

Chapter 6 Modularization
Modules
The programming language C++, which was first released in 1985, is now about 35 years old. The foundation of C++ is still the procedural language C, which was released in 1972. To this day, C++ is backward compatible with C. This also means that C++ dragged along the legacy of C until today. Especially with the latest developments in the direction of modern C++—i.e. the standards C++11, C++14, C++17 and now C++20—the legacy of C appears more and more anachronistic and fits less and less with a modern programming style. Nowadays, the old-fashioned and weak #include system for implementing the modularity system in C++ is simply no longer appropriate.
Newer programming languages, like D or Rust, often have a built-in module system. Java was retrofitted with the module system Jigsaw with the release of version 9 in 2017. So, it was high time that C++ also got a module system: modules.
The Drawbacks of #include
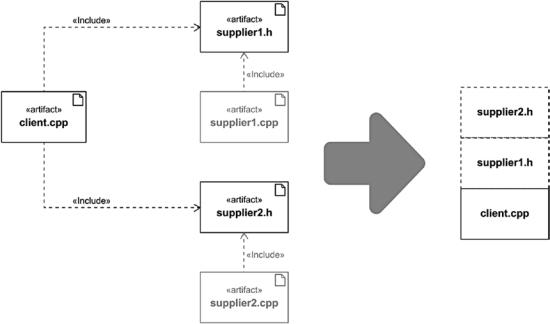
What are the disadvantages of the old #include system with header files? Well, these are relatively easy to understand when we think about what an #include really is. Every #include results in a simple text replacement by the preprocessor of the compiler, i.e. an #include directive leads to a simple copy-and-paste-operation of the contents of the included file, as depicted in Figure 6-14.
281
Chapter 6 Modularization
Figure 6-14. #include causes the file contents to be included in the including file
First of all, a major drawback to this approach is that the compilation time, especially in large projects, suffers greatly. If a header file is included in many translation units, the compiler must perform these copy-and-paste operations again and again. And the time - consuming part is not the text substitution alone, but mainly the subsequent generation of the so-called Abstract Syntax Tree (AST) by the compiler. Then it turns out that hundreds or even thousands of lines of code that have been included can be optimized away because they are not needed.
Furthermore, there are always two physical files, header and source file, to maintain the interface and the implementation of the same module. This basically results into consistency issues and many violations of the DRY principle.
But really unpleasant issues can be caused by multiple definitions of identical symbols and types in different header files, also known as ODR violations, and accidental code changes, e.g., redefinitions of symbols through macros. Imagine that two different header files, both defining a constant named PI in the global namespace, are included in the same translation unit. This requires that multiple inclusions of the same header file in the same translation unit be prevented through certain measures, e.g., with the help of an idiom called the include guard macro; otherwise, conflicts with multiple-defined symbols and types will occur.
282
Chapter 6 Modularization
ODR VIOLATION
ODR is the abbreviation for an important rule in C++ development: The One Definition Rule. The ODR is defined in the current ISO C++ Standard in Section 6.3. It states that no translation unit should contain more than one definition of any variable, function, class type, enumeration type, template, default argument for a parameter (for a function in a given scope), or default template argument.
A simple example of an ODR violation: A translation unit (.cpp file) includes two headers, both defining a class with an identical name. The compiler would terminate with an error message (e.g. “class type redefinition”) then.
Some violations of the ODR must be diagnosed by the compiler. For other violations of this rule, the compiler may remain silent. These possibly undetected ODR violations can lead to very subtle side effects and errors in the running program.
Modules totheRescue
With modules, which is one of the major new features of the C++20 standard, the separation of header files and implementation files, and thus many of the
aforementioned problems, as well as C-style macros and the C preprocessor, should be a thing of the past. Ultimately, the aim of modules is to significantly speed up the compilation of the software and to make it easier for the software designer to build distributable components.
A NOTE ABOUT FILE EXTENSIONS
In the following sections I will use *.mpp as the file extension for module files, and *.bmi as extension for so-called Built Module Interface (BMI) files. In fact, these file extensions are not standardized and may vary between compilers. For example, if you’re using the Microsoft Visual Studio C++ compiler, the module interface files end with *.ixx, and the BMI files generated by the compiler have the extension *.ifc. For Clang/LLVM compilers, the file extension for the module file is *.cppm and the BMI file ends with *pcm.
283
Chapter 6 Modularization
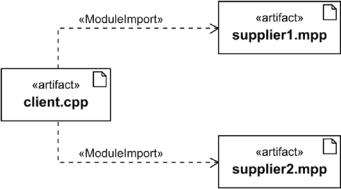
With modules, the situation presented in Figure 6-14 would change as depicted in Figure 6-15.
Figure 6-15. Module import
So, the solution is to do without the header files. Instead, one translation unit directly accesses the other translation units that it wants to use. Of course, this is not just easily done by throwing away the header file and instead using the implementation file directly as it is. You may have noticed while looking at Figure 6-15 that the file extension of the two artifacts to be imported in the client.cpp file has changed from *.cpp to *.mpp. Migration to modules is not for free, there are a lot of things that must be changed and taken into consideration. And sometimes you might not be able to do it for various reasons, e.g., if you are confronted with a third-party library that you cannot change.
Under theHood
Before we go a bit more in detail, let’s look at what happens “under the hood” when a C++ module is imported and what the basic difference to header file inclusion is.
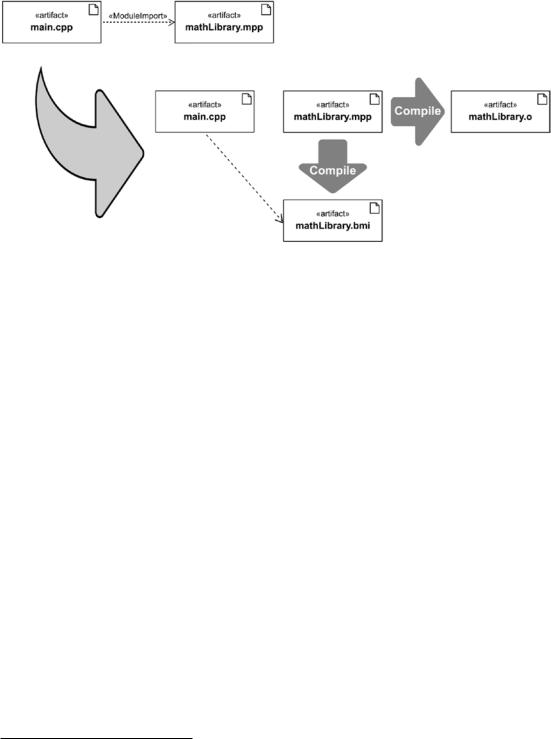
As depicted in Figure 6-16, a module import is of course no copy&paste operation as with the content of header files. If the compiler encounters a module file—in this case the file named mathLibrary.mpp—imported by a translation unit (main.cpp), the module file is first translated into a Built Module Interface (BMI) file and an object file.
284
Chapter 6 Modularization
Figure 6-16. A module file is first translated to a Binary Module Interface (BMI) file and an object file
The BMI is a file on the filesystem that contains the metadata for the module and describes the exported interface of mathLibrary.mpp. The compiler also produces an object file (mathLibrary.o), which is required by the Linker to link the module to produce an executable.
So basically, when using modules, there is an additional processing step that is required to generate the intermediate artifacts BMI file and object file. This is also an essential difference compared to using header files: When using header file inclusions, we do not have any additional time-consuming generation step. The big advantage, however, is that this step only has to be performed once, no matter how many translation units are importing the module. For example, using “import <iostream>” instead of “#include <iostream>” everywhere in your program avoids compiling the thousands of lines of code from the <iostream> header over and over again.
But this also means that we have a strict chronological order. Importing a module creates a succession, i.e. the compiler has to process the module first to obtain the BMI file, before compiling the translation units that imports the module.
One of the most important aspects of increasing build performance, especially when building large projects, is parallelization. Especially in a CI/CD1 environment where a continuous build chain is used to build the project very, very frequently, a single build has to run very fast. The development team needs fast feedback on whether the build
1Continuous Integration/Continuous Deployment
285