

Очереди
И, наконец, последним моментом, который мы рассмотрим в этой главе, будут очереди ‑ последняя базовая структура данных. В то время как извлечение элементов из стека происходит в порядке, обратном тому, в котором они вносились, в очереди элементы выбираются в порядке их добавления. Таким образом, очередь относится к структурам типа "первый пришел, первый вышел" (FIFO ‑ first in, first out). С очередью связаны две основные операции: постановка в очередь (т.е. добавление нового элемента в очередь) и снятие с очереди (т.е. извлечение из нее самого старого элемента).
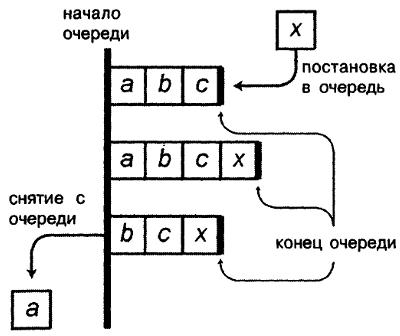
Рисунок 3.9. Постановка в очередь и снятие с очереди
Иногда эти операции ошибочно называют заталкиванием и выталкиванием. Это абсолютно неверные термины для очереди. Ближе к истине будут слова включение и исключение.
Как и стеки, очереди можно реализовать на основе односвязных списков или массивов. Тем не менее, в отличие от стеков, очень трудно добиться высокой эффективности реализации на основе массивов. К тому же организация очередей на базе связных списков ничуть не сложнее. Поэтому давайте для начала рассмотрим построение очереди на базе односвязных списков.
Очереди на основе односвязных списков
Фактически мы должны смоделировать обычную очередь в универмаге. С помощью списков это можно сделать очень легко, поскольку сами списки по своей сути являются очередями. Просто для моделирования очереди элементы должны добавляться с одной стороны и удаляться с другой. При использовании односвязного списка снятие с очереди будет выполняться с начала списка, а постановка в очередь ‑ в конец списка. Для двухсвязных списков для постановки или снятия с очереди может выбираться как начало, так и конец. Но в этом случае очередь будет требовать больший объем памяти. Очевидно, что обе операции с очередью не зависят от количества элементов в ней, т.е. они принадлежат к классу O(1).
Как и для класса TtdStack, код класса TtdQueue будет разрабатываться на основе главных принципов. Аргументы за использование такой схемы мы рассматривали во время написания кода для класса стека.
Листинг 3.26. Класс TtdQueue
TtdQueue = class private
PCount : longint;
FDispose : TtdDisposeProc;
FHead : PslNode;
FName : TtdNameString;
FTail : PslNode;
protected
procedure qError(aErrorCode : integer;
const aMethodName : TtdNameString);
class procedure qGetNodeManager;
public
constructor Create(aDispose : TtdDisposeProc);
destructor Destroy; override;
procedure Clear;
function Dequeue : pointer;
procedure Enqueue(aItem : pointer);
function Examine : pointer;
function IsEmpty : boolean;
property Count : longint read FCount;
property Name : TtdNameString read FName write FName;
end;
Как и ранее, конструктор Create проверяет, существует ли экземпляр диспетчера узлов, а затем распределяет с его помощью фиктивный начальный узел. Затем инициализируется специальный указатель FTail, который при создании указывает на начальный узел. Его содержимое будет меняться, чтобы он всегда указывал на последний узел связного списка. Это позволит легко вставлять новые элементы после конечного узла.
Листинг 3.27. Конструктор и деструктор для класса TtdQueue
constructor TtdQueue.Create(aDispose : TtdDisposeProc);
begin
inherited Create;
{сохранить процедуру удаления}
FDispose :=aDispose;
{получить диспетчер узлов}
qGetNodeManager;
{распределить и связать начальный и конечный узлы}
FHead := PslNode(SLNodeManager.AllocNode);
FHead^.slnNext := nil;
FHead^.sInData := nil;
{установить указатель конечного узла на начальный узел}
FTail := FHead;
end;
destructor TtdQueue.Destroy;
begin
{удалить все оставшиеся узлы; очистить начальный фиктивный узел}
if (Count <> 0) then
Clear;
SLNodeManager.FreeNode(FHead);
inherited Destroy;
end;
А теперь перейдем к методу Enqueue. Он посредством диспетчера узлов распределяет новый узел и устанавливает его указатель данных на вставляемый элемент. Затем используется указатель FTail. Учитывая, что он указывает на последний узел, мы вставляем новый узел за ним, после чего перемещаем указатель на одну позицию вперед ‑ на новый узел, который теперь стал последним.
Листинг 3.28. Метод Enqueue класса TtdQueue
procedure TtdQueue.Enqueue(aItem : pointer);
var
Temp : PslNode;
begin
Temp := PslNode(SLNodeManager.AllocNode);
Temp^.slnData := aItem;
Temp^.slnNext := nil;
{добавить новый узел в конец списка и переместить указатель конечного узла на только что вставленный узел}
FTail^.slnNext := Temp;
FTail := Temp;
inc(FCount);
end;
Метод Dequeue ничуть не сложнее. Сначала он проверяет список на наличие в нем элементов, а затем, пользуясь алгоритмом "удалить после" фиктивного начального узла FHead, удаляет из списка первый узел. Перед освобождением узла с помощью диспетчера узлов метод Dequeue возвращает данные. После выполнения метода количество элементов в списке уменьшается на единицу. Вот здесь и начинается самое интересное. Представьте себе, что из очереди снимается один единственный имеющийся в ней элемент. До выполнения операции Dequeue указатель FTail указывал на последний узел списка, который был одновременно и первым. После снятия элемента с очереди первый узел будет отсутствовать, но указатель FTail все еще указывает на него. Нам нужно сделать так, чтобы после удаления узла в списке FTail указывал на фиктивный начальный элемент. Если же в списке до удаления присутствовало несколько элементов, указатель будет указывать на действительный последний узел.
Листинг 3.29. Метод Dequeue класса TtdQueue
function TtdQueue.Dequeue : pointer;
var
Temp : PslNode;
begin
if (Count = 0) then
qError(tdeQueueIsEmpty, 'Dequeue');
Temp := FHead^.slnNext;
Result := Temp^.slnData;
FHead^.slnNext := Temp^.slnNext;
SLNodeManager.FreeNode(Temp);
dec(FCount);
{если после удаления элемента очередь опустела, переместить указатель последнего элемента на фиктивный начальный узел}
if (Count = 0) then
FTail := FHead;
end;
Остальные методы, Clear, Examine и IsEmpty, еще проще.
Листинг 3.30. Методы Clear, Examine и IsEmpty класса TtdQueue
procedure TtdQueue.Clear;
var
Temp : PslNode;
begin
{удалить все узлы за исключением начального; при возможности освободить все данные}
Temp := FHead^.slnNext;
while (Temp <> nil) do
begin
FHead^.slnNext := Temp^.slnNext;
if Assigned(FDispose) then
FDispose(Temp^.slnData);
SLNodeManager.FreeNode(Temp);
Temp := FHead^.slnNext;
end;
FCount := 0;
{теперь очередь пуста, установить указатель последнего элемента на начальный узел}
FTail := FHead;
end;
function TtdQueue.Examine : pointer;
begin
if (Count = 0) then
qError(tdeQueueIsEmpty, 'Examine');
Result := FHead^.slnNext^.slnData;
end;
function TtdQueue.IsEmpty : boolean;
begin
Result := (Count = 0);
end;
Полный код класса TtdQueue можно найти на Web‑сайте издательства, в разделе материалов. После выгрузки материалов отыщите среди них файл TDStkQue.pas.