорами вычислительной среды. Временные задержки при передаче данных по линиям связи могут оказаться существенными (по сравнению с быстродействием процессоров) и, как результат, коммуникационная трудоемкость алгоритма оказывает существенное влияние на выбор
параллельных способов решения задач.
К числу типовых топологий обычно относят следующие схемы коммуникации процессоров:
- полный граф (completely-connected graph or clique)- система, в которой между любой парой процессоров существует прямая линия связи; как результат, данная топология обеспечивает минимальные затраты при передаче данных, однако является сложно реализуемой при большом количестве процессоров;
-линейка (linear array or farm) - система, в которой каждый процессор имеет линии связи только с двумя соседними (с предыдущим и последующим) процессорами; такая схема является, с одной стороны, просто реализуемой, а с другой стороны, соответствует структуре передачи данных при решении многих вычислительных задач (например, при организации конвейерных вычислений);
-кольцо (ring) - данная топология получается из линейки процессоров соединением первого и последнего процессоров линейки; -звезда (star) - система, в которой все процессоры имеют линии связи с некоторым управляющим процессором; данная топология является эффективной, например, при организации централизованных схем параллельных вычислений;
-решетка (mesh) - система, в которой граф линий связи образует прямоугольную сетку (обычно двухили трехмерную); подобная топология может быть достаточно просто реализована и, кроме того, может быть эффективно используема при параллельном выполнении многих численных алгоритмов (например, при реализации методов анализа математических моделей, описываемых дифференциальными уравнениями в частных производных);
-гиперкуб (hypercube) - данная топология представляет частный случай структуры решетки, когда по каждой размерности сетки имеется только два процессора (т.е. гиперкуб содержит 2N процессоров при размерности N); данный вариант организации сети передачи данных достаточно широко распространен в практике.
Компоненты кластера Базовые строительные блоки (компоненты) кластеров разбиваются на несколько категорий: непосредственно узлы, кластерное
ПО, выделенная сеть, производящая обмен данными между узлами, и соотв-е сетевые протокол.
В типичном случае узел в кластере может быть главным или подчиненным. Главный узел может быть только один. Он отвечает за работу кластера, а также является ключевым для кластерного ПО промежуточного слоя, процессов маршрутизации, диспетчеризации и мониторинга состояния каждого вычислительного узла. Эти узлы, по сути, представляют собой полнофункц-е автономные компьютеры.
Общедоступные кластеры включают одну или более выделенных сетей для передачи пакетов сообщений внутри распределенной системы.
Системная сеть кластера может быть построена на базе традиционных сетевых продуктов, применяемых в ЛВС, либо спроектирована специально для кластерных вычислений. В последнем случае она обеспечивает дополнительную аппаратную поддержку, которая уменьшает латентность. Некоторые современные технологии - Giganet (cLAN), Myrinet, QsNet, Scalable Coherent Interface (SCI).
28.Подходы к программированию вычислительных систем с неоднородной памятью
Всистемах этого типа на каждом вычислительном узле функционирует собственные копии операционной системы, под управлением которых выполняются независимые программы. Это могут быть как действительно независимые программы, так и параллельные ветви одной программы. В этом случае единственно возможным механизмом взаимодействия между ними является механизм передачи сообщений.
Стремление добиться максимальной производительности заставляет разработчиков при реализации механизма передачи сообщений учитывать особенности архитектуры многопроцессорной системы. Это способствует написанию более эффективных, но ориентированных на конкретный компьютер программ. Вместе с тем независимыми разработчиками программного обеспечения было предложено множество реализаций механизма передачи сообщений, независимых от конкретной платформы. Наиболее известными из них являются EXPRESS компании Parasoft и коммуникационная библиотека
PVM (Parallel Virtual Machine), разработанная в Oak Ridge National Laboratory.
В1994 г. был принят стандарт механизма передачи сообщений MPI (Message Passing Interface) [7]. Он готовился с 1992 по 1994 гг. группой Message Passing Interface Forum, в которую вошли представители более чем 40 организаций из Америки и Европы. Основная цель, которую ставили перед собой разработчики MPI - это обеспечение полной независимости приложений, написанных с использованием MPI, от архитектуры многопроцессорной системы, без какой-либо существенной потери производительности. По замыслу авторов это должно было стать мощным стимулом для разработки прикладного программного обеспечения и стандартизованных библиотек подпрограмм для многопроцессорных систем с распределенной памятью. Подтверждением того, что эта цель была достигнута, служит тот факт, что в настоящее время этот стандарт поддерживается практически всеми производителями многопроцессорных систем. Реализации MPI успешно работают не только на классических MPP системах, но также на SMP системах и на сетях рабочих станций (в том числе и неоднородных).
MPI - это библиотека функций, обеспечивающая взаимодействие параллельных процессов с помощью механизма передачи сообщений. Поддерживаются интерфейсы для языков C и FORTRAN. В последнее время добавлена поддержка языка C++. Библиотека включает в себя множество функций передачи сообщений типа точка-точка, развитый набор функций для выполнения коллективных операций и управления процессами параллельного приложения. Основное отличие MPI от предшественников в том, что явно вводятся понятия групп процессов, с которыми можно оперировать как с конечными множествами, а также областей связи и коммуникаторов, описывающих эти области связи. Это предоставляет программисту очень гибкие средства для написания эффективных параллельных программ. В настоящее время MPI является основной технологией программирования для многопроцессорных систем с распределенной памятью. Достаточно подробно MPI будет описан в части 2.
Несмотря на значительные успехи в развитии технологии программирования с использованием механизма передачи сообщений, трудоемкость программирования с использованием этой технологии все-таки слишком велика.
Альтернативный подход предоставляет парадигма параллельной обработки данных, которая реализована в языке высокого уровня HPF [8]. От программиста требуется только задать распределение данных по процессорам, а компилятор автоматически генерирует вызовы функций синхронизации и передачи сообщений (неудачное расположение данных может вызвать существенное увеличение накладных расходов). Для распараллеливания циклов используются либо специальные конструкции языка (оператор FORALL), либо директивы компилятору, задаваемые в виде псевдокомментариев ($HPF INDEPENDENT). Язык HPF реализует идею инкрементального распараллеливания и модель общей памяти на системах с распределенной памятью. Эти два обстоятельства и определяют простоту программирования и соответственно привлекательность этой технологии. Одна и та же программа, без какой-либо модификации, должна эффективно работать как на однопроцессорных системах, так и на многопроцессорных вычислительных системах.
Программы на языке HPF существенно короче функционально идентичных программ, использующих прямые вызовы функций обмена сообщениями. По-видимому, языки этого типа будут активно развиваться и постепенно вытеснят из широкого обращения пакеты передачи сообщений. Последним будет отводиться роль, которая в современном программировании отводится ассемблеру: к ним будут прибегать лишь для разработки языков высокого уровня и при написании библиотечных подпрограмм, от которых требуется максимальная эффективность.
Всередине 90-х годов, когда появился HPF, с ним связывались большие надежды, однако трудности с его реализацией пока что не позволили создать достаточно эффективных компиляторов. Пожалуй, наиболее удачными были проекты, в которых компиляция HPF-программ выполняется в два этапа. На первом этапе HPF-программа преобразуется в стандартную Фортранпрограмму, дополненную вызовами коммуникационных подпрограмм. А на втором этапе происходит ее компиляция стандартными компиляторами. Здесь следует отметить систему компиляции Adaptor [9], разработанную немецким Институтом алгоритмов и научных вычислений, и систему разработки параллельных программ DVM, созданную в Институте прикладной математики им. М.В. Келдыша РАН. Система DVM поддерживает не только язык Фортран, но и C [10]. Наш опыт работы с системой Adaptor показал, что в большинстве случаев эффективность параллельных HPF-программ значительно ниже, чем MPI-программ. Тем не менее, в некоторых простых случаях Adaptor позволяет распараллелить обычную программу добавлением в нее всего нескольких строк.
Следует отметить область, где механизму передачи сообщений нет альтернативы - это обслуживание функционального параллелизма. Если каждый узел выполняет свой собственный алгоритм, существенно отличающийся от того, что делает соседний процессор, а взаимодействие между ними имеет нерегулярный характер, то ничего другого, кроме механизма передачи сообщений, предложить невозможно.
29.Взаимодействие задач посредством MPI
MPI (Message Passing Interface) — интерфейс обмена сообщениями (информацией) между одновременно работающими вычислительными процессами. Он широко используется для создания параллельных программ для вычислительных систем с распределѐнной памятью (кластеров).
MPI - это стандарт на программный инструментарий для обеспечения связи между ветвями параллельного приложения.
MPI является наиболее распространѐнным стандартом интерфейса обмена данными в параллельном программировании, существуют его реализации для большого числа компьютерных платформ. Используется при разработке программ для кластеров и суперкомпьютеров. Основным средством коммуникации между процессами в MPI является передача сообщений друг другу.
Базовым механизмом связи между MPI процессами является передача и приѐм сообщений. Сообщение несѐт в себе передаваемые данные и информацию, позволяющую принимающей стороне осуществлять их выборочный приѐм:
отправитель — ранг (номер в группе) отправителя сообщения;
получатель — ранг получателя;
признак — может использоваться для разделения различных видов сообщений;
коммуникатор — код группы процессов.
Операции приѐма и передачи могут быть блокирующимися и не блокирующимися. Для не блокирующихся операций определены функции проверки готовности и ожидания выполнения операции.
Другим способом связи является удалѐнный доступ к памяти (RMA), позволяющий читать и изменять область памяти удалѐнного процесса. Локальный процесс может переносить область памяти удалѐнного процесса (внутри указанного процессами окна) в свою память и обратно, а также комбинировать данные, передаваемые в удалѐнный процесс с имеющимися в его памяти данными (например, путѐм суммирования). Все операции удалѐнного доступа к памяти не блокирующиеся, однако, до и после их выполнения необходимо вызывать блокирующиеся функции синхронизации.
MPI предоставляет программисту единый механизм взаимодействия ветвей внутри параллельного приложения независимо от машинной архитектуры (однопроцессорные / многопроцессорные с общей/раздельной памятью), взаимного расположения ветвей (на одном процессоре / на разных) и API операционной системы.
( API = "applications programmers interface" = "интерфейс разработчика приложений" )
Программа, использующая MPI, легче отлаживается (сужается простор для совершения стереотипных ошибок параллельного программирования) и быстрее переносится на другие платформы (в идеале, простой перекомпиляцией).
MPI – единственная библиотека передачи сообщений, которая может рассматриваться как стандарт. Она поддерживается фактически на всех высокопроизводительных компьютерах и локальных сетях. Мобильность – нет необходимости изменять исходный код при переносе приложения на другую платформу, которая поддерживает MPI. Производительность – реализация MPI от производителя должна быть способна использовать родные особенности аппаратных средств ЭВМ, чтобы оптимизировать производительность. Функциональные возможности – более чем 115 процедур. Доступность – доступны разнообразные коммерческие и открытые реализации.
MPI-программа представляет собой набор независимых процессов, каждый из которых выполняет свою собственную программу (не обязательно одну и ту же), написанную на языке C или FORTRAN. Появились реализации MPI для C++, однако разработчики стандарта MPI за них ответственности не несут. Процессы MPI-программы взаимодействуют друг с другом посредством вызова коммуникационных процедур. Как правило, каждый процесс выполняется в своем собственном адресном пространстве, однако допускается и режим разделения памяти. MPI не специфицирует модель выполнения процесса - это может быть как последовательный процесс, так и многопотоковый. MPI не предоставляет никаких средств для распределения процессов по вычислительным узлам и для запуска их на исполнение. Эти функции возлагаются либо на операционную систему, либо на программиста. В частности, на nCUBE2 используется стандартная команда xnc, а на кластерах - специальный командный файл (скрипт) mpirun, который предполагает, что исполнимые модули уже каким-то образом распределены по компьютерам кластера. Описываемый в данном методическом пособии стандарт MPI 1.1 не содержит механизмов динамического создания и уничтожения процессов во время выполнения программы. MPI не накладывает каких-либо ограничений на то, как процессы будут распределены по процессорам, в частности, возможен запуск MPI программы с несколькими процессами на обычной однопроцессорной системе.
30.Особенности интерфейса MPI и компоненты MPICH
Актуальность MPI обусловлена тем, что интерфейс позволяет скрыть от пользователя отображение логической структуры программы на аппаратные ресурсы и воспринимать сложную, возможно неоднородную среду, как единый вычислительный ресурс.
Message Passing Interface: спецификация библиотеки передачи сообщений, разработанная в качестве стандарта для параллельных вычислительных систем с распределенной памятью. Цель разработки MPI состоит в том, чтобы обеспечить широко используемый стандарт для написания программ в парадигме обмена сообщениями. Интерфейс устанавливает переносимый, эффективный, и гибкий стандарт для передачи сообщений.
Минимально в состав MPI входят: библиотека программирования (заголовочные и библиотечные файлы для языков Си, Си++ и Фортран) и загрузчик приложений. Дополнительно включаются: профилирующий вариант библиотеки (используется на стадии тестирования параллельного приложения для определения оптимальности распараллеливания); загрузчик с графическим и сетевым интерфейсом для X-Windows и проч. Минимальный набор функций прост в освоении и позволяет быстро написать надежно работающую программу. Использование же всей мощи MPI позволит получить быстро работающую программу – при сохранении надежности.
MPI – это изначально быстрый инструмент. Для повышения скорости в нем использу-ются приемы, о которых прикладные программисты зачастую просто не задумываются. Напри-мер, встроенная буферизация позволяет избежать задержек при отправке данных – управление в передающую ветвь возвращается немедленно, даже если ветвь-получатель еще не подготовилась к приему. MPI использует многопоточность (multi-threading), вынося большую часть своей работы в потоки (threads) с низким приоритетом. Буферизация и многопоточность сводят к ми-нимуму негативное влияние неизбежных простоев при пересылках на производительность прикладной программы. На передачу данных типа "один-всем" оптимизированные процедуры MPI затрачивают время, пропорциональное не числу участвующих ветвей, а логарифму этого числа и так далее... И все это скрупулезно отлажено и протестировано!
MPI скрывает от нас подробности реализации нижележащего транспортного уровня (разделяемая память, встроенная сеть или локальная сеть). Перенос программ отныне не требу-ет переписывания и повторной отладки. Незаменимое качество для программы, которой пред-стоит пользоваться широкому кругу людей. Следует учитывать и то обстоятельство, что уже появляются машины, на которых из средств межпрограммного взаимодействия есть только MPI – и ничего более.
Отладка. Перечисление, иллюстрации и способы избежания типовых ошибок, допускаемых при параллельном программировании - тема отдельной книги. Сразу следует оговориться, что панацеи от них пока не придумано - иначе о таковой тотчас стало бы общеизвестно. MPI ни от одной из типовых ошибок не страхует – но он уменьшает вероятность их совершить!
Функции работы с разделяемой памятью и с семафорами слишком атомарны, примитив-ны. Вероятность без ошибки реализовать с их помощью нужное программе действие стреми-тельно уменьшается с ростом количества инструкций; вероятность найти ошибку путем отлад-ки близка к нулю, потому что отладочное средство привносит задержку в выполнение одних ветвей, и тем самым позволяет нормально работать другим, (ветви перестают конкурировать за совместно используемые данные).
Программа, использующая MPI, легче отлаживается (сужается простор для совершения стереотипных ошибок параллельного программирования) и быстрее переносится на другие платформы (в идеале, простой перекомпиляцией).
1. MPI: основные понятия и определения, связанные с интерфейсом
1.1.Понятие параллельной программы
Под параллельной программой в рамках MPI понимается множество одновременно вы-полняемых процессов. Процессы могут выполняться на разных процессорах, но на одном процессоре могут располагаться и несколько процессов (в этом случае их исполнение осуще-ствляется в режиме разделения времени). В предельном случае для выполнения параллельной программы может использоваться один процессор — как правило, такой способ применяется для начальной проверки правильности параллельной программы.
Каждый процесс параллельной программы порождается на основе копии одного и того же программного кода (модель SPMP - single process, multiple data; or single program, multiple data). Данный программный код, представленный в виде исполняемой программы, должен быть доступен в момент запуска параллельной программы на всех используемых про-цессорах. Исходный программный код для исполняемой программы разрабатывается на алгоритмических языках C или Fortran с использованием той или иной реализации библиотеки MPI.
Количество процессов и число используемых процессоров определяется в момент запуска параллельной программы средствами среды исполнения MPI-программ и в ходе вычислений меняться не может (в стандарте MPI-2 предусматривается возможность динамического изме-нения количества процессов). Все процессы программы последовательно перенумерованы от 0 до p-1, где p есть общее количество процессов. Номер процесса именуется рангом процесса.
1.2.Операции передачи данных
Основу MPI составляют операции передачи сообщений. Среди предусмотренных в составе MPI функций различаются парные (point-to-point) операции между двумя процессами и коллективные (collective) коммуникационные действия для одновременного взаимодействия нескольких процессов.
Для выполнения парных операций могут использоваться разные режимы передачи, среди которых синхронный, блокирующий и др.
Как уже отмечалось ранее, стандарт MPI предусматривает необходимость реализации большинства основных коллективных операций передачи данных.
1.3. Понятие коммуникаторов
Процессы параллельной программы объединяются в группы. Под коммуникатором в MPI понимается специально создаваемый служебный объект, объединяющий в своем составе груп-пу процессов и ряд дополнительных параметров (контекст), используемых при выполнении операций передачи данных.
Как правило, парные операции передачи данных выполняются для процессов, принадле-жащих одному и тому же коммуникатору. Коллективные операции применяются одновре-менно для всех процессов коммуникатора. Как результат, указание используемого ком-муникатора является обязательным для операций передачи данных в MPI.
В ходе вычислений могут создаваться новые и удаляться существующие группы процессов и коммуникаторы. Один и тот же процесс может принадлежать разным группам и комму-никаторам. Все имеющиеся в параллельной программе процессы входят в состав создаваемого по умолчанию коммуникатора с идентификатором MPI_COMM_WORLD.
При необходимости передачи данных между процессами из разных групп необходимо создавать глобальный коммуникатор
(intercommunicator).
1.4. Типы данных
При выполнении операций передачи сообщений для указания передаваемых или получае-мых данных в функциях MPI необходимо указывать тип пересылаемых данных. MPI содержит большой набор базовых типов данных, во многом совпадающих с типами данных в алгоритми-ческих языках C и Fortran. Кроме того, в MPI имеются возможности для создания новых произ-водных типов данных для более точного и краткого описания содержимого пересылаемых со-общений.
Подробное рассмотрение возможностей MPI для работы с производными типами данных выходит за рамки данного описания.
1.5. Виртуальные топологии Как уже отмечалось ранее, парные операции передачи данных могут быть выполнены меж-ду любыми процессами одного и
того же коммуникатора, а в коллективной операции принимают участие все процессы коммуникатора. В этом плане, логическая топология линий связи между процессами имеет структуру полного графа (независимо от наличия реальных физических каналов связи между процессорами).
Вместе с этим (и это уже отмечалось в разделе 1.3), для изложения и последующего анализа ряда параллельных алгоритмов целесообразно логическое представление имеющейся комму-никационной сети в виде тех или иных топологий.
ВMPI имеется возможность представления множества процессов в виде решетки произ-вольной размерности. При этом, граничные процессы решеток могут быть объявлены соседни-ми и, тем самым, на основе решеток могут быть определены структуры типа тор.
Кроме того, в MPI имеются средства и для формирования логических (виртуальных) топо-логий любого требуемого типа.
Впоследующем тексте при рассмотрении MPI:
•описание функций и все приводимые примеры программ будут представлены на алго-ритмическом языке C;
•основное изложение возможностей MPI будет ориентировано на стандарт версии 1.2 (MPI-1).
С одной стороны, MPI достаточно сложен — в стандарте MPI предусматривается наличие более 125 функций. С другой стороны, структура MPI является тщательно продуманной — раз-работка параллельных программ может быть начата уже после рассмотрения всего лишь 6 функций MPI. Все дополнительные возможности MPI могут осваиваться по мере роста сложности разрабатываемых алгоритмов и программ.
MPICH — самая известная реализация MPI, созданная в Арагонской национальной лаборатории (США). Существуют версии этой библиотеки для всех популярных операционных систем. К тому же, она бесплатна. Перечисленные факторы делают MPICH идеальным вариантом для того, чтобы начать практическое освоение MPI.
В данной статье речь пойдѐт об MPICH2. Двойка в названии — это не версия программного обеспечения, а номер того стандарта MPI, который реализован в библиотеке. MPICH2 соответствует стандарту MPI 2.0, отсюда и название. Здесь уместно привести цитату с официального сайта (в моѐм переводе):
MPICH2 — это быстродействующая и широко портируемая реализация стандрта MPI (реализованы оба стандарта MPI-1 и MPI- 2). Цели создания MPICH2 следующие:
1.Предоставить реализацию MPI, которая эффективно поддерживает различные вычислительные и коммуникационные платформы, включая общедоступные кластеры (настольные системы, системы с общей памятью, многоядерные архитектуры), высокоскоростные сети (Ethernet 10 ГБит/с, InfiniBand, Myrinet, Quadrics) и эксклюзивные вычислительные системы (Blue
Gene, Cray, SiCortex).
2.Сделать возможными передовые исследования технологии MPI с помощью легко расширяемой модульной структуры для создания производных реализаций.
В дальнейшем будем предполагать, что у вас имеется сеть из нескольких домашних компьютеров (будем называть их вычислительными узлами), работающих под управлением Windows. Можно даже настроить систему на двух ноутбуках, соединѐнных беспроводной сетью. Если у вас нет нескольких компьютеров, объединѐнных в сеть, — не отчаивайтесь. Для учебных целей можно запускать все вычислительные процессы и на одном компьютере. Если компьютер одноядерный, то, естественно, прироста быстродействия вы не получите, — только замедление.
В качестве среды разработки будем использовать Visual Studio 2008 или 2010 (возможно использование бесплатной версии Express). Для удобства изложения созданную вами программу, использующую MPI, и предназначенную для запуска на нескольких вычислительных узлах, будем называть MPI-программой.
Принципы работы MPICH
Чтобы прояснить остальные разделы статьи, я решил начать изложение не с инструкций по установке MPICH, а с принципов еѐ работы.
MPICH для Windows состоит из следующих компонентов:
Существует мнение, что smpd.exe — никакой не «менеджер процессов», а просто средство для их запуска. Это мнение обосновано тем, что полноценный менеджер процессов должен составлять расписание запуска процессов, осуществлять мониторинг и балансировку загрузки узлов.
В этой статье я придерживаюсь терминологии Арагонской лаборатории, которая называет smpd.exe, как «Process manager service for MPICH2 applications»
Менеджер процессов smpd.exe, который представляет собой системную службу (сервисное приложение). Менеджер процессов ведѐт список вычислительных узлов системы, и запускает на этих узлах MPI-программы, предоставляя им необходимую информацию для работы и обмена сообщениями.
Заголовочные файлы (.h) и библиотеки стадии компиляции (.lib), необходимые для разработки MPI-программ.
Библиотеки времени выполнения (.dll), необходимые для работы MPI-программ.
Дополнительные утилиты (.exe), необходимые для настройки MPICH и запуска MPI-программ.
Все компоненты, кроме библиотек времени выполнения, устанавливаются по умолчанию в папку C:\Program Files\MPICH2; dllбиблиотеки устанавливаются в C:\Windows\System32.
Менеджер процессов является основным компонентом, который должен быть установлен и настроен на всех компьютерах сети (библиотеки времени выполнения можно, в крайнем случае, копировать вместе с MPI-программой). Остальные файлы требуются для разработки MPI-программ и настройки некоторого «головного» компьютера, с которого будет производиться их запуск.
Менеджер работает в фоновом режиме и ждѐт запросов к нему из сети со стороны «головного» менеджера процессов (по умолчанию используется сетевой порт 8676). Чтобы как-то обезопасить себя от хакеров и вирусов, менеджер требует пароль при обращении к нему. Когда один менеджер процессов обращается к другому менеджеру процессов, он передаѐт ему свой пароль. Отсюда следует, что нужно указывать один и тот же пароль при установке MPICH на компьютеры сети.
В современных кластерах сеть передачи данных обычно отделяется от управляющей сети Запуск MPI-программы производится следующим образом (смотрите рисунок 1):
1.Пользователь с помощью программы Mpirun (или Mpiexec, при использовании MPICH2 под Windows) указывает имя исполняемого файла MPI-программы и требуемое число процессов. Кроме того, можно указать имя пользователя и пароль: процессы MPI-программы будут запускаться от имени этого пользователя.
2.Mpirun передаѐт сведения о запуске локальному менеджеру процессов, у которого имеется список доступных вычислительных узлов.
3.Менеджер процессов обращается к вычислительным узлам по списку, передавая запущенным на них менеджерам процессов указания по запуску MPI-программы.
4.Менеджеры процессов запускают на вычислительных узлах несколько копий MPI-программы (возможно, по несколько копий на каждом узле), передавая программам необходимую информацию для связи друг с другом.
Очень важным моментом здесь является то, что перед запуском MPI-программа не копируется автоматически на вычисли-
тельные узлы кластера. Вместо этого менеджер процессов передаѐт узлам путь к исполняемому файлу программы точно в том виде, в котором пользователь указал этот путь программе Mpirun. Это означает, что если вы, например, запускаете программу C:\proga.exe, то все менеджеры процессов на вычислительных узлах будут пытаться запустить файл C:\proga.exe. Если хотя бы на одном из узлов такого файла не окажется, произойдѐт ошибка запуска MPI-программы.
Чтобы каждый раз не копировать вручную программу и все необходимые для еѐ работы файлы на вычислительные узлы кластера, обычно используют общий сетевой ресурс. В этом случае пользователь копирует программу и дополнительные файлы на сетевой ресурс, видимый всеми узлами кластера, и указывает путь к файлу программы на этом ресурсе. Дополнительным удобством такого подхода является то, что при наличии возможности записи на общий сетевой ресурс запущенные копии программы могут записывать туда результаты своей работы.
Работа MPI-программы происходит следующим образом:
1.Программа запускается и инициализирует библиотеку времени выполнения MPICH путѐм вызова функции MPI_Init.
2.Библиотека получает от менеджера процессов информацию о количестве и местоположении других процессов программы, и устанавливает с ними связь.
3. После этого запущенные копии программы могут обмениваться друг с другом информацией посредством библиотеки MPICH. С точки зрения операционной системы библиотека является частью программы (работает в том же процессе), поэтому можно считать, что запущенные копии MPI-программы обмениваются данными напрямую друг с другом, как любые другие приложения, передающие данные по сети.
4.Консольный ввод-вывод всех процессов MPI-программы перенаправляется на консоль, на которой запущена Mpirun. Насколько я понимаю, перенаправлением ввода-вывода занимаются менеджеры процессов, так как именно они запустили копии MPI-программы, и поэтому могут получить доступ к потокам ввода-вывода программ.
5.Перед завершением все процессы вызывают функцию MPI_Finalize, которая корректно завершает передачу и приѐм всех сообщений, и отключает MPICH.
Все описанные выше принципы действуют, даже если вы запускаете MPI-программу на одном компьютере.
31.Компьютерные кластеры
Кластер — группа компьютеров, объединѐнных высокоскоростными каналами связи и представляющая с точки зрения пользователя единый аппаратный ресурс.
Один из первых архитекторов кластерной технологии Грегори Пфистер дал кластеру следующее определение: «Кластер — это разновидность параллельной или распределѐнной системы, которая:
•состоит из нескольких связанных между собой компьютеров;
•используется как единый, унифицированный компьютерный ресурс».
Преимущества кластеризации
•Абсолютная масштабируемость. Возможно создание больших кластеров, превосходящих по вычислительной мощности даже самые производительные одиночные ВМ. Кластер в состоянии содержать десятки узлов, каждый из которых представляет собой мультипроцессор.
•Наращиваемая масштабируемость. Кластер строится так, что его можно наращивать, добавляя новые узлы небольшими порциями. Таким образом, пользователь может начать с умеренной системы, расширяя ее по мере необходимости.
•Высокий коэффициент готовности. Поскольку каждый узел кластера — самостоятельная ВМ или ВС, отказ одного из узлов не приводит к потере работоспособности кластера. Во многих системах отказоустойчивость автоматически поддерживается программным обеспечением.
•Превосходное соотношение цена/производительность. Кластер любой производительности можно создать, соединяя стандартные «строительные блоки», при этом его стоимость будет ниже, чем у одиночной ВМ с эквивалентной вычислительной мощностью.
32.Классы кластеров Обычно различают следующие основные виды кластеров:
•отказоустойчивые кластеры (High-availability clusters, HA, кластеры высокой доступности)
•кластеры с балансировкой нагрузки (Load balancing clusters)
•вычислительныекластеры (High perfomance computing clusters)
•grid-системы.
Классификация кластеров
1)Кластеры высокой доступности
2)Кластеры распределения нагрузки
3)Вычислительные кластеры
4)Системы распределенных вычислений (grid)
5)Кластер серверов, организуемых программно
33.Наиболее популярные типы кластеров (системы высокой надежности, системы для высокопроизводительных вычислений, многопоточные системы)
Системы выской надежности Кластеры высокой доступности
Обозначаются аббревиатурой HA (англ. High Availability — высокая доступность). Создаются для обеспечения высокой доступности сервиса, предоставляемого кластером. Избыточное число узлов, входящих в кластер, гарантирует предоставление сервиса в случае отказа одного или нескольких серверов. Типичное число узлов — два, это минимальное количество, приводящее к повышению доступности. Создано множество программных решений для построения такого рода кластеров.
Отказоустойчивые кластеры и системы вообще строятся по трем основным принципам:
•с холодным резервом или активный/пассивный. Активный узел выполняет запросы, а пассивный ждет его отказа и включается в работу, когда таковой произойдет. Пример — резервные сетевые соединения, в частности, Алгоритм связующего дерева. Например связка DRBD и HeartBeat.
•с горячим резервом или активный/активный. Все узлы выполняют запросы, в случае отказа одного нагрузка перераспределяется между оставшимися. То есть кластер распределения нагрузки с поддержкой перераспределения запросов при отказе. Примеры — практически все кластерные технологии, например, Microsoft Cluster Server. OpenSource проект
OpenMosix.
•с модульной избыточностью. Применяется только в случае, когда простой системы совершенно недопустим. Все узлы одновременно выполняют один и тот же запрос (либо части его, но так, что результат достижим и при отказе любого узла), из результатов берется любой. Необходимо гарантировать, что результаты разных узлов всегда будут одинаковы (либо различия гарантированно не повлияют на дальнейшую работу). Примеры — RAID и Triple modular redundancy.
Конкретная технология может сочетать данные принципы в любой комбинации. Например, Linux-HA поддерживает режим обоюдной поглощающей конфигурации (англ. takeover), в котором критические запросы выполняются всеми узлами вместе, прочие же равномерно распределяются между ними.
Системы для высокопроизводительных вычислений
Вычислительные кластеры (Highperfomancecomputingclusters)
Кластеры используются в вычислительных целях, в частности в научных исследованиях. Для вычислительных кластеров существенными показателями являются высокая производительность процессора в операциях над числами с плавающей точкой (flops) и низкая латентность объединяющей сети, и менее существенными — скорость операций ввода-вывода, которая в большей степени важна для баз данных и web-сервисов. Вычислительные кластеры позволяют уменьшить время расчетов, по сравнению с одиночным компьютером, разбивая задание на параллельно выполняющиеся ветки, которые обмениваются данными по связывающей сети. Одна из типичных конфигураций — набор компьютеров, собранных из общедоступных компонентов, с установленной на них операционной системой Linux, и связанных сетью Ethernet, Myrinet, InfiniBand или другими относительно недорогими сетями. Такую систему принято называть кластером Beowulf. Специально выделяют высокопроизводительные кластеры (Обозначаются англ. аббревиатурой HPC Cluster — High-performance computing cluster). Список самых мощных высокопроизводительных компьютеров (также может обозначаться англ. аббревиатурой HPC) можно найти в мировом рейтинге TOP500. В России ведется рейтинг самых мощных компьютеров СНГ.
Многопоточные системы
Многопоточные системы используются для обеспечения единого интерфейса к ряду ресурсов, которые могут со временем произвольно наращиваться (или сокращаться). Типичным примером может служить группа web-серверов.

34.Основные топологические архитектуры для построения кластеров Архитектура кластерной системы (способ соединения процессоров друг с другом) в большей степени определяет ее
производительность, чем тип используемых в ней процессоров. Критическим параметром, влияющим на величину производительности такой системы, является расстояние между процессорами. Так, соединив вместе 10 персональных компьютеров, мы получим систему для проведения высокопроизводительных вычислений. Проблема, однако, будет состоять в поиске наиболее эффективного способа соединения стандартных средств друг с другом, поскольку при увеличении производительности каждого процессора в 10 раз производительность системы в целом в 10 раз не увеличится.
Рассмотрим для примера задачу построения симметричной 16процессорной системы, в которой все процессоры были бы равноправны. Наиболее естественным представляется соединение в виде плоской решетки, где внешние концы используются для подсоединения внешних устройств. При таком типе соединения максимальное расстояние между процессорами окажется равным 6 (количество связей между процессорами, отделяющих самый ближний процессор от самого дальнего). Теория же показывает, что если в системе максимальное расстояние между процессорами больше 4, то такая система не может работать
эффективно. Поэтому при соединении 16 процессоров друг с другом плоская схема является нецелесообразной. Для получения более компактной конфигурации необходимо решить задачу о нахождении фигуры, имеющей максимальный объем при минимальной площади поверхности. В трехмерном пространстве таким свойством обладает шар. Но поскольку нам необходимо построить узловую систему, вместо шара приходится использовать куб (если число процессоров равно 8) или гиперкуб, если число процессоров больше 8. Размерность гиперкуба будет определяться в зависимости от числа процессоров, которые необходимо соединить. Так, для соединения 16 процессоров потребуется четырехмерный гиперкуб. Для его построения следует взять обычный трехмерный куб, сдвинуть в нужном направлении и, соединив вершины, получить гиперкуб размером 4.
Архитектура гиперкуба является второй по эффективности, но самой наглядной. Используются и другие топологии сетей связи: трехмерный тор, "кольцо", "звезда" и другие.
Наиболее эффективной является архитектура с топологией "толстого дерева" (fat-tree). Архитектура "fat-tree" (hypertree) была предложена Лейзерсоном (Charles E. Leiserson) в 1985 году. Процессоры локализованы в листьях дерева, в то время как внутренние узлы дерева скомпонованы во внутреннюю сеть. Поддеревья могут общаться между собой, не затрагивая более высоких уровней сети.
Поскольку способ соединения процессоров друг с другом больше влияет на производительность кластера, чем тип используемых в ней процессоров, то может оказаться более целесообразным создать систему из большего числа дешевых компьютеров, чем из меньшего числа дорогих. В кластерах, как правило, используются операционные системы, стандартные для рабочих станций, чаще всего свободно распространяемые (Linux, FreeBSD), вместе со специальными средствами поддержки параллельного программирования и балансировки нагрузки. При работе с кластерами, так же, как и с MPPсистемами, используют так называемую Massive Passing Programming Paradigm – парадигму программирования с передачей данных (чаще всего – MPI). Умеренная цена подобных систем оборачивается большими накладными расходами на взаимодействие параллельных процессов между собой, что сильно сужает потенциальный класс решаемых задач.
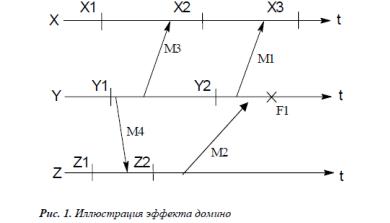
35.Задачи, решаемые системами управления кластерами высокопроизводительных вычислений
Балансировка нагрузки Система управления может отправлять задачи на выполнение на конкретные узлы в кластере не просто по мере их получения
от пользователей, а, таким образом, чтобы каждый узел, входящий в состав кластера, выполнял работу пропорционально своей мощности и не простаивал. Балансировка может быть статической, до запуска задачи, и динамической, уже во время работы задачи.
Статическая балансировка привлекательна тем, что не требует дополнительных затрат во время выполнения задачи, однако динамическая может быть более эффективна в случае изменения физической структуры кластера, добавления или удаления узлов во время работы. Рассмотрим оба эти способа.
Для того чтобы эффективно производить статическую балансировку нагрузки, необходимо иметь некоторую информацию о каждой задаче, например, необходимое количество узлов, оперативной и дисковой памяти, предельное время работы. Вся эта информация является списком ресурсов, необходимых задаче, и описывается в файле задания. Используя указанные ресурсы, система способна выбирать из очереди готовых к выполнению задач наиболее подходящие в конкретной ситуации. Существует множество решений задачи статического распределения, которая для большинства вариантов принадлежит классу NP-полных задач, за исключением некоторых очень простых случаев [13, 32]. В целом следует сказать, что наиболее логичным способом распределения задач является минимизация количества простаивающих машин, в таком случае кластер используется наиболее эффективно.
Динамическая балансировка позволяет перераспределять уже запущенные задачи. В таком случае используется миграция процессов. Миграция процессов позволяет перемещать процесс с одной машины на другую без необходимости перезапуска процесса с самого начала. Миграция процессов привлекательна тем, что поступление задач и ресурсов от пользователей не всегда известно заранее. Миграция в таком случае дает системе еще один шанс правильно распределить выполняемые задачи [3]. Миграция обычно используется вместе с контрольными точками, образ процесса сохраняется на одной машине и затем восстанавливается на другой. Более подробно мы расскажем о контрольных точках в разделе 2.3 и в разделе 4.2 при описании системы Condor.
Если система разрешает пользователю для своей задачи указать используемые соответствовать действительности. Система должна контролировать соответствие между реальным использованием ресурсов и теми данными, которые указал для данной задачи пользователь, и в случае несоответствия завершить задачу или произвести заранее предусмотренное для такой ситуации действие. По нашему мнению, чем больше будет такой контроль, тем больше гарантий безопасности для системы и ее пользователей. Возможность ограничения ресурсов определяется операционной системой, использующейся на узлах кластера, и архитектурой самой системы управления.
Защита от сбоев Как мы сказали выше – система управления может рассматриваться как распределенная операционная система для кластера.
Основным принципом любой распределенной системы является иллюзия целостности, когда совокупность независимых компьютеров представляется пользователю единой вычислительной машиной. Пользователь кластера отправляет задания на известный сетевой адрес. Этот адрес однозначно определяет некоторый узел в составе кластера, называемый управляющим узлом. Кластеры очень часто создаются с выделенным управляющим узлом, на котором не производятся вычисления, а работает основная часть системы управления: подсистема очередей, система сбора и обработки различной информации. Управляющий узел также может включать в себя файловый сервер и служить шлюзом, ограничивающим узлы кластера от внешней сети.
Во время работы кластера один из узлов может отказать. В таком случае все вычисления, производимые на данном узле, теряются. Система должна, так или иначе, реагировать на такие отказы аппаратуры и, в случае необходимости перезапускать остановленные задачи.
В простейшем случае каждая программа может быть запущена заново. Для программ, которые выполняются долгое время, перезапуск означает потерю большого количества вычислений и, следовательно, времени. Для сохранения текущего состояния программы, и затем ее восстановления используется механизм контрольных точек. В случае сбоя теряются только те вычисления, которые были произведены с момента последней контрольной точки. Контрольная точка процесса представляет собой образ адресного пространства процесса.
Существует два метода создания контрольных точек: последовательное и неблокирующее сохранение. Последовательное сохранение сокращает объем необходимых для сохранения данных. Сохраняются только те страницы памяти, которые были изменены с момента последнего сохранения. Неблокирующее сохранение позволяет процессу продолжать свое выполнение во время сохранения. Страницы памяти процесса блокируются на запись, если же процесс пытается изменить страницу, она копируется, и процесс сохранения продолжается уже с копией страницы. Сохранение образа процесса может существенно затормозить работу машины, выполняющей такое сохранение. Помимо
вычислительных ресурсов процесс создания контрольных точек требует дополнительного дискового пространства. Для