

Chapter 2 Build a Safety Net
instance, this can be done via email or with the help of an optical visualization (e.g., due to a flat screen on the wall, or a “traffic light” controlled by the build system) in a prominent place. If even just one test fails, under no circumstances should you release and ship the product!
How Do You Find a Test’s Input Data?
A piece of software can react very differently depending on the data used as input. If unit tests should add value to your project, you may come quickly to the question: How do I find all test cases that are necessary to ensure good fault detection?
On the one hand, you want to have a very high, ideally complete test coverage. On the other hand, economic aspects such as project duration and budget must also be kept in mind. That means that it is often not possible to perform extensive testing for each set of test data, especially when there is a large set of input combinations and you will end up with an almost infinite number of test cases.
To find a sufficient number of test cases, there are two central and important concepts in the quality assurance of software: equivalence partitioning, sometimes also called equivalence class partitioning (ECP), and the boundary value analysis.
Equivalence Partitioning
An equivalence partition, sometimes also called equivalence class, is a set or portion of input data for which a piece of software, both in a test environment and in its operational environment, should exhibit similar behavior. In other words, the behavior of a
system, component, class, or function/method is assumed to be the same, based on its specification.
The result of an equivalence partitioning can be used to derive test cases from these partitions of similar input data. In principle, the test cases are designed so that each partition is covered at least once.
As a specification-driven approach, the technique of equivalence partitioning is properly speaking a blackbox test design technique, i.e. the innards of the software to be tested are usually not known. However, it is also a very useful approach for whitebox testing techniques, i.e. unit testing and test-first approaches like TDD (see Chapter 8).
Let’s look at an example. Suppose we have to test a C++ class that calculates the interest on a bank account. According to the requirements specification, the account should exhibit the following behavior:
33
Chapter 2 Build a Safety Net
•\ |
The bank charges 4 percent penalty interest on overdrafts. |
•\ |
The bank offers 0.5 percent interest for the first 5,000 USD savings. |
•\ |
The bank offers 1 percent interest for the next 5,000 USD savings. |
•\ |
The bank offers 2 percent interest for the rest. |
•\ |
Interest is calculated on a daily basis. |
According to these specifications, the interest calculator’s API therefore has two parameters: the amount of money and, as interest is calculated on a daily basis, the number of days for which this amount is valid. This means we have to build equivalence classes for two input parameters.
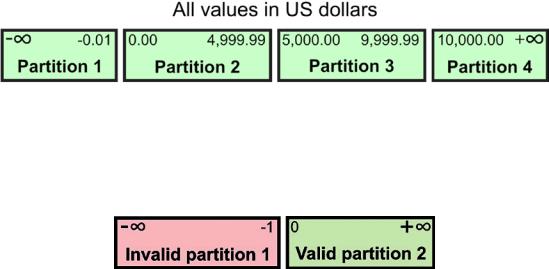
The equivalence partitioning for the amount of money is depicted in Figure 2-4.
Figure 2-4. The equivalence classes of the input parameter for the monetary amount
The equivalence classes for the validity period in days are a bit simpler and are depicted in Figure 2-5.
Figure 2-5. The equivalence classes of the input parameter for the number of days
What insights can we now derive from this for test case creation?
First of all, note that the input parameter for the monetary amount allows infinitely large positive or infinitely large negative values. In contrast, negative values for the number of days are not allowed.
This is the moment when it would be advisable to involve the business stakeholders and the domain experts.
First, it should be clarified whether the upper or lower limit for the amount of money is really infinite. The answer to this question not only affects the test cases, but also the
34
Chapter 2 Build a Safety Net
data type to be used for this parameter. Furthermore, the specification does not clarify what should happen if a negative value is used for the number of days. A negative value would be invalid, yes, but what kind of reaction should the interest calculator show?
Another question that could be answered by such an analysis would be, for example, whether the interest rates are really as fixed (constants) as the specification requires. Perhaps the interest rates are variable, and possibly also the amounts of money associated with them.
However, test cases can now be systematically derived from this analysis. The idea behind equivalence partitioning is that it is enough to pick only one value from each partition for testing. The hypothesis behind this technique is that if one condition/value in a partition passes a test, all others in the same partition will also pass. Likewise, if one condition/value in a partition fails, all other conditions/values in that partition will also fail. If there is more than one parameter, as in our case, appropriate combinations should be formed.
Boundary Value Analysis
“Bugs lurk in corners and congregate at boundaries.”
—Boris Beizer, Software Testing Techniques [Beizer90]
Many software bugs can be traced back to difficulties in the border areas of the equivalence classes, for example at the transition between two valid equivalence classes, between a valid and an invalid equivalence class, or due to an extreme value that was not taken into account. Therefore, building equivalence classes is complemented by boundary value analysis.
In the discipline of testing, boundary value analysis is a technique that finds the switchover points between equivalence classes and deals with extreme values. The result of such an analysis is useful to select the input values of a numerical parameter for the tests:
•\ |
Exactly on its minimum. |
•\ |
Just above the minimum. |
•\ |
A nominal value taken somewhere from the middle of the |
|
equivalence partition. |
•\ |
Just below the maximum. |
•\ |
Exactly on its maximum. |
35