

2.5. Выводы по главе 2
В настоящей главе приведен алгоритм перезапускаемого метода обобщенных минимальных невязок и выполнена его декомпозиция. Рассмотрен этап предобуславливания систем, приведены практические рекомендации к построению предобуславливателей. Проанализированы возможности составления параллельной модификации перезапускаемого метода обобщенных минимальных невязок.
Глава 3. Разработка параллельной модификации методаGmres
В предыдущей главе был рассмотрен последовательный алгоритм перезапускаемого GMRES, и выявлены наиболее трудоемкие его участки. В этой главе предлагается параллельная модификация изложенного алгоритма, которую предполагается использовать на высокопроизводительной вычислительной технике.
3.1. Основные классы параллельных вычислительных систем
Классифицируя современные параллельные системы, принадлежащие классу MIMDпо Флинну [10, 11], чаще всего основываются на анализе используемых в них способах организации оперативной памяти. На рис. 3.1 изображена классификация современных параллельных вычислительных систем с точки зрения организации оперативной памяти.

Рис. 3.1. Классификация современных параллельных вычислительных систем класса MIMDс точки зрения организации оперативной памяти
Для мультипроцессоров характерно использование централизованной памяти. Такой подход обеспечивает однородный доступ к памяти и служит основой для построения векторных суперкомпьютеров (PVP) и симметричных мультипроцессоров (SMP).
Общий доступ к данным может быть обеспечен и при физически распределенной памяти, при этом длительность доступа будет различаться для всех элементов памяти. Этот подход получил название неоднородный доступ к памяти (NUMA). Среди таких систем выделяют ряд подсистем, различающихся особенностями поддержания общей памяти на логическом уровне.
Мультикомпьютеры не обеспечивают общий доступ ко всей имеющейся в системе памяти. Этот подход используется при построении таких типов многопроцессорных вычислительных систем, как массивно-параллельные системы и кластеры. Последние получили широкое распространение в силу сравнительной дешевизны и легкости наращивания дополнительных мощностей [11, 12]. Традиционно в списке самых мощных высокопроизводительных вычислительных систем (TOP-500) лидируют системы именно с распределенной памятью. Такие системы позволяют относительно легко наращивать мощность добавлением новых вычислительных узлов, что обычно не требует больших финансовых затрат. Для достижения ожидаемого эффекта при использовании параллельных вычислительных систем необходимо придерживаться модели параллельного программирования, адекватной архитектуре вычислительной системы.
В данной работе разрабатываемая модификация перезапускаемого метода GMRESориентирована на вычислительные системы с распределенной памятью.
3.2. Классификация моделей параллельного программирования
Рассмотрим модели параллельного программирования с разных точек зрения.
С точки зрения доступа к разделяемым данным и синхронизации процессов. В настоящее время в области научно-технических вычислений превалируют три модели параллельного программирования: модель передачи сообщений, модель с общей памятью и модель параллелизма по данным [12]. На рис. 3.2 приведена общая схема такой классификации.
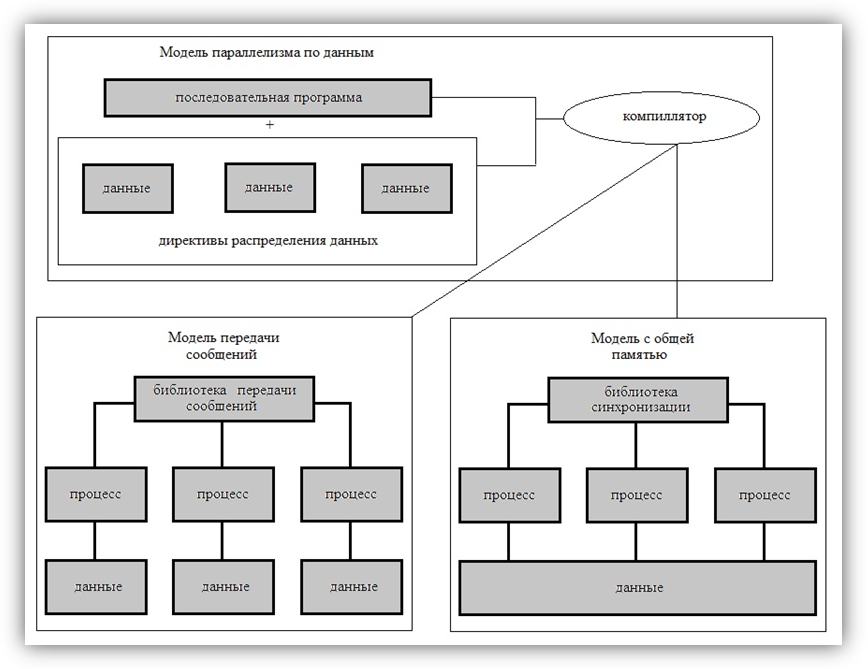
Рис.3.2. Классификация моделей параллельного программирования с точки зрения доступа к данным и синхронизации процессов
С точки зрения построения ветвей параллельного алгоритма.MPMD – модель вычислений (Multiple program – Multiple Data). Параллельная программа представляет собой совокупность автономных процессов, функционирующих под управлением своих собственных программ и взаимодействующих посредством стандартного набора библиотечных процедур для передачи и приема сообщений. SPMD – модель вычислений (Single program – Multiple Data). Все процессы исполняют в общем случае различные ветви одной и той же программы. Этот подход обусловлен тем обстоятельством, что задача может быть достаточно естественным образом разбита на подзадачи, решаемые по одному алгоритму. Исходные данные задачи распределяются по процессам (ветвям параллельного алгоритма), а алгоритм является одним и тем же во всех процессах, но действия этого алгоритма распределяются в соответствии с имеющимися в этих процессах данными. Распределение действий алгоритма заключается, например, в присвоении разных значений переменным одних и тех же циклов в разных ветвях, либо в исполнении в разных ветвях разного количества итераций одних и тех же циклов и т.п. Другими словами, процесс в каждой ветви следует различными путями выполнения на той же самой программе. На практике чаще всего встречается эта модель программирования.
С точки зрения размеров(по объему и времени)обрабатываемых параллельных блоков. Это методы крупнозернистого, среднезернистого и мелкозернистого распараллеливания [12, 13].
В модели передачи сообщенийкаждый процесс имеет собственное локальное адресное пространство. Обработка общих данных и синхронизация осуществляется посредством передачи сообщений. В рамках этой модели параллельного программирования реализуются обе подмодели с точки зрения построения ветвей параллельной программы:MPMD-модель вычислений иSPMD-модель вычислений. Для параллельных систем с передачей сообщений оптимальное соотношение между вычислениями и коммуникациями обеспечивают методы крупнозернистого распараллеливания, когда параллельные алгоритмы строятся из крупных и редко взаимодействующих блоков. Многие задачи линейной алгебры, задачи, решаемые сеточными методами, достаточно эффективно распараллеливаются крупнозернистыми методами [12]. Самой распространенной системой параллельного программирования, поддерживающей данную модель, являетсяMPI.
В модели с общей памятьюпроцессы разделяют общее адресное пространство. Так как нет ограничений на использование общих данных, то необходимо явно их специфицировать и упорядочить доступ к ним с помощью средств синхронизации. Поскольку в этой модели нет коммуникаций, как в модели передачи сообщений, сдерживающих скорость обработки данных, то эта модель в большей степени относится к среднезернистой модели программирования – в этой модели параллельные процессы могут строиться из небольших блоков. В рамках модели с общей памятью так же возможны обе подмодели с точки зрения построения ветвей параллельной программы. Обобщение и стандартизация моделей с общей памятью привели к созданию стандарта системы параллельного программированияOpenMP.
В модели параллелизма по даннымотсутствует понятие процесса и, как следствие, явная передача сообщений или явная синхронизация. В этой модели данные последовательной программы распределяются по узлам (процессорам) вычислительной системы. Последовательная программа преобразуется компилятором либо в модель передачи сообщений, либо в модель с общей памятью. В рамках данной модели параллельного программирования реализуются обе подмодели с точки зрения построения ветвей параллельной программы. Эта модель реализуется методом крупнозернистого распараллеливания [12].
В настоящей работе выбрана модель передачи сообщений, с точки зрения построения ветвей параллельной программы использована SPMD-модель методом крупнозернистого распараллеливания.