

- •Table of Contents
- •About the Author
- •About the Technical Reviewer
- •Acknowledgments
- •Software Entropy
- •Clean Code
- •C++11: The Beginning of a New Era
- •Who This Book Is For
- •Conventions Used in This Book
- •Sidebars
- •Notes, Tips, and Warnings
- •Code Samples
- •Coding Style
- •C++ Core Guidelines
- •Companion Website and Source Code Repository
- •UML Diagrams
- •The Need for Testing
- •Unit Tests
- •What About QA?
- •Rules for Good Unit Tests
- •Test Code Quality
- •Unit Test Naming
- •Unit Test Independence
- •One Assertion per Test
- •Independent Initialization of Unit Test Environments
- •Exclude Getters and Setters
- •Exclude Third-Party Code
- •Exclude External Systems
- •What Do We Do with the Database?
- •Don’t Mix Test Code with Production Code
- •Tests Must Run Fast
- •How Do You Find a Test’s Input Data?
- •Equivalence Partitioning
- •Boundary Value Analysis
- •Test Doubles (Fake Objects)
- •What Is a Principle?
- •KISS
- •YAGNI
- •It’s About Knowledge!
- •Building Abstractions Is Sometimes Hard
- •Information Hiding
- •Strong Cohesion
- •Loose Coupling
- •Be Careful with Optimizations
- •Principle of Least Astonishment (PLA)
- •The Boy Scout Rule
- •Collective Code Ownership
- •Good Names
- •Names Should Be Self-Explanatory
- •Use Names from the Domain
- •Choose Names at an Appropriate Level of Abstraction
- •Avoid Redundancy When Choosing a Name
- •Avoid Cryptic Abbreviations
- •Avoid Hungarian Notation and Prefixes
- •Avoid Using the Same Name for Different Purposes
- •Comments
- •Let the Code Tell the Story
- •Do Not Comment Obvious Things
- •Don’t Disable Code with Comments
- •Don’t Write Block Comments
- •Don’t Use Comments to Substitute Version Control
- •The Rare Cases Where Comments Are Useful
- •Documentation Generation from Source Code
- •Functions
- •One Thing, No More!
- •Let Them Be Small
- •“But the Call Time Overhead!”
- •Function Naming
- •Use Intention-Revealing Names
- •Parameters and Return Values
- •Avoid Flag Parameters
- •Avoid Output Parameters
- •Don’t Pass or Return 0 (NULL, nullptr)
- •Strategies for Avoiding Regular Pointers
- •Choose simple object construction on the stack instead of on the heap
- •In a function’s argument list, use (const) references instead of pointers
- •If it is inevitable to deal with a pointer to a resource, use a smart one
- •If an API returns a raw pointer...
- •The Power of const Correctness
- •About Old C-Style in C++ Projects
- •Choose C++ Strings and Streams over Old C-Style char*
- •Use C++ Casts Instead of Old C-Style Casts
- •Avoid Macros
- •Managing Resources
- •Resource Acquisition Is Initialization (RAII)
- •Smart Pointers
- •Unique Ownership with std::unique_ptr<T>
- •Shared Ownership with std::shared_ptr<T>
- •No Ownership, but Secure Access with std::weak_ptr<T>
- •Atomic Smart Pointers
- •Avoid Explicit New and Delete
- •Managing Proprietary Resources
- •We Like to Move It
- •What Are Move Semantics?
- •The Matter with Those lvalues and rvalues
- •rvalue References
- •Don’t Enforce Move Everywhere
- •The Rule of Zero
- •The Compiler Is Your Colleague
- •Automatic Type Deduction
- •Computations During Compile Time
- •Variable Templates
- •Don’t Allow Undefined Behavior
- •Type-Rich Programming
- •Know Your Libraries
- •Take Advantage of <algorithm>
- •Easier Parallelization of Algorithms Since C++17
- •Sorting and Output of a Container
- •More Convenience with Ranges
- •Non-Owning Ranges with Views
- •Comparing Two Sequences
- •Take Advantage of Boost
- •More Libraries That You Should Know About
- •Proper Exception and Error Handling
- •Prevention Is Better Than Aftercare
- •No Exception Safety
- •Basic Exception Safety
- •Strong Exception Safety
- •The No-Throw Guarantee
- •An Exception Is an Exception, Literally!
- •If You Can’t Recover, Get Out Quickly
- •Define User-Specific Exception Types
- •Throw by Value, Catch by const Reference
- •Pay Attention to the Correct Order of Catch Clauses
- •Interface Design
- •Attributes
- •noreturn (since C++11)
- •deprecated (since C++14)
- •nodiscard (since C++17)
- •maybe_unused (since C++17)
- •Concepts: Requirements for Template Arguments
- •The Basics of Modularization
- •Criteria for Finding Modules
- •Focus on the Domain of Your Software
- •Abstraction
- •Choose a Hierarchical Decomposition
- •Single Responsibility Principle (SRP)
- •Single Level of Abstraction (SLA)
- •The Whole Enchilada
- •Object-Orientation
- •Object-Oriented Thinking
- •Principles for Good Class Design
- •Keep Classes Small
- •Open-Closed Principle (OCP)
- •A Short Comparison of Type Erasure Techniques
- •Liskov Substitution Principle (LSP)
- •The Square-Rectangle Dilemma
- •Favor Composition over Inheritance
- •Interface Segregation Principle (ISP)
- •Acyclic Dependency Principle
- •Dependency Inversion Principle (DIP)
- •Don’t Talk to Strangers (The Law of Demeter)
- •Avoid Anemic Classes
- •Tell, Don’t Ask!
- •Avoid Static Class Members
- •Modules
- •The Drawbacks of #include
- •Three Options for Using Modules
- •Include Translation
- •Header Importation
- •Module Importation
- •Separating Interface and Implementation
- •The Impact of Modules
- •What Is Functional Programming?
- •What Is a Function?
- •Pure vs Impure Functions
- •Functional Programming in Modern C++
- •Functional Programming with C++ Templates
- •Function-Like Objects (Functors)
- •Generator
- •Unary Function
- •Predicate
- •Binary Functors
- •Binders and Function Wrappers
- •Lambda Expressions
- •Generic Lambda Expressions (C++14)
- •Lambda Templates (C++20)
- •Higher-Order Functions
- •Map, Filter, and Reduce
- •Filter
- •Reduce (Fold)
- •Fold Expressions in C++17
- •Pipelining with Range Adaptors (C++20)
- •Clean Code in Functional Programming
- •The Drawbacks of Plain Old Unit Testing (POUT)
- •Test-Driven Development as a Game Changer
- •The Workflow of TDD
- •TDD by Example: The Roman Numerals Code Kata
- •Preparations
- •The First Test
- •The Second Test
- •The Third Test and the Tidying Afterward
- •More Sophisticated Tests with a Custom Assertion
- •It’s Time to Clean Up Again
- •Approaching the Finish Line
- •Done!
- •The Advantages of TDD
- •When We Should Not Use TDD
- •TDD Is Not a Replacement for Code Reviews
- •Design Principles vs Design Patterns
- •Some Patterns and When to Use Them
- •Dependency Injection (DI)
- •The Singleton Anti-Pattern
- •Dependency Injection to the Rescue
- •Adapter
- •Strategy
- •Command
- •Command Processor
- •Composite
- •Observer
- •Factories
- •Simple Factory
- •Facade
- •The Money Class
- •Special Case Object (Null Object)
- •What Is an Idiom?
- •Some Useful C++ Idioms
- •The Power of Immutability
- •Substitution Failure Is Not an Error (SFINAE)
- •The Copy-and-Swap Idiom
- •Pointer to Implementation (PIMPL)
- •Structural Modeling
- •Component
- •Interface
- •Association
- •Generalization
- •Dependency
- •Template and Template Binding
- •Behavioral Modeling
- •Activity Diagram
- •Action
- •Control Flow Edge
- •Other Activity Nodes
- •Sequence Diagram
- •Lifeline
- •Message
- •State Diagram
- •State
- •Transitions
- •External Transitions
- •Internal Transitions
- •Trigger
- •Stereotypes
- •Bibliography
- •Index
Chapter 9 Design Patterns and Idioms
In practice, dependency injection frameworks are available as commercial and open source solutions.
Adapter
I’m sure the Adapter (Wrapper) is one of the most commonly used design patterns. The reason for this is that the adaptation of incompatible interfaces is certainly a case that’s often necessary in software development, such as when a module developed by another team has to be integrated, or when using third-party libraries.
Here is the mission statement of the Adapter pattern:
“Convert the interface of a class into another interface clients expect. Adapter lets classes work together that couldn’t otherwise because of incompatible interfaces.”
—Erich Gamma et al., Design Patterns [Gamma95]
Let’s further develop the example from the previous section about dependency injection. Let’s assume that we want to use BoostLog v2 (see www.boost.org) for logging purposes, but we want to keep a usage of this third-party library exchangeable with other logging approaches and technologies.
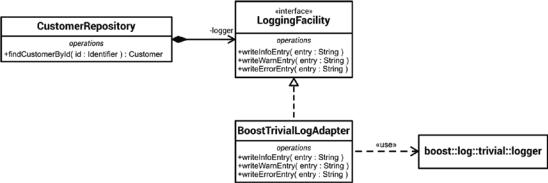
The solution is simple: we just have to provide another implementation of the LoggingFacility interface, which adapts the interface of BoostLog to the interface that we want, as depicted in Figure 9-6.
Figure 9-6. An adapter for a boost logging solution
394
Chapter 9 Design Patterns and Idioms
In source code, the additional implementation of the LoggingFacility interface
BoostTrivialLogAdapter is shown in Listing 9-13.
Listing 9-13. The Adapter for BoostLog Is Just Another Implementation of LoggingFacility
#include "LoggingFacility.h" #include <boost/log/trivial.hpp>
class BoostTrivialLogAdapter : public LoggingFacility { public:
void writeInfoEntry(std::string_view entry) override { BOOST_LOG_TRIVIAL(info) << entry;
}
void writeWarnEntry(std::string_view entry) override { BOOST_LOG_TRIVIAL(warn) << entry;
}
void writeErrorEntry(std::string_view entry) override { BOOST_LOG_TRIVIAL(error) << entry;
}
};
The advantages are obvious: through the Adapter pattern, there is now exactly one class in the entire software system that has a dependency to the third-party logging solution. This also means that the code is not contaminated with proprietary logging statements, like BOOST_LOG_TRIVIAL(). And because this Adapter class is just another implementation of the LoggingFacility interface, we can also use dependency injection (see the previous section) to inject instances—or just exactly the same instance—of this class into all client objects that want to use it.
Adapters can facilitate a broad range of adaptation and conversion possibilities for incompatible interfaces. This ranges from simple adaptations, such as operations names and data type conversions, right up to supporting an entirely different set of operations. In our case, a call of a member function with a string parameter is converted into a call of the insertion operator for streams.
395
Chapter 9 Design Patterns and Idioms
Interface adaptations are of course easier if the interfaces to be adapted are similar. If the interfaces are very different, an adapter can also become a very complex piece of code.
Strategy
If you remember the open-closed principle (OCP) described in Chapter 6 as a guideline for an extensible object-oriented design, the Strategy design pattern can be considered as the “celebrity gig” of this important principle. Here is the mission statement of this pattern:
“Define a family of algorithms, encapsulate each one, and make them interchangeable. Strategy lets the algorithm vary independently from clients that use it.”
—Erich Gamma et al., Design Patterns [Gamma95]
Doing tings in different ways is a common requirement in software design. Just think of sorting algorithms for lists. There are various sorting algorithms that have different characteristics regarding the time complexity (number of operations required) and the space complexity (additional required storage space in addition to the input list). Examples are Bubble-Sort, Quick-Sort, Merge-Sort, Insert-Sort, and Heap-Sort.
For instance, Bubble-Sort is the least complex one and it is very efficient regarding memory consumption, but also one of the slowest sorting algorithms. In contrast, Quick-Sort is a fast and efficient sorting algorithm that is easy to implement through its recursive structure and does not require additional memory, but it is very inefficient with presorted and inverted lists. With the help of the Strategy pattern, a simple exchange of the sorting algorithm can be implemented, for example, depending on the properties of the list to be sorted.
Let’s consider another example. Assume that we want to have a textual representation of an instance of a Customer class in an arbitrary business IT system. A stakeholder requirement states that the textual representation should be formatted in various output formats: as plain text, as XML (Extensible Markup Language), and as JSON (JavaScript Object Notation).
First of all, let’s introduce an abstraction for our various formatting strategies, the abstract class Formatter. See Listing 9-14.
396
Chapter 9 Design Patterns and Idioms
Listing 9-14. The Abstract Formatter Class Contains Everything That All Specific Formatter Classes Have in Common
#include <memory> #include <string>
#include <string_view>
class Formatter { public:
virtual ~Formatter() = default;
Formatter& withCustomerId(std::string_view customerId) { this->customerId = customerId;
return *this;
}
Formatter& withForename(std::string_view forename) { this->forename = forename;
return *this;
}
Formatter& withSurname(std::string_view surname) { this->surname = surname;
return *this;
}
Formatter& withStreet(std::string_view street) { this->street = street;
return *this;
}
Formatter& withZipCode(std::string_view zipCode) { this->zipCode = zipCode;
return *this;
}
Formatter& withCity(std::string_view city) { this->city = city;
return *this;
}
397
Chapter 9 Design Patterns and Idioms
virtual std::string format() const = 0; protected:
std::string customerId { "000000" }; std::string forename { "n/a" }; std::string surname { "n/a" }; std::string street { "n/a" }; std::string zipCode { "n/a" }; std::string city { "n/a" };
};
using FormatterPtr = std::unique_ptr<Formatter>;
The three specific formatters that provide the formatting styles that are requested by the stakeholders are shown in Listing 9-15.
Listing 9-15. The Three Specific Formatters Override the Pure Virtual format() Member Function of Formatter
#include "Formatter.h" #include <sstream>
class PlainTextFormatter : public Formatter { public:
std::string format() const override { std::stringstream formattedString { }; formattedString << "[" << customerId << "]: "
<<forename << " " << surname << ", "
<<street << ", " << zipCode << " "
<<city << ".";
return formattedString.str();
}
};
class XmlFormatter : public Formatter { public:
std::string format() const override { std::stringstream formattedString { }; formattedString <<
"<customer id=\"" << customerId << "\">\n" <<
398
Chapter 9 Design Patterns and Idioms
"<forename>" << forename << "</forename>\n" <<
"<surname>" << surname << "</surname>\n" <<
"<street>" << street << "</street>\n" <<
"<zipcode>" << zipCode << "</zipcode>\n" <<
"<city>" << city << "</city>\n" << "</customer>\n";
return formattedString.str();
}
};
class JsonFormatter : public Formatter { public:
std::string format() const override { std::stringstream formattedString { }; formattedString <<
"{\n" <<
"\"CustomerId : \"" << customerId << END_OF_PROPERTY <<
"\"Forename: \"" << forename << END_OF_PROPERTY <<
"\"Surname: \"" << surname << END_OF_PROPERTY <<
"\"Street: \"" << street << END_OF_PROPERTY <<
"\"ZIP code: \"" << zipCode << END_OF_PROPERTY <<
"\"City: \"" << city << "\"\n" <<
"}\n";
return formattedString.str();
}
private:
static constexpr const char* const END_OF_PROPERTY { "\",\n" };
};
As can be seen clearly here, the OCP is particularly well supported. As soon as a new output format is required, another specialization of the abstract class Formatter has to be implemented. Modifications to the already existing formatters are not required. See Listing 9-16.
399
Chapter 9 Design Patterns and Idioms
Listing 9-16. How the Passed-In Formatter Object Is Used Inside the Member Function getAsFormattedString()
#include "Address.h" #include "CustomerId.h" #include "Formatter.h"
class Customer { public:
// ...
std::string getAsFormattedString(Formatter& formatter) const { return formatter.
withCustomerId(customerId.toString()). withForename(forename). withSurname(surname). withStreet(address.getStreet()). withZipCode(address.getZipCodeAsString()). withCity(address.getCity()).
format();
}
// ...
private:
CustomerId customerId; std::string forename; std::string surname; Address address;
};
The Customer::getAsFormattedString() member function has a parameter that expects a non-const reference to a formatter object. This parameter can be used to control the format of the string that can be retrieved through this member function, or in other words, the member function Customer::getAsFormattedString() can be supplied with a formatting strategy.
Perhaps you’ve noticed the special design of the public interface of the Formatter with its numerous chained with...() member functions. Here also another design pattern has been used, which is called Fluent Interface. In object-oriented programming,
400
Chapter 9 Design Patterns and Idioms
a fluent interface is a style to design APIs in a way that the readability of the code is close to that of ordinary written prose. In Chapter 8, we saw such an interface. That chapter introduced a custom assertion (see the section entitled “More Sophisticated Tests with a Custom Assertion”) to write more elegant and better readable tests. In this case here, the trick is that every with...() member function is self-referential, that is, the new context for calling a member function on the formatter is equivalent to the previous context, unless when the final format() function is called.
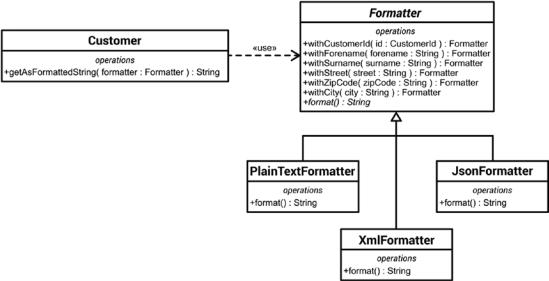
A graphical visualization of the class structure of our code example (a UML class diagram) is shown in Figure 9-7.
Figure 9-7. An abstract formatting strategy and its three concrete formatting strategies
As you can see, the Strategy pattern in this example ensures that the caller of the Cust omer::getAsFormattedString() member function can configure the output format as it wants. You want to support another output format? No problem: thanks to the excellent support of the open-closed principle, another concrete formatting strategy can be easily added. The other formatting strategies, as well as the Customer class, remain completely unaffected by this extension.
401